

Zookeeper 快速理解
转自:http://blog.csdn.net/colorant/article/details/8444283
== 是什么 ==
目标Scope(解决什么问题)
为分布式系统提供高可靠性的协同工作机制
官方定义
ZooKeeper is acentralized service for maintaining configuration information, naming,providing distributed synchronization, and providing group services.
个人理解
基本上ZooKeeper提供了一个简化并支持特定功能的分布式文件系统接口,加上数据同步,变更通知,客户端Cache等辅助机制。基于这样的接口,用户可以自己在此之上构建逻辑,来实现各种分布式系统系统工作所需的各种功能,如配置管理,名称服务,Master选举,同步,锁等,类似于google的Chubby,但是没有内建锁的支持。
== 如何实现 ==
核心思路,架构
zookeeper的核心思想是提供一个非锁机制的Wait Free的用于分布式系统同步的核心服务,提供简单的文件创建读写操作接口,其系统核心本身对文件读写并不提供加锁互斥的服务,但是提供基于版本比对的更新操作,客户端可以基于此自己实现加锁逻辑。客户端可以连接任意zookeeper服务节点来读写数据,zookeeper内部会分为Leader和Follower角色。
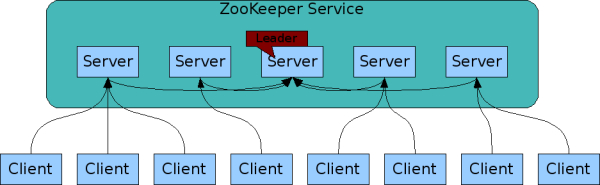
Zookeeper使用简单的同步策略,通过以下两条基本保证来实现数据的一致性:
- 全局串行化所有的写操作
- 保证同一客户端的指令被FIFO执行(以及消息通知的FIFO)
客户端尽可能通过Cache和消息通知机制来减少与服务器之间不必要的信息沟通,来减轻服务器负担
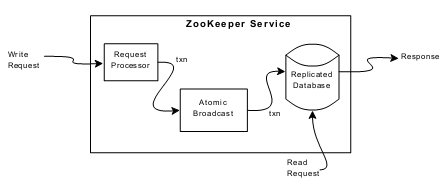
数据更新操作需要服务器Leader节点协同Slave节点通过ZAB协议(基本就是两阶段提交)进行全局广播来实现,因此随着Slave节点增加,性能是下降的。
数据读操作可以由任意服务器节点提供,如果不是Lead节点,读操作本身不保证数据是最新的,但是可以通过一个Sync(大概就是一个空的写操作)+read的模式来实现对最新数据的读取(由前述两条基本保证可推得)
Zookeeper自身文件系统维护在内存中,通过定期Snapshot和Log记录来实现灾难恢复
zookeeper对用户暴露简单的API接口,读写创建Znode数据节点,Znode节点分为普通节点和临时节点,零时节点当创建它的客户端连接结束/丢失以后会自动删除。API主要包括
Create : 创建node
Delete : 删除node
Exists : 判断node是否存在
get data : 读取node内存储的数据
set data : 向node写数据
get children : 获取一个node的子node列表
Sync : 等待数据更新的同步完成
适用领域
需要一个中心服务提供协同工作原语支持的分布式系统。能够将协同工作部分简单的剥离(或者添加)使用外部服务的场合。
细节
Snapshot创建时不Block数据更新操作,因此不保证精确再现zookepper某一个特定时间点的状态,不过由于串行化更新操作和数据更新的幂等特性,只要完整数量的LOG被顺序更新(可以重复),由非精确状态再现的Snapshot是可以恢复得到精确的最新状态的。
== 相关项目 ==
上下游项目
Hbase : 使用Zookeeper做Master选举等
Hadoop2.0 (YARN)
BookKeeper: Zookeeper内置项目,基于Zookeeper实现的一个Log记录系统
类似项目
chubby
== 相关文献 ==
项目主页
Paper 论文
ZooKeeper: Wait-freecoordination for Internet-scale systems
A simple totallyordered broadcast protocol


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· 用 C# 插值字符串处理器写一个 sscanf
· Java 中堆内存和栈内存上的数据分布和特点
· 开发中对象命名的一点思考
· .NET Core内存结构体系(Windows环境)底层原理浅谈
· 为什么说在企业级应用开发中,后端往往是效率杀手?
· DeepSeek 解答了困扰我五年的技术问题。时代确实变了!
· 本地部署DeepSeek后,没有好看的交互界面怎么行!
· 趁着过年的时候手搓了一个低代码框架
· 推荐一个DeepSeek 大模型的免费 API 项目!兼容OpenAI接口!