

HBase学习系列
转自:http://www.aboutyun.com/thread-8391-1-1.html
|
问题导读:
1.hbase是什么?
2.hbase原理是什么?
3.hbase使用中会遇到什么问题?
4.如何通过eclipse,操作hbase?
5.hbase经常和哪些软件一起使用?
。。。。。。。。。。
hbase从入门到编程
认识hbase 1.hbase简介 hbase我们或许已经知道了它是nosql,但是什么是nosql,我们不太清楚,nosql是一种基于列的数据库,而我们的传统数据库则是基于行的数据库。想对nosql进一步了解,参考Nosql数据库入门分享 HBase– Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。 <ignore_js_op>  HBase是GoogleBigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用HadoopHDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为对应。 更多内容参考: Hbase简介 http://www.aboutyun.com/thread-6138-1-1.html 2.hbase应用场景 我们知道了hbase是什么,那么我们什么时候使用。 当我们对于数据结构字段不够确定或杂乱无章很难按一个概念去进行抽取的数据适合用使用什么数据库?答案是什么,如果我们使用的传统数据库,肯定留有多余的字段,10个不行,20个,但是这个严重影响了质量。并且如果面对大数据库,pt级别的数据,这种浪费更是严重的,那么我们该使用是什么数据库?hbase数个不错的选择。更多内容参考: hbase常识及habse适合什么场景 http://www.aboutyun.com/thread-7073-1-1.html 3.hbase与传统数据的区别 我们整体了解了hbase,那么hbase与传统数据库到底有哪些区别,我们的增删改查,nosql有没有增删改查,答案是有的。下面我们以两个图来表示: 图1,是我们经常见到的传统数据,图2则是nosql数据库,从这个图中,或许我们知道了,nosql为什么被称之为基于列的数据库了。 想了解更多参考下面内容 图解Nosql(hbase)与传统数据库的区别 http://www.aboutyun.com/thread-7804-1-1.html hbase与传统数据的区别 http://www.aboutyun.com/thread-6720-1-1.html 图1传统数据库  图2:hbase数据库 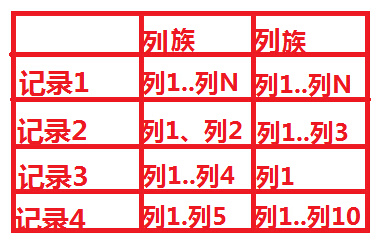 4.hbase与hadoop的关系 我们了解的越多,有时候问题就越多,hbase与hadoop是什么关系,有了hadoop,我们为什么使用hbase.这个有点像我们的磁盘与数据库,比如我们的把mysql或则sqlserver放到D盘一样。hadoop提供了介质,hbase存储在hdfs上,同理hive也是如此,对于hive这里不在详述,可以参考零基础学习hadoop到上手工作线路指导(中级篇)。hbase与hive及hadoop的关系,更详细参考下面帖子: hive与hbase的十大区别与联系 http://www.aboutyun.com/thread-7870-1-1.html 5.hbase术语及原理 hbase中出现了Region,RegionServer,ROOT- 和.META表, Region是HBase数据存储和管理的基本单位。一个表中可以包含一个或多个Region。每个Region只能被一个RS(RegionServer)提供服务,RS可以同时服务多个Region,来自不同RS上的Region组合成表格的整体逻辑视图。 HBase中有两张特殊的Table,-ROOT-和.META. META.:记录了用户表的Region信息,.META.可以有多个regoin ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region 当我们执行添加、删除数据的时候,相应的hbase的META,ROOT都会有相应的改变。 更多内容参考: HBase 各部件的作用 http://www.aboutyun.com/thread-5862-1-1.html hbase中什么是Region,什么是RegionServer? http://www.aboutyun.com/thread-7159-1-1.html HBASE原理简述 http://www.aboutyun.com/thread-7199-1-1.html hbase部署 我们掌握理论知识,并不是真正的认识,因为计算机是一门实践学科,下面我们开始部署hbase,什么是部署,这里是安装的意思,因为Linux的安装软件与window有所区别的,所以对于刚接触Linux的同学,在部署方面还需要花不少功夫的。 hbase的部署分为单机部署及集群部署,建议采用集群部署,在部署hbase之前,需要安装hadoop。部署文档可以参考: hbase 0.96整合到hadoop2.2三个节点全分布式安装高可靠文档 http://www.aboutyun.com/thread-7746-1-1.html 在部署的时候,需要注意hadoop版本与hbase的版本匹配。 更多内容,可参考下面: HBASE分布式安装视频下载分享http://www.aboutyun.com/thread-6612-1-1.html Hbase单节点部署及其基础使用 http://www.aboutyun.com/thread-7677-1-1.html HBASE分布式安装视频下载分享 http://www.aboutyun.com/thread-6612-1-1.html hadoop、hbase、hive版本对应关系 http://www.aboutyun.com/thread-7295-1-1.html hbase与zookeeper可以说是不可分离的,因此hbase有自带的zookeeper,如果不使用自带zookeeper,可以禁用zookeeper,使用外部zookeeper。 Hbase禁用自带ZooKeeper,使用已经安装的ZooKeeper http://www.aboutyun.com/thread-7451-1-1.html 上面我们完成基本的配置,在后面的使用过程中,我们对集群的要求增高,所以我们就会需要了解更多的配置项的作用,下面帖子可以参考。 hbase配置项说明 HBase 默认配置说明(收藏版) http://www.aboutyun.com/thread-7914-1-1.html Hbase配置项粗解(1) http://www.aboutyun.com/thread-8274-1-1.html Hbase配置项粗解(2) http://www.aboutyun.com/thread-8275-1-1.html Hbase配置项粗解(3) http://www.aboutyun.com/thread-8276-1-1.html 其他: hbase-0.94.10.tar.gz包下载 http://www.aboutyun.com/thread-6114-1-1.html hadoop_HBase安装,数据分析与建模,实战案例剖析 http://www.aboutyun.com/thread-5146-1-1.html Ganglia监控Hadoop及Hbase集群性能(安装配置) http://www.aboutyun.com/thread-8129-1-1.html 更多的jar包、安装包 hadoop家族、strom、spark、Linux、flume等jar包、安装包汇总下载(持续更新) hbase整合 hbase不是单独存在的,hbase可以与hive、Impala、Flume整合。我们为什么要整合?比如我们hbase、hive整合之后,当我们将数据插入hbase之后,hive随之同步,我们无须操作hive,这就是整合的好处。对于flume整合,当flume整合搜集到数据之后,会自动发送到hbase,这样省去了我们很多的功夫去编程。我们只需要关心我们的业务逻辑即可。 hive与hbase整合原理介绍 http://www.aboutyun.com/thread-7824-1-1.html 阐述: 1.Hive与hbase整合的原理? 2.Hive与hbase整合后的使用场景? 3.Hive与hbase整合后的使用方法? hive为什么与hbase整合 http://www.aboutyun.com/thread-7317-1-1.html 阐述: 1.hive为什么与hbase整合? 2.hive整合hbase的优缺点是什么? hbase 0.96整合到hadoop2.2三个节点全分布式安装高可靠文档(推荐) http://www.aboutyun.com/thread-7746-1-1.html 此文档详细介绍了hbase 0.96整合到hadoop2.2整合的步骤及遇到的相关问题 Impala与HBase整合实践 http://www.aboutyun.com/thread-7856-1-1.html 编译和使用hive与HBase通信包--hive-hbase-handler.jar及下载 http://www.aboutyun.com/thread-7817-1-1.html 阐述: 1.hive与hbase对应版本
2.hive-hbase-handler.jar在于hbase、hive中起的作用是什么?
3.hive-hbase-handler.jar是否有版本之分,不同版本是否都能使用这个包来整合hbase与hive?
4.整合过程中hive-hbase-handler.jar应该放在hive的哪个文件夹中?
hbase0.96与hive0.12整合高可靠文档及问题总结 http://www.aboutyun.com/thread-7881-1-1.html 阐述下面问题: 1.hive安装是否需要安装mysql? 2.hive是否分为客户端和服务器端? 3.hive的元数据库有哪两种? 4.hive与hbase整合的关键是什么? 5.hive的安装是否必须安装hadoop? 6.hive与hbase整合需要做哪些准备工作?7.hive元数据库启动卡住代表的含义是什么? Flume-ng将数据插入hdfs与HBase-0.96.0 http://www.aboutyun.com/thread-7912-1-1.html 阐述下面问题: 1.如何配置分布式flume 2.master与node之间该如何配置,有什么异同? 3.启动命令是什么? 4.flume把数据插入hbase,该如何配置? hive0.13调整hbase 0.96.2 hadoop2.2.0 问题总结 http://www.aboutyun.com/thread-7893-1-1.html 阐述下面问题: 1.hive.aux.jars.path参数的作用是什么? 2.Job Submission failed with exception 'java.io.FileNotFoundException'这个问题该如何解决? Flume-1.4.0和Hbase-0.96.0整合实践 http://www.aboutyun.com/thread-7418-1-1.html 阐述下面问题: 1.需要修改那些文件? 2.如何测试整合成功? 3.兼容问题该如何解决? Flume-0.9.4和Hbase-0.96整合实践 http://www.aboutyun.com/thread-7417-1-1.html 阐述下面问题: 1.都需要修改那些文件? 2.为什么修改这些文件? 3.代码有的地方需要改动,猜测原因什么? hbase使用 上面讲了很多,从理论到实践安装,我们终于可以使用了,我们很想尝试增删改查到底是什么样子的? 我们可以安装下面格式,来操作:
这里举个具体例子: 1.创建一个表 hbase(main):011:0>create 'member','member_id','address','info' 0 row(s) in 1.2210seconds 2.drop一个表 hbase(main):029:0>disable 'temp_table' 0 row(s) in 2.0590seconds 更详细参考下面帖子: HBase Shell常用命令 http://www.aboutyun.com/thread-6151-1-1.html 上面是基本的操作,使用的时间越长,我们的需求就会越多,比如删除数据会遇到region不释放,我们想备份数据、定期删除数据,压缩数据、查询优化等更详细内容查看下面帖子: HBase如何实现多条件查询 http://www.aboutyun.com/thread-6685-1-1.html 开启hadoop和Hbase集群的lzo压缩功能 http://www.aboutyun.com/thread-8349-1-1.html 阐述问题: 1.如何启动hadoop、hbase集群的压缩功能? 2.lzo的作用是什么? 3.hadoop配置文件需要做哪些修改? HBase实现记录定期定量删除 http://www.aboutyun.com/thread-8307-1-1.html 阐述问题: 1、如何定期删除数据? 2、如何在数据超过阈值时删除数据? hbase数据删除不释放region解决办法 http://www.aboutyun.com/thread-8306-1-1.html 阐述问题: 1.删除hbase数据有几种方法? 2.删除数据,region不释放,你认为该如何解决? HBase 利用Coprocessor实现聚合函数 http://www.aboutyun.com/thread-7840-1-1.html 阐述问题: 1、HBase默认不支持聚合函数,那我们该用什么来实现呢 ? 2、怎么用编程的方式去实现呢 ? 大数据应用之HBase数据插入性能优化之多线程并行插入测试案例 http://www.aboutyun.com/thread-8011-1-1.html 阐述问题: 1、单线程下HBase的插入性能如何? 2、如何在多线程下了解HBase的性能? hbase与hadoop2.X在CentOS6.4下源码编译 http://www.aboutyun.com/thread-7150-1-1.html 阐述问题: hadoop2.2.0编译需要注意什么问题? HBase部署的时候需要注意什么问题? HBase0.96.0编译前需要使用什么为相应的版本生成pom文件? hbase meta表修复方式总结 http://www.aboutyun.com/thread-7998-1-1.html 阐述问题: 1.hbase hbck -fixMeta的作用是什么? 2.如何重新将hbase meta表分给regionserver? 3.出现region的hole该如何修复? 优化hbase的查询优化-大幅提升读写速率 http://www.aboutyun.com/thread-7657-1-1.html 阐述问题: 1.本文通过什么方法优化查询效率的? 2.如何增大RPC数量? 3.如何调整hbase内存? hadoop及hbase的超时设置 阐述问题: http://www.aboutyun.com/thread-7552-1-1.html 1.hadoop超时,该如何设置超时时间? 2.hbase超时时间限制,该如何设置? 优化hbase的查询提升读写速率优化案例及性能提升的几种方法 http://www.aboutyun.com/thread-7468-1-1.html 阐述问题: 1.完全发挥不出hbase的效率的原因是什么? -------------------------------- 2.使用bloomfilter和mapfile_index_interval如何提升性能? 3.如何设置hbase的内存? 4.如何增大RPC的数量? 扩展: 5.为什么HBase是基于列模式的存储? Hbase数据备份和恢复 http://www.aboutyun.com/thread-7296-1-1.html hbase工具 所谓工具就是帮助我们的,hbase工具,则是帮助我们使用hbase,phoenix的作用是什么? phoenix的操作sql是通过jdbc发送到HBase的。phoenix的查询语句会转化为hbase的scan操作和服务器端的过滤器。如果我们手工使用HBase的api去写这些代码,也会得到相同的运行结果和执行速度。但是,使用phoenix的效果却会带来更快的开发效率。 更多详细内容,见下面帖子: hbase的sql操作的框架-phoenix http://www.aboutyun.com/thread-6688-1-1.html hbase有哪些可视化工具,图形界面管理工具 http://www.aboutyun.com/thread-6257-1-1.html phoenix实战(hadoop2、hbase0.96) http://www.aboutyun.com/thread-8208-1-1.html Phoenix介绍:实现向HBase发送标准SQL语句 http://www.aboutyun.com/thread-8153-1-1.html hbase设计 hbase设计这个是一个比较大的话题,很多都是根据自己项目的具体情况来设计,这里只是简单说一下设计中需要注意的问题 1.防止数据倾斜 2.性能提升 防止数据倾斜,rowkey的设计还是比较关键的。 性能提升,在设计之初,将要查询的字段组合到rowkey中,否则后期可能查询是一个问题。更多详细内容参考下面帖子。 Hbase初步入门-- 表该如何构造和设计 http://www.aboutyun.com/thread-7828-1-1.html HBase设计 http://www.aboutyun.com/thread-5903-1-1.html hbase之rowkey的设计讨论 http://www.aboutyun.com/thread-8171-1-1.html HBase的rowkey设计 http://www.aboutyun.com/thread-7119-1-1.html hbase数据快速备份:HBase snapshot分析 http://www.aboutyun.com/thread-8038-1-1.html 修复hbase元数据.meta.表空洞的问题 http://www.aboutyun.com/thread-7894-1-1.html hbase Balancer 源码分析-负载均衡 http://www.aboutyun.com/thread-7643-1-1.html HBase Bug 知多少 http://www.aboutyun.com/thread-7135-1-1.html hbase编程 hbase分为两种是一种开发API,就是所谓的二次开发,一种是客户端API,也就是我们使用hbase来完成一些事情。对于hbase源码获取,我们需要具备maven知识,同hadoop获取源码的方式是一样的,具体可以参考:从零教你如何获取hadoop2.4源码并使用eclipse关联hadoop2.4源码. 通过eclipse获取源码之后,我们会看到一些maven语法错误,如果遇到execution错误,可以参考下面帖子。 hbabise、hadoop通过eclipse m2e maven插件获取源码产生execution错误解决方案 http://www.aboutyun.com/thread-8353-1-1.html 我们获取源码是为了查看更好的使用hbase,hbase的基本操作,在shell中能够完成,我们通过Java API eclipse环境同样能完成。除了增删改查、分页之外,我们还可以开发插件。 首先hbase开发,我们需要搭建开发环境: hbase开发环境搭建及运行hbase小实例(HBase 0.98.3新api) hbase编程:Eclipse远程连接创建hbase表以及填充列与列数据 开发环境有了,后面的操作参考: hbase-0.90.2中创建表、插入数据,更新数据,删除数据实例 http://www.aboutyun.com/thread-7496-1-1.html Java操作hbase编程 http://www.aboutyun.com/thread-7075-1-1.html spark使用java读取hbase数据做分布式计算 http://www.aboutyun.com/thread-8242-1-1.html hbase编程:通过Java api操作hbase http://www.aboutyun.com/thread-7151-1-1.html hbase HTable之Put、delete、get等源码分析 http://www.aboutyun.com/thread-7644-1-1.html Hbase Java编程实现增删改查 http://www.aboutyun.com/thread-6901-1-1.html 总结Eclipse 远程连接 HBase问题及解决方案大全 http://www.aboutyun.com/thread-5866-1-1.html HBase中如何开发LoadBalance插件 http://www.aboutyun.com/thread-8350-1-1.html Hbase与eclipse集成的第一个例子 http://www.aboutyun.com/thread-7837-1-1.html hbase分页应用场景及分页思路与代码实现 http://www.aboutyun.com/thread-7030-1-1.html HBase MapReduce排序Secondary Sort http://www.aboutyun.com/thread-7304-1-1.html CDH4源码搭建hbase开发环境 http://www.aboutyun.com/thread-7259-1-1.html Thrift了解4:C#通过Thrift操作HBase实战 http://www.aboutyun.com/thread-7142-1-1.html hbase API hadoop2.2.0帮助手册下载API及HBase 0.98.1-hadoop2 API http://www.aboutyun.com/thread-6113-1-1.html HBase数据迁移(1)-使用HBase的API中的Put方法 http://www.aboutyun.com/thread-8336-1-1.html hbase编程:Java API连接Hbase进行增删改查讲解实例 http://www.aboutyun.com/thread-8290-1-1.html hbase问题 hbase使用和开发过程中会遇到各种问题,比如插入数据越来越慢,master启动之后又挂掉,hbase如何存储图片,线上regionserver无缘无故下线,这里整理了一下。 hive-hbase整合后查询缓慢 http://www.aboutyun.com/thread-7935-1-1.html hbase插入数据,为什么速度越来越慢 http://www.aboutyun.com/thread-6564-1-1.html hbase排错:be reached after 1 tries, giving up. http://www.aboutyun.com/thread-6579-1-1.html hbase master启动了又挂了 http://www.aboutyun.com/thread-5882-1-1.html hbase配置、运行错误总结 http://www.aboutyun.com/thread-8319-1-1.html hbase删除数据的问题 http://www.aboutyun.com/thread-8304-1-1.html hbase和hive整合问题 http://www.aboutyun.com/thread-8227-1-1.html HBase如何把图片存进去呢? http://www.aboutyun.com/thread-8219-1-1.html hbase编写自定义count功能的问题 http://www.aboutyun.com/thread-8191-1-1.html 请问hbase如何设置region大小啊 http://www.aboutyun.com/thread-7974-1-1.html hbase regionserver下线 http://www.aboutyun.com/thread-8138-1-1.html hbase伪分布式是不是没有regionserver啊 http://www.aboutyun.com/thread-8158-1-1.html hbase的“-ROOT-”表所在的block丢失,该如何恢复 http://www.aboutyun.com/thread-7988-1-1.html hbase插入数据,出现java.lang.OutOfMemoryError http://www.aboutyun.com/thread-7896-1-1.html hive0.13与hbase0.98.2通过向Hbase表中导数据出现的错 http://www.aboutyun.com/thread-7892-1-1.html hbase编程如何获取动态列 http://www.aboutyun.com/thread-7763-1-1.html 获取源码遇到问题解决方案: hbase、hadoop通过eclipse m2e maven插件获取源码产生execution错误解决方案 http://www.aboutyun.com/thread-8353-1-1.html 解决问题的根本 hbase日志 Hadoop和Hbase重要日志位置 http://www.aboutyun.com/thread-6106-1-1.html hbase在大企业应用 我们在使用hbase的过程中,我们所遇到的问题,走过的路,或许别人已经遇到并且解决,对于阿里、360、Facebook等大公司是走在我们前面的,下面的一些经验可以借鉴。 hbase在360的应用及使用过程中遇到的问题及解决方案 http://www.aboutyun.com/thread-8298-1-1.html阐述问题: 1.360为什么使用hbase? 2.调用Put接口写入数据,写入性能丌高效的原因是什么?该如何解决? 3.bulkImport的数据导入阶段较慢原因是什么? 4.bulkImport后,compaction操作会产生大量IO原因是什么?该如何解决? HBase在淘宝主搜索的Dump中的性能调优 http://www.aboutyun.com/thread-8285-1-1.html 阐述问题: 1.hbase在运用中,如何有效降低延时?
2.如何对Dump进行性能调优?
淘宝搜索分析系统Pora2的应用之HBase高并发读写性能优化 http://www.aboutyun.com/thread-8025-1-1.html 阐述问题: 1、如何理解淘宝的搜索分析系统Pora? 2、redis超时的原因有哪些? Facebook使用HBase构建实时信息系统:能每月存储1350亿条信息 http://www.aboutyun.com/thread-7499-1-1.html 阐述问题: 1.Facebook为什么选择hbase? 扩展: 2.hbase为什么被称之为面向列的数据库? 3.hbase为什么能能承受如此多的数据? 淘宝之HBase MapReduce实例分析 http://www.aboutyun.com/thread-7072-1-1.html 阐述问题: 1.hbase MapReduce那么它和hadoop的MapReduce有什么异同? 2.hbase MapReduce基本模型是什么? 3.对于InputFormat和OutputFormat二者的作用是什么? 4.HBase通过对哪些类的扩展(继承)来方便MapReduce任务来读写HTable中的数据? 5.HBase中Mapper类继承哪个类? 6.HBase中Reducer类继承哪个类? 7.HBase在提交作业时设置inputFormat成什么?outputFormat设置成什么? 8.HBase中TableMapReduceUtil类的作用是什么? 淘宝hbase业务实践 http://www.aboutyun.com/thread-7031-1-1.html 阐述问题: 1.HTablePool与传统数据块连接池那个对应? 2.通过那个函数可以释放连接池? 3.habse在什么情况下会比较慢? 4.RowKey该如何设计? HBase在内容推荐引擎系统中的一些问题 http://www.aboutyun.com/thread-7147-1-1.html 阐述问题: 1.随机读取性能成倍下降的原因是什么? 2.Snappy压缩是为解决hbase什么问题? 3.原生HBase最大的问题之一就是数据随机读写速度太慢,该如何解决这个问题? 4.一个服务器宕机,其服务器的数据,做如何处理? 5.HBase需要通过Compaction解决什么问题? 6.Region Server假死或则退出,会造成什么情况? 淘宝为什么使用HBase及如何优化的 http://www.aboutyun.com/thread-6940-1-1.html 阐述问题: 1.大数据量,而且数据增量不可预测,采用什么方案比较合适? 2.hbase有什么优点和缺陷? 3.hbase采用什么模型保证数据不丢失? 4.hbase的Meta表损坏以及split方面的bug会造成什么情况? 5.什么情况下会关闭jobtracker? 6.淘宝为了保障服务从结果上的可用,都采取了什么措施? 7.hbase中split为什么存在风险? HBase工程师线上工作经验总结----HBase常见问题及分析 http://www.aboutyun.com/thread-6929-1-1.html 阐述问题: 1.HBase遇到问题,可以从几方面解决问题? 2.HBase个别请求为什么很慢?你认为是什么原因? 3.客户端读写请求为什么大量出错?该从哪方面来分析? 4.大量服务端exception,一般原因是什么? 5.系统越来越慢的原因是什么? 6.Hbase数据写进去,为什么会没有了,可能的原因是什么? 7. regionserver发生abort,遇到最多是什么情况? 8.从哪些方面可以判断HBase集群是否健康? 9.为了加强HBase的安全性,你会采取哪些措施? HBase在搜狐内容推荐引擎系统中的应用 http://www.aboutyun.com/thread-7297-1-1.html Facebook针对hbase的优化方案分析 http://www.aboutyun.com/thread-7180-1-1.html 附上API 开发者API hbase api http://hbase.apache.org/devapidocs/index.html 用户api HBase 0.99.0-SNAPSHOT API http://hbase.apache.org/apidocs/index.html 相关篇章推荐: 零基础学习hadoop到上手工作线路指导(初级篇) 零基础学习hadoop到上手工作线路指导(中级篇) 零基础学习hadoop到上手工作线路指导(编程篇) |

