pandas 操作excel实现筛选重复行/模糊检索
class excleOPen(QtWidgets.QMainWindow, Ui_MainWindow):
def __init__(self, parent=None, *args, **kwargs):
super().__init__(parent, *args, **kwargs)
self.setupUi(self)
def excel_open(self):
# 使用pyqt5,选择将要打开的excel文件
result = QFileDialog.getOpenFileName(self, "选择一个excel文件", "./", "excel(*.xls *.xlsx)")
fileName = result[0]
# 用文本框显示将要打开的文件路径
self.lineEdit.setText(fileName)
df = pd.read_excel(fileName, index_col='ID')
# 将重复项全部删除
data_no_duplicates = df.drop_duplicates(subset='name', keep=False)
# 只保留第一个重复行
data_first_duplicates = df.drop_duplicates(subset='name', keep='first')
# 无重复项的集合与只留第一个的集合的差集,即重复行
data_duplicate = data_first_duplicates.append(data_no_duplicates).drop_duplicates(keep=False)
# 显示所有重复行,查看重复的数据,做到心中有数
data_duplicates = data_no_duplicates.append(df).drop_duplicates(keep=False)
# 下面两行构建新的excel的路径
OldFileName = fileName.split('.x')
NewFileName = OldFileName[0]+ '_new.x' + OldFileName[1]
# 下面这一行生成新的excel
# data_first_duplicates.to_excel(NewFileName)
# 查找功能实现
screen = df.loc[df['name'].str.contains('四')]
print(screen)
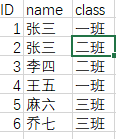
excel原型:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号