centos7安装flink(local,standallone,yarn)
下面flink部署模式默认是session模式,flink还有per-job,application两种部署模式
部署模式:flink里面的 计算程序 运行模式
运行模式:flink软件运行的模式
具体区别查看:https://www.cnblogs.com/cxygg/p/18068491
下面的三种是flink运行模式
local模式
本地模式只需要一台服务
环境说明,flink需要jdk,并且flin.2k1.17,需要的是jdk11,jdk17不行,实测jdk1.8也行
-
下载flink包
wget https://dlcdn.apache.org -
解压
#解压 tar -zxvf flink-1.17.2-bin-scala_2.12.tgz #进入flink目录 cd flink-1.17.2 -
修改配置文件
vi conf/flink-conf.yaml
#允许远程访问管理界面,如果你的flink安装在虚拟机里面,默认外面物理机是无法访问的 rest.bind-address: 0.0.0.0 -
启动和关闭
#启动 ./bin/start-cluster.sh #关闭 ./bin/stop-cluster.sh -
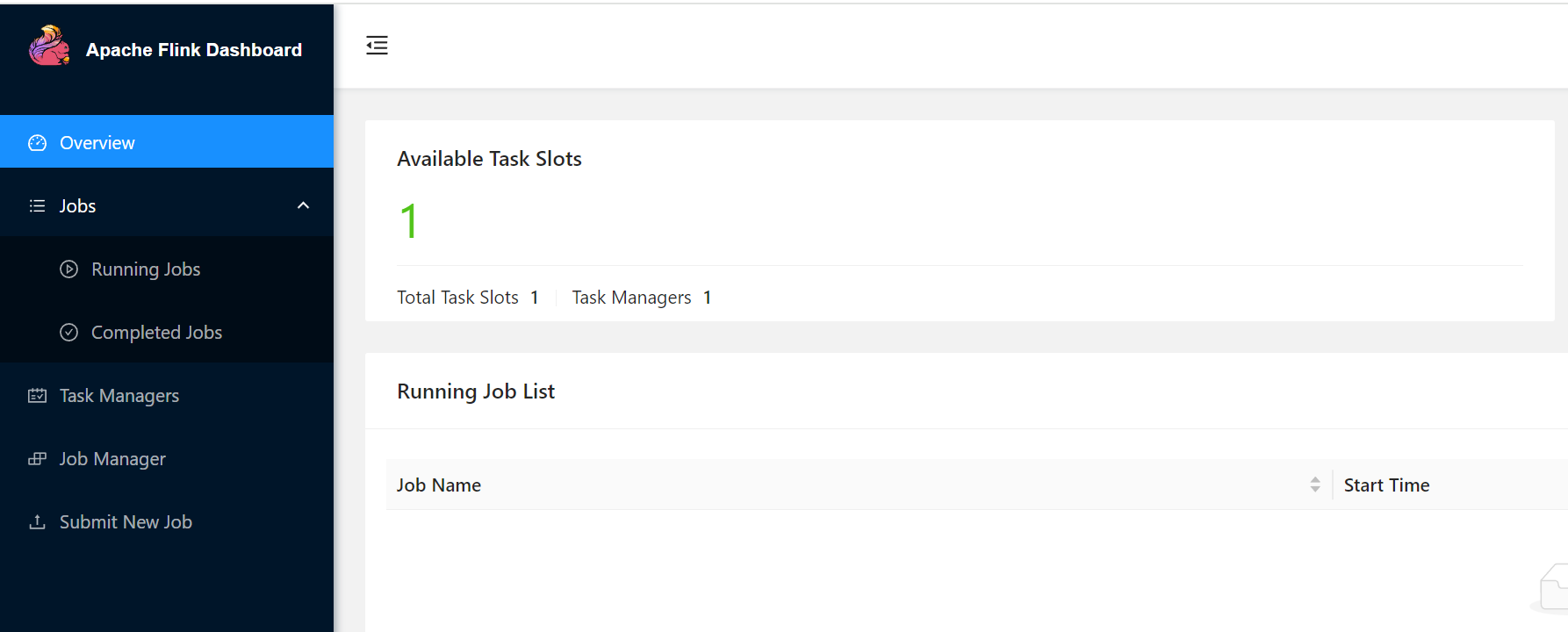
查看flink管理界面
不配置第3步是默认不能远程访问的
浏览器访问:http://192.168.100.66:8081/
![image-20240311183632794]()
-
进程查看
TaskManagerRunner和StandaloneSessionClusterEntrypoint 是 flink的进程
别的进程是 hadoop的这里用不着,无视[hadoop@vm200 bin]$ jps -l 1939 org.apache.hadoop.hdfs.server.namenode.NameNode 2484 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager 16473 org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint 2218 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 16779 org.apache.flink.runtime.taskexecutor.TaskManagerRunner 17181 sun.tools.jps.Jps
Standallone
独立部署模式需要多台服务器,不依赖hadoop
环境说明,flink需要jdk,并且flin.2k1.17,需要的是jdk11,jdk17不行,实测jdk1.8也行
三台主机已经相互配置了免密登录
节点分布
| 主机名 | ip | 节点类型 |
|---|---|---|
| vm200 | 192.168.1.200 | master |
| vm201 | 192.168.1.201 | work |
| vm202 | 192.168.1.202 | work |
-
下载flink包
wget https://dlcdn.apache.org -
解压
#解压 tar -zxvf flink-1.17.2-bin-scala_2.12.tgz #进入flink目录 cd flink-1.17.2 -
修改配置文件
vi conf/flink-conf.yaml#指定jobmanger的位置 jobmanager.rpc.address: vm200 #默认是localhost,这样taskmanger 是不能访问到 jobmanger的,管理界面的Available Task Slots 会是0 jobmanager.bind-host: 0.0.0.0 #允许远程访问管理界面,如果你的flink安装在虚拟机里面,默认外面物理机是无法访问的 rest.bind-address: 0.0.0.0vi works
写入从从节点ip或者主机名vm201 vm202 -
复制到从节点
scp -r /opt/flink-1.17.2/ vm201:/opt scp -r /opt/flink-1.17.2/ vm202:/opt -
启动(seesion模式)
#启动 ./bin/start-cluster.sh #关闭 ./bin/stop-cluster.sh -
查看flink管理界面
浏览器访问:http://192.168.100.66:8081/如果taskslot是0,那么就是jobmanager.bind-host还是默认配置localhost,taskmanger请求不过来
![image-20240311181318058]()
![image-20240311181402643]()
-
节点进程查看
-
vm200
StandaloneSessionClusterEntrypoint 就是 fink的进程,另外三个是hadoop和yarn的,Standallone 模式用不到[hadoop@vm200 conf]$ jps -l 1939 org.apache.hadoop.hdfs.server.namenode.NameNode 2484 org.apache.hadoop.yarn.server.resourcemanager.ResourceManager 3685 org.apache.flink.runtime.entrypoint.StandaloneSessionClusterEntrypoint 2218 org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode 10779 sun.tools.jps.Jps -
vm201
TaskManagerRunner是flink 的任务进程[hadoop@vm201 root]$ jps -l 2369 sun.tools.jps.Jps 2243 org.apache.flink.runtime.taskexecutor.TaskManagerRunner 1723 org.apache.hadoop.yarn.server.nodemanager.NodeManager 1598 org.apache.hadoop.hdfs.server.datanode.DataNode -
vm202
TaskManagerRunner是flink的任务经常[hadoop@vm202 root]$ jps 1616 DataNode 2309 Jps 2168 TaskManagerRunner 1741 NodeManager
-
-
提交作业
flink run 提交作业
-m 指定jobManger的地址
-c 指定程序入口,后面更是jar地址./flink run -m vm200:8081 -c org.apache.flink.streaming.examples.wordcount.WordCount ../examples/streaming/WordCount.jar

Flink on Yarn
yarn 模式依赖 haddop,flink程序本身不用启动,依赖yarn来启动fink集群。
-
安装hadoop集群
-
配置好hadoop集群
需要配置HADOOP_HOME,环境变量PATH,HADOOP_CONF_DIR,HADOOP_CLAAPATH#hadoop(环境变量) export HADOOP_HOME=/opt/hadoop-3.3.6 export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH #这两个是flink需要的,flink获取找hadoop的配置文件和classpath export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop #`hadoop classpath` 用``包裹的hadoop命令,效果和直接在命令行敲hadoop classpath得到的返回值复制给HADOOP_CLASSPATH一样 export HADOOP_CLASSPATH=`hadoop classpath` -
使用yarn-session.sh -d 启动一个集群
yarn-session.sh -d 后台启动一个集群
-nm 指定程序名字(name的缩写)
./yarn-session.sh --help 可以看到其他参数用法#向yarn请求创建一个名字是 test1的 fink集群,flink部署模式是session 模式 ./flink-1.17.2/bin/yarn-session.sh -d -nm test1 -
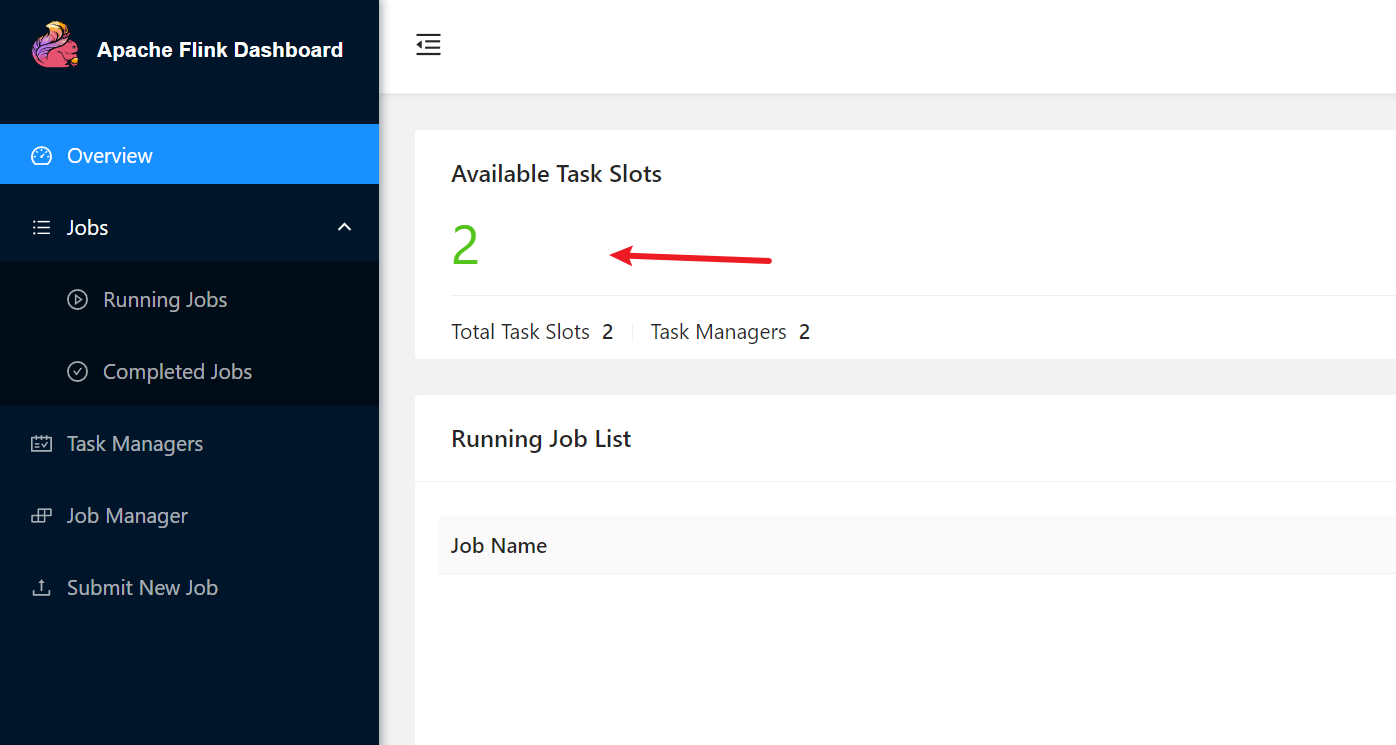
查看yarn管理的flink程序
![image-20240312102704000]()
-
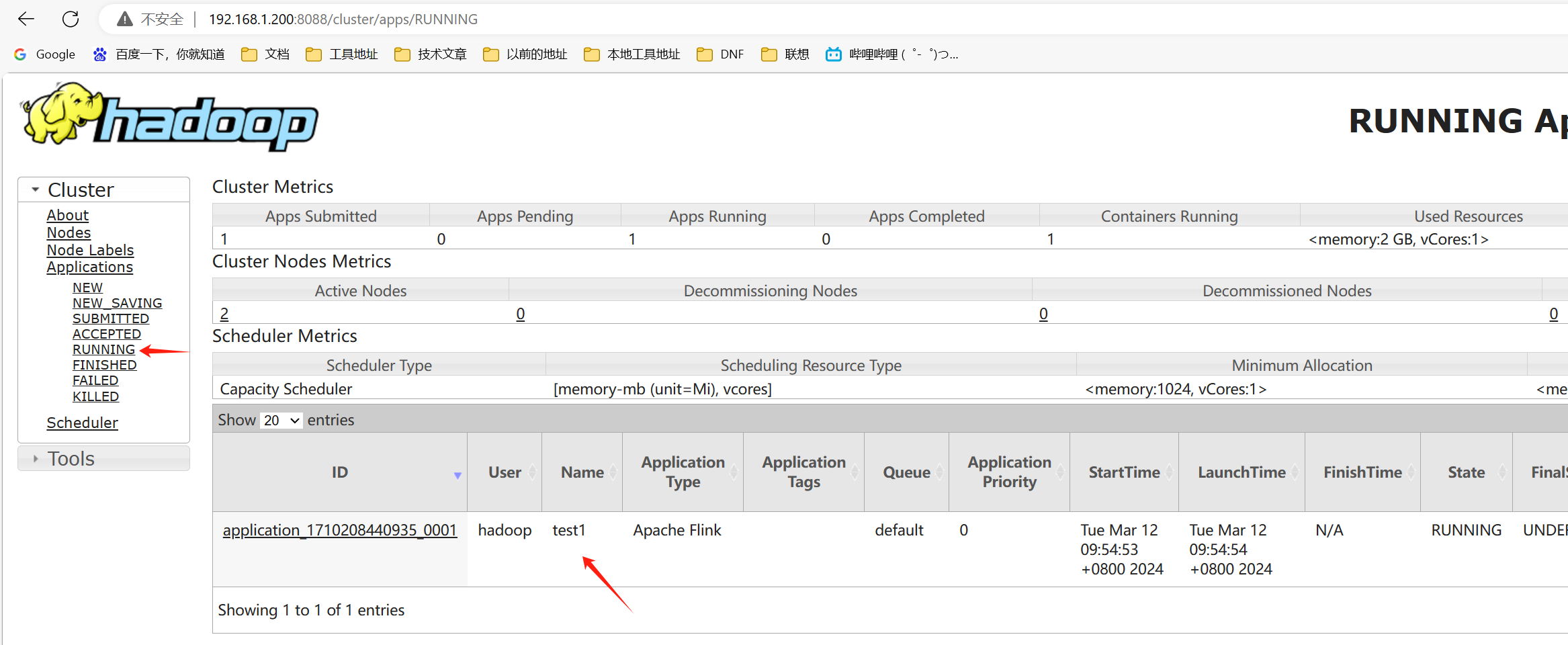
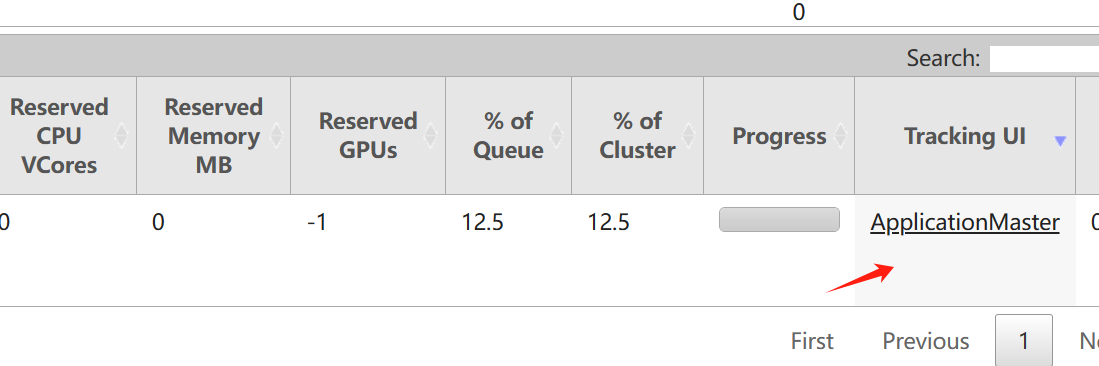
末尾的Tracking UI 可以进入 flink 管理界面
这个界面是走的代理,不是直接访问的![image-20240312102934564]()
-
启动 flink程序的时候控制台也有输出flink web ui的地址
2024-03-11 21:54:54,064 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Deploying cluster, current state ACCEPTED 2024-03-11 21:55:00,890 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully. 2024-03-11 21:55:00,890 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface vm202:38095 of application 'application_1710208440935_0001'. JobManager Web Interface: http://vm202:38095 2024-03-11 21:55:01,137 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command: $ echo "stop" | ./bin/yarn-session.sh -id application_1710208440935_0001 If this should not be possible, then you can also kill Flink via YARN's web interface or via: $ yarn application -kill application_1710208440935_0001 Note that killing Flink might not clean up all job artifacts and temporary files. -
优雅关闭flink
启动的时候输出的日志中不仅仅有 webUI 地址还有,关闭命令
echo "stop" | ./bin/yarn-session.sh -id appId
appId 可以去 yarn 里面查询如果直接敲 ./yarn-session.sh -id application_1710208440935_0001 stop 然后再ctrl+c强制退出也行
echo "stop" | ./bin/yarn-session.sh -id application_1710208440935_0001 -
非优雅关闭可以直接去hadoop管理界面直接kill application
-
提交作业
使用 fink run 提交作业
-c 指定 main class 后面更是jar包路径
对比独立部署模式少了指定 jobManger的参数./flink run -c org.apache.flink.streaming.examples.wordcount.WordCount ../examples/streaming/WordCount.jar
启动历史服务器
vi flink-conf.yaml
修改下面配置,然后分配到所有节点
历史服务器刷新速度很慢,读取日志时间间隔好像没生效,或者是别的参数控制
#==============================================================================
# HistoryServer
#==============================================================================
#jobmanger文件存储位置(目录需要提前是hdfs创建)
jobmanager.archive.fs.dir: hdfs://vm200:9000/flinkHistory/historyserver
#jobmanger部署地址
historyserver.web.address: vm200
#jobmanger端口
historyserver.web.port: 8082
#历史文件存储位置
historyserver.archive.fs.dir: hdfs://vm200:9000/flinkHistory/historyserver
#读取日志时间间隔
# Interval in milliseconds for refreshing the monitored directories.
historyserver.archive.fs.refresh-interval: 10000
启动历史服务器
#启动
./historyserver.sh start
#关闭
./historyserver.sh start
flink其他部署模式
yarn模式下支持sessionper-job,application三种部署模式
standalone支持 session 和 application模式
yarn模式下部署单作业模式flink和应用模式flink集群
应用模式和单作业模式都是提交任务才启动fink集群的,所以直接在提交任务的之后指定运行模式就行
应用模式
./flink run-application -t yarn-application -c 全类名 xxx.jar
-t 指定部署模式
#提交作业
./flink run-application -t yarn-application -c org.apache.flink.streaming.examples.wordcount.WordCount ../examples/streaming/WordCount.jar
单作业模式:
#提交作业(提交作业会创建一个新的flink集群)
./flink run -t yarn-per-job -c 全类名 xxx.jar
#查看运行的作业(输出日志的最后面)
./flink list -t yarn-per-job -Dyarn.application.id=xxx
#关闭作业(或者直接去flink webUI上关闭)
./flink cancel -t yarn-per-job -Dyarn.application.id=xxx jobId
standallone模式下
应用模式
需要手动分别启动jobManger和taskmanger
启动jobManger(在主节点启动)
需要jar包位于lib目录下面
#启动
./standalone-job.sh --job-classname 主类名
#关闭
./standalone-job.sh stop
从节点上启动
#启动
./taskmanger.sh start
#关闭
./taskmanger.sh stop
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2024-03-11 21:33 zhangyukun 阅读(943) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号