

flink总结
基本概念介绍
-
flink的基本处理流程
读取数据( source)->各种算子计算处理数据(rdd)-->输出数据(sink) -
有界流和无界流
如果是从文件之类有限数据的地方读取数据就是有界流,如果是接到kafka或者socket这种就是无界流。 -
有状态和无状态
算子计算的过程中,是否要保存中间结算结果,如果保存就是有状态。
比如 map 输出一个数据得到一个新的数据,不需要保存无状态,比如max 每次需要保存当前最大值,这是有状态的计算。 -
并行度
flink的并行度类似任务最多可以拆分成几个子任务,子任务各自执行。主任务会被分成小于等于并行度份子任务执行。默认并行度是cpu 线程数量,可以在运行是指定,环境上全局指定,或者单个算子上指定并行度。 -
任务槽(solt)
任务槽式运行任务的最小单元,是一份硬件资源集合,一个taskManger默认一个slot,可以指定多个,多个slot平分内存,然后根据并行度和slot个数计算出taskmanger的数量。 -
任务槽共享组
同一个job中,不同算子可以共享slot。并且他们是并行的。
slotSharingGroup("group001")SharingGroup相同的两个算子会共享一个slot,并且并行执行,默认是default
实测slotSharingGroup("group001") 不执行的问题,本地环境是模拟的taskManger(本地模拟的一个task,2个slot)
在yarn环境只可以正常执行,查看资源消耗可知,多个group,需要多个taskManger才能执行完成(多个slot不行)

-
job,子任务,任务,并行度关系
- job是一个完整的flink处理程序
- task 是job 的一个阶段,是一个算子或者几个并行度一样的算子形成的算子链
- subtask 是一个阶段任务数据分区分别执行的任务,subtask的数量一般就是当前任务的并行度,除非分组以后组数量小于并行度,这时候subtask数量等于分组数量。
-
Flink支持的数据类型
TypeInformation接口下面,一般通过Types.xxx直接使用flink已经定义好的数据类型
-
TypeHint的用法
简单的来说TypeHint 类似 TypeReference,用于定义泛型参数
详情查看:fink泛型参数问题和TypeHint TypeInformation Types区别 - zhangyukun - 博客园 (cnblogs.com) -
泛型擦除问题
参数中有出参,出参有泛型参数,并且使用的是lamda表达式
详情查看:[fink泛型参数问题和TypeHint TypeInformation Types区别 - zhangyukun - 博客园 (cnblogs.com)]( -
Flink对象类的要求
- 类是public
- 有无参构造
- 所有属性都是public
- 所有属性都支持序列化
-
RichXXXFunction
每个算子都有一个 RichXXXFunction的抽象类,里面的的 open 和 close 是每个并行度维度执行一次。
RichXXXFunction提供了生命周期函数和运行时上下文,可以实现一些复杂情况下的拓展
-
算子链的禁用和启用一个新的算子链
相邻算子,并行度相同,默认会自动联合,联合以后变成一个串行的联合任务。只有资源占用不高的算子才适合联合。
disableChaining:禁用算子链合并(和前后都不联合)
startNewChain:启动一个新的算子链(当前任务节点启动一个新的链,和前面不联合)合并多个算子以后他们就是同一个task,会在同一个slot上执行。
-
多并行度必须keyby?
source以后默认就会拆分成多个子任务,多个并行度执行,keyBy只是重新分组,分组会影响分区 -
分区和分组的关系
分区和并行度有很大的关系,并行度就是分区上限,source阶段有一次分区,分区的实质就是把数据分配到子任务,分区只对单个算子有效,后面的算子如果重新分区前面的分区就无效了。
分区和分组的区别在于分区是分子任务,每个子任务是独立计算的,分组类似一种特殊的分区,分组以后同一个组的数据一定在一个分区,不同组的数据也可能在一个分区,分组过程数据也会从分配,也是一种分区。 -
开启本地webui
//开启调试的webUI,只能本地用 StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());如果是打包线上执行jar包,不能使用LocalEnvironment
#打包到线上执行的程序,需要使用线上的环境getExecutionEnvironment StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment(); -
keyby以后再 windowAll 是怎么运行的?
keyby是分组,分组自带分区,是数据的重新分配,windowAll是强行合并成一个子任务所以结果是windowAll以后会变成一个子任务在执行,同理如果两个不同分组key的keyby前后执行,等于两次数据的重新分配,效果等同于只执行了第二个。 -
数据生成器
DataGeneratorSource dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() { @Override public String map(Long value) throws Exception { return "number:" + value; } },10, RateLimiterStrategy.perSecond(10),Types.STRING); -
flink的累加器
范围和算子状态一样,通过 getRuntimeContext()添加和获取,因为向容器中注册了,所以也可以根随保存点保存
默认常见数字类型都有比如IntCounter,还有List类型的
flink安装
参考:https://www.cnblogs.com/cxygg/p/18067123
数据来源(source)
一个简单的输入例子
//取得运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//获取输入数据
DataStreamSource<String> dataStreamSource = env.fromCollection(Arrays.asList( "hello hadoop","hello spark","hello flink" ) );
fink获取数据源的方式
常见的就是集合,socket,kafka,和文件
//来自集合
environment.fromElements(1,2,3,4,5);
environment.fromCollection( Arrays.asList(1,2,3,4,5) );
//来自socket
environment.socketTextStream("192.168.100.66",8888);
//来自kafka
KafkaSource<Object> kafkaSource = KafkaSource.builder()
.setBootstrapServers("xxxx")
.setGroupId("xxx")
.setTopics("xxxx")
.setValueOnlyDeserializer(null)
.setStartingOffsets(null)
.build();
DataStreamSource<Object> dataStreamSource = environment.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"kafakaSource");
//来自文件,可以是HDFS的文件 new Path("hdfs://vm201:8020/input/README.txt")
FileSource<String> fileSource = FileSource
.forRecordStreamFormat(new TextLineInputFormat(), new Path(inputFile))
.build();
DataStreamSource<String> dataStreamSource = environment.fromSource(fileSource, WatermarkStrategy.noWatermarks(),"input");
使用连接器定义的数据源需要导入jar包
environment.fromSource()导入的数据源一般都需要导入连接器实现包,比如上面的例子中的kafka和file
<!--使用kafka来源的数据需要使用的包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.2</version>
</dependency>
<!--使用files来源的数据需要使用的包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>1.17.2</version>
</dependency>
fromSource可以使用连接器定义的数据源
目前fink支持的连接器,带有source的就可以作为数据源,带有sink标记的就是可以作为输出端。
这些连接器都需要导入相应的依赖包。

fink常见的读取文件是kafka和hdfs
如果上面已有的连接器没有你想要的,可以自定义,通过实现Source 接口
DataGeneratorSource可以辅助生成测试数据
DataGeneratorSource是一个特殊的数据源,它用于生成数据,我们指定要生成多少个数据,和生成数据的间隔就能自动生成数据,一般用于测试
DataGeneratorSource dataGeneratorSource = new DataGeneratorSource<>(new GeneratorFunction<Long, String>() {
@Override
public String map(Long value) throws Exception {
return "number:" + value;
}
},10, RateLimiterStrategy.perSecond(10),Types.STRING);
数据输出(sink)
一个简单的fink输出例子
//开启调试的webUI
StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//读取数据
DataStreamSource<String> dataStreamSource = environment.fromElements("hello hadoop","hello spark","hello flink" );
//输出数据到控制台
dataStreamSource.print();
//启动计算
environment.execute();
dataStreamSource.print()效果是把数据流输出到控制台,它是sink的实现
@PublicEvolving
public DataStreamSink<T> print() {
PrintSinkFunction<T> printFunction = new PrintSinkFunction<>();
return addSink(printFunction).name("Print to Std. Out");
}
sinkTo()可以使用连接器定义的输出方式
dataStreamSource.sinkTo(fileSink);是常见的输出方法,导入对应连接器以后可以数据输出到文件系统,kafka,mysql,es等等
//输出数据到文件系统,当然可以是HDFS的路径
FileSink fileSink = FileSink.forRowFormat(new Path("D:\\code\\out.txt"), new SimpleStringEncoder()).build();
dataStreamSource.sinkTo(fileSink);
官已经实现的sink如下图,可以通过导入连接器包,然后直接输出计算结果

自定义sink
如果上面都没有你想要的输出位置,可以自定义sink,通过实现SinkFunction
//下面的匿名内部类实现了输出数据到控制台,效果和dataStreamSource.print()类似
dataStreamSource.addSink(new SinkFunction<String>() {
@Override
public void invoke(String value) throws Exception {
//在这可以控制输入结果到任意
System.out.println( value );
}
});
通过实现Sink接口,然后调用 sinkTo()也是可以的。而且sink接口提供了更多的功能。
算子
先说说什么是算子,算子是一个专业术语,可以理解成处理数据的一个计算函数。
比如 输入一行字符串,输出一个对象。又比如数据一系列对象,输出对象的数量。fink的数据流处理过程又多个算子组成
常见算子
-
map,输入一个参数,返回一个参数
//map 映射 SingleOutputStreamOperator<String> map = dataStreamSource.map(item -> { return item + "OK"; }); -
flatMap,输入一个参数,返回一个集合,效果是把参数展开
//输出参数是通过出参的方式输出的,不是通过返回值 dataStreamSource.flatMap((String in, Collector< Tuple2<String,Integer> > out)->{ String[] wrods = in.split(" "); for(String wrod: wrods ){ out.collect( Tuple2.of(wrod,1 ) ); } } -
filter,输如一个数据,如果返回放回false,这个数据就会被过滤掉
//fiter 过滤 SingleOutputStreamOperator<String> filter = dataStreamSource.filter(item -> { return true; }); -
分组和分组后聚合函数
-
keyBy,分组算子,效果类似grouBy
分组以后,同一组的数据都会进入同一个子任务,会在同一个节点上执行,和MapReduce的分区类似
值得注意的是fink的状态变量,如果是按键分区的状态变量,那么一组访问的是同一值,不同组访问的是不同的值。//分组 KeyedStream<String, String> keyBy = dataStreamSource.keyBy(item -> item); -
max,min,sum 聚合函数(只有分组以后才能用)
-
maxBy,minBy,sumBy 聚合函数(只有分组以后才能用)
-
max,min,sum 和 maxBy,minBy,sumBy的区别
max返回的不是一个字段,而是一个对象,求max值的字段外,别的字段取值情况不同,max使用的第一个,maxBy使用的最大的那个
-
-
reduce ,归约函数,效果是数据流的两两聚合
dataStreamSource.reduce((value1, value2) -> { return Tuple2.of( value1.f0,value1.f1+value2.f1 ); }) -
分区算子(分区的效果是主任务被拆分到多个区)
-
shuffle 随机分配数据到子任务
-
rebalance 局部轮询分配数据到子任务
-
rescale 全局轮询分配数据到子任务
-
global 把所有任务都分到一个子任务(相当于把当前并行度设置为1)
-
partitionCustom 自定义分区
出入的是数据,和运行分几个区,返回分区号。//自定义分区 dataStreamSource.partitionCustom( (String key, int numPartitions)-> (Math.abs( key.hashCode()%numPartitions )) , item-> item.f0 ).print();
-
分区和分组的区别
一个分区里面可以有多个组,一个组只能位于一个分区。
分区和并行度相关,如果并行度是8,那么最多有8条执行线在跑,分区效果是把数据分散到子任务,或者说执行线。
分组key相同的一定会去一个区。
普通变量的共享范围是分区内,keyby状态变量的共享访问是组内。
RichXXXFunction
所有的算子都是实现的XXXFunction接口,比如reduce算子实现的就是 ReduceFunction接口,这个接口是最基本的实现,如果要实现复杂功能(比如拿到一些生命周期,获取RuntimeContext)可以使用RichXXXFunction。
new RichReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of( value1.f0,value1.f1+value2.f1 );
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
System.out.println("open:" + parameters);
System.out.println("open:子任务名字:" + getRuntimeContext().getTaskNameWithSubtasks());
System.out.println("open:子任务编号:" + getRuntimeContext().getIndexOfThisSubtask());
}
@Override
public void close() throws Exception {
super.close();
System.out.println("子任务名字:"+ getRuntimeContext().getTaskNameWithSubtasks());
System.out.println("子任务编号:"+ getRuntimeContext().getIndexOfThisSubtask());
}
}
数据的分流和合流
分流
通过context.output(outputTag, item);输出到测流
//定义一个输出标记
OutputTag<Tuple2<String, Integer>> outputTag2 = new OutputTag<>("output2", Types.TUPLE(Types.STRING, Types.INT));
//处理算子通过 context把一部分数据输出到测流,另外一部分数据通过收集器输出到主流
SingleOutputStreamOperator<Tuple2<String, Integer>> process = flatMap.process(new ProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>() {
@Override
public void processElement(Tuple2<String, Integer> item, ProcessFunction<Tuple2<String, Integer>, Tuple2<String, Integer>>.Context context, Collector<Tuple2<String, Integer>> collector) throws Exception {
if (item.f0.startsWith("hello")) {
collector.collect(item);
} else {
//输出到边侧流
context.output(outputTag2, item);
}
}
});
//主流输出
process.print();
//侧流输出
process.getSideOutput( outputTag2 ).print();
合流
union方式合流
可以同时合并多条流,需要每条流里面的数据一样
StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//创建了3条流
DataStreamSource<String> dataStreamSource = environment.fromElements("hello hadoop","hello spark","hello flink" );
DataStreamSource<String> dataStreamSource2 = environment.fromElements("hello2 hadoop","hello2 spark","hello2 flink" );
DataStreamSource<Integer> dataStreamSource3 = environment.fromElements(1 ,2 ,3 );
//需要类型装换成一样才能合流
//可以合并多条流
DataStream<String> union = dataStreamSource.union(dataStreamSource2,dataStreamSource3.map(item->item+""));
connect方式合流
只能两条流合并,允许不同类型的数据流合并
所有处理算子都有两个处理方法,一个是处理第一条流,一个是处理第二条流,处理方法接口都是 CoXXXFunction 格式的接口,表示两组输出参数
//开启调试的webUI
StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//设置并行度
environment.setParallelism(3);
DataStreamSource<String> dataStreamSource = environment.fromElements("hello hadoop","hello spark","hello flink" );
DataStreamSource<Integer> dataStreamSource2 = environment.fromElements(1 ,2 ,3 );
//不同数据流可以合流
ConnectedStreams<String, Integer> connect = dataStreamSource.connect(dataStreamSource2);
//合流以后得所有算子处理方法都是2个
SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = connect.flatMap(new CoFlatMapFunction<String, Integer, Tuple2<String, Integer>>() {
@Override
public void flatMap1(String in, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] wrods = in.split(" ");
for (String wrod : wrods) {
out.collect(Tuple2.of(wrod, 1));
}
}
@Override
public void flatMap2(Integer integer, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(Tuple2.of(integer+"", 1));
}
});
flatMap.print();
窗口
窗口是在数据流中取一段数据,比如数据流当前时间往前的100个数据,或者当前时间往前的5秒钟内的数据。
很多时候我们需要的不是统计所有数据,而是窗口内的数据,比如月销量排行榜,游戏里面的战斗力排行也是统计指定时间在线的用户。
window的目的是积累一定数据然后聚合或者别的处理,窗口会在窗口结束的时候输出本窗口内数据的聚合结果。所以窗口是不能直接sink的,需要聚合计算以后才能输出。
除了windowAll,别的窗口都要分组(keyBy)以后才能使用。
窗口分类
按照数据拆分方式可以划分为时间窗口和计数窗口
按照窗口间数据是否可以重复划分成滚动和滑动窗口
- 滚动窗口,比如第一个窗口是0-5秒,第二个窗口是5-10秒,第三个事5-15秒
- 滑动窗口,比如第一个窗口是0-5秒,第二个是2-7秒,第三个是9-14秒
计数窗口
KeyedStream.countWindow()产生计算窗口,两个参数的是滑动,一个参数的滚动窗口
需要注意的是,窗口没有使用收集器输出,只是两两聚合,在窗口结束的时候把最终聚合的结果通过采集器输出
//分组
KeyedStream<ActionItem, String> keyBy = map.keyBy(item -> item.getAction());
//计数滚动窗口,一个窗口收集5个数据,相当于滑动步长等于收集数据个数
WindowedStream<ActionItem, String, GlobalWindow> actionItemStringGlobalWindowWindowedStream = keyBy.countWindow(5);
//计数滑动窗口,一个窗口收集5个数据,滑动步长2
//WindowedStream<ActionItem, String, GlobalWindow> actionItemStringGlobalWindowWindowedStream = keyBy.countWindow(5,2);
//这个归约函数是聚合的窗口内的数据,它并没有使用收集器输出,只是两两聚合,在窗口结束的时候把最终聚合的结果通过采集器输出
SingleOutputStreamOperator<ActionItem> reduce = actionItemStringGlobalWindowWindowedStream.reduce((a, b) -> {
ActionItem actionItem = new ActionItem();
actionItem.setAction(a.getAction());
actionItem.setActionTime(a.getActionTime() + b.getActionTime());
actionItem.setValue(a.getValue());
return actionItem;
});
计数窗口其实是一个GlobalWindows
如下图配置了不同的触发和移除器
/**
* Windows this {@code KeyedStream} into tumbling count windows.
*
* @param size The size of the windows in number of elements.
*/
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size) {
return window(GlobalWindows.create()).trigger(PurgingTrigger.of(CountTrigger.of(size)));
}
/**
* Windows this {@code KeyedStream} into sliding count windows.
*
* @param size The size of the windows in number of elements.
* @param slide The slide interval in number of elements.
*/
public WindowedStream<T, KEY, GlobalWindow> countWindow(long size, long slide) {
return window(GlobalWindows.create())
.evictor(CountEvictor.of(size))
.trigger(CountTrigger.of(slide));
}
时间窗口
通过KeyedStream.window()创建时间窗口
TumblingProcessingTimeWindows 是滑动窗口(基于处理时间)
SlidingProcessingTimeWindows 是滑动窗口(基于处理时间)
时间窗口依赖的时间在flink里面可以使用处理时间(系统时间)或者事件时间(水位线)
TumblingEventTimeWindows 是滑动窗口(基于事件时间)
SlidingEventTimeWindows 是滑动窗口((基于事件时间))
事件时间:数据产生的时间
处理时间:flink处理这份数据的当前系统时间
//分组
KeyedStream<ActionItem, String> keyBy = map.keyBy(item -> item.getAction());
//创建滚动时间窗口,窗口时长5秒
TumblingProcessingTimeWindows tumblingWindow = TumblingProcessingTimeWindows.of(Time.seconds(5));
//创建滑动时间窗口,窗口时间5秒,滑动步长2
//SlidingProcessingTimeWindows slidingWindow = SlidingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(2));
//创建窗口
WindowedStream<ActionItem, String, TimeWindow> window = keyBy.window(tumblingWindow);
SingleOutputStreamOperator<ActionItem> reduce = window.reduce((a, b) -> {
ActionItem actionItem = new ActionItem();
actionItem.setAction(a.getAction());
actionItem.setActionTime(a.getActionTime() + b.getActionTime());
actionItem.setValue(a.getValue());
return actionItem;
});
会话窗口
回话窗口是一个特殊的时间窗口,它不是固定时间就结束窗口,而是固定时间没有新的数据输入就结束窗口
他是一个时间窗口,所以也有基于事件事件的回话窗口,EventTimeSessionWindows
//分组,分组以后才能用窗口
KeyedStream<ActionItem, String> keyBy = map.keyBy(item -> item.getAction());
//回话窗口5秒钟的回话窗口,5秒没有请求过来就超时
ProcessingTimeSessionWindows timeSessionWindows = ProcessingTimeSessionWindows.withGap(Time.seconds(5));
//和产生时间窗口的方式一样
WindowedStream<ActionItem, String, TimeWindow> window = keyBy.window(timeSessionWindows);
SingleOutputStreamOperator<ActionItem> reduce = window.reduce((a, b) -> {
ActionItem actionItem = new ActionItem();
actionItem.setAction(a.getAction());
actionItem.setActionTime(a.getActionTime() + b.getActionTime());
actionItem.setValue(a.getValue());
return actionItem;
});
全局窗口
相当于收集的是分组内所有数据,不限时的窗口,如果是无界流,就等不到它的输出了,计数窗口就是用的它上面配置了不同的触发和移除器实现的
//分组
KeyedStream<ActionItem, String> keyBy = map.keyBy(item -> item.getAction());
//全局window
WindowedStream<ActionItem, String, GlobalWindow> window = keyBy.window(GlobalWindows.create());
SingleOutputStreamOperator<ActionItem> reduce = window.reduce((a, b) -> {
ActionItem actionItem = new ActionItem();
actionItem.setAction(a.getAction());
actionItem.setActionTime(a.getActionTime() + b.getActionTime());
actionItem.setValue(a.getValue());
return actionItem;
});
windowAll
不分组就能用,相当于只分一个组。一个组只会分到一个区,所以效果就是当前算子并行度强制为1.
//WindowAll 时间窗口
TumblingProcessingTimeWindows tumblingWindow = TumblingProcessingTimeWindows.of(Time.seconds(5));
AllWindowedStream<ActionItem, TimeWindow> allWindowedStream = map.windowAll(tumblingWindow);
//window计数窗口
AllWindowedStream<ActionItem, GlobalWindow> allWindowedStream2 = map.countWindowAll(5,2);
看DAG windowAll 的哪里是一个滑动窗口,并行度强制为1,全局 environment.setParallelism(2),所以别的地方是2.

windowAll 和 globalwindow的区别:
windowAll是一个不需要分组的窗口,GlobalWindow 是组内的一个没有时长限制的窗口
窗口的处理函数
普通聚合函数
min,max,sum,minBy,maxBy,sumBy 区别和分组算子(keyBy)的聚合函数一样,区别在于这里统计的窗口内的聚合
需要注意的是 window数据流不能再分组(不能再keyBy),如果需要分组计算,需要分组以后再window,并且除了windowAll 意外的窗口都要求分组以后才能。
收集类聚合函数
reduce实现窗口内数据的两两聚合,效果和分组内的归约聚合类似,分组并没有提供aggregate函数
aggregate比reduce更加强大,reduce的输入输出必须是同样的参数,aggregate输入和输出可以是不同的数据,并且使用了累加器保存中间聚合结果。
可以用reduce,aggregates实现min,max,sum等聚合函数
window.reduce的例子,reduce是正儿八经的数据流元素两两聚合
//归约聚合,效果是求和
SingleOutputStreamOperator<ActionItem> reduce = window.reduce(new ReduceFunction<ActionItem>() {
@Override
public ActionItem reduce(ActionItem value1, ActionItem value2) throws Exception {
//直接聚合成一个对象
value1.setActionTime(value1.getActionTime() + value2.getActionTime());
return value1;
}
});
window.aggregate的例子,aggregate是和累加器聚合,可以看出特殊的有中介的两两聚合
//一个累加的聚合方法,效果是求和
AggregateFunction<ActionItem, Integer, Integer> addAgg = new AggregateFunction<ActionItem, Integer, Integer>() {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(ActionItem value, Integer accumulator) {
//直接和累加器聚合,然后把聚合结果保存到累加器
return value.getActionTime().intValue() + accumulator;
}
//通过累加器得到最终聚合的结果
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
return a + b;
}
};
SingleOutputStreamOperator<Integer> aggregate = window.aggregate(addAgg);
处理函数
process和apply功能差不多,但是process更加强大
process需要实现ProcessWindowFunction父类AbstractRichFunction,带有Rich的是增强版
apply需要实现WindowFunction,父亲接口是Function
前面算子那章提到过,RichXXXFunction 是 xxxFunction的增强版,带有生命值函数和运行时上下文。
window.apply例子
//WindowFunction 接口函数定义,入参是分区key,窗口口,全量窗口数据,和收集器
void apply(KEY key, W window, Iterable<IN> input, Collector<OUT> out) throws Exception;
// window.apply,效果依旧是求和
SingleOutputStreamOperator<Integer> apply = window.apply(new WindowFunction<ActionItem, Integer, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<ActionItem> input, Collector<Integer> out) throws Exception {
System.out.println( "key:" + key );
AtomicReference<Integer> sum = new AtomicReference<>(0);
input.forEach( item -> {
sum.set(sum.get() + item.getActionTime().intValue());
});
//输出结果
out.collect( sum.get() );
}
});
window.process例子
//ProcessWindowFunction 抽象方法定义如下
public abstract void process(KEY key, Context context, Iterable<IN> elements, Collector<OUT> out) throws Exception;
//window.process,效果依旧是求和
SingleOutputStreamOperator<Integer> process = window.process(new ProcessWindowFunction<ActionItem, Integer, String, TimeWindow>() {
@Override
public void process(String key, ProcessWindowFunction<ActionItem, Integer, String, TimeWindow>.Context context, Iterable<ActionItem> elements, Collector<Integer> out) throws Exception {
System.out.println( "key:" + key );
//能够拿到运行时上下文
System.out.println( getRuntimeContext().getTaskName() );
AtomicReference<Integer> sum = new AtomicReference<>(0);
elements.forEach( item -> {
sum.set(sum.get() + item.getActionTime().intValue());
});
//输出结果
out.collect( sum.get() );
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
}
@Override
public void close() throws Exception {
super.close();
}
});
process是一个通用的处理数据的方法,process在处理窗口数据流的时候是全量处理的,在处理普通数据流的时候是增量的
数据流类型
数据源流
DataStreamSource<String> dataStreamSource = environment.socketTextStream("192.168.100.66",9999);
数据源流式一个特殊的输出流,只有它能读取数据
public class DataStreamSource<T> extends SingleOutputStreamOperator<T>
输出流
数据源流经过任意算子计算以后就变成了输出流,普通算子返回的也是输出流
只有它才能输出(sink)
SingleOutputStreamOperator<ActionItem> map = dataStreamSource.map(item -> {
String[] split = item.split(" ");
ActionItem actionItem = new ActionItem(split[0], Long.valueOf(split[1]), split[2]);
return actionItem;
});
分组流
输出流通过keyBy分组以后就变成了分组流,分组流通过process或者reduce之类的函数变回输出流
//分组
KeyedStream<ActionItem, String> keyBy = map.keyBy(item -> item.getAction());
窗口流
输出流通过窗口函数以后变成窗口流,窗口流通过process或者reduce之类的处理函数变回输出流
TumblingProcessingTimeWindows tumblingWindow = TumblingProcessingTimeWindows.of(Time.seconds(5));
WindowedStream<ActionItem, String, TimeWindow> window = keyBy.window(tumblingWindow);
广播流
BroadcastStream<String> broadcast = configDataStreamSource.broadcast(mapStateDescriptor);
join流
JoinedStreams<String, String> join = watermarks1.join(watermarks2);
连接流
ConnectedStreams<String, Integer> connect = dataStreamSource.connect(dataStreamSource2);
所有的特殊流通过一些处理函数以后都可变成输出流
水位线
事件时间和处理时间的区别
事件时间:数据产生的时间
处理时间:flink处理这份数据的当前系统时间
水位线:一条由事件时间推进的特殊时间线
试想一下fink里面什么东西和时间有关系,那必然是时间窗口,所以水位线很多时候都是和时间窗口一起使用的。并且需要使用事件时间类型的窗口
fink还有一种叫做IngestionTime的时间,这是用接受到数据的时间作为事件时间。是处理时间和水位线的折中策略。
有序水位线
WatermarkStrategy.forMonotonousTimestamps指定有序水位线
//定义水位线生成策略,类型是单调递增的水位线,然后指定时间分配器
WatermarkStrategy<ActionItem> watermarkStrategy = WatermarkStrategy.<ActionItem>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<ActionItem>() {
//时间分配器,定义怎么获取事件时间
@Override
public long extractTimestamp(ActionItem element, long recordTimestamp) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format( new Date(recordTimestamp)));
return element.getActionTime()*1000L;
}
});
//分配水位线
SingleOutputStreamOperator<ActionItem> assignTimestampsAndWatermarks = map.assignTimestampsAndWatermarks(watermarkStrategy);
//启动窗口的时候
KeyedStream<ActionItem, String> keyBy = assignTimestampsAndWatermarks.keyBy(item -> item.getAction());
//时间窗口(使用水位线的时候创建窗口不再是处理时间而是事件时间)
TumblingEventTimeWindows tumblingWindow = TumblingEventTimeWindows.of(Time.seconds(5));
乱序水位线
WatermarkStrategy.forBoundedOutOfOrderness指定乱序水位线,Duration.ofSeconds(2) 指定的时间是水位线比时间时间低2秒
//水位线生成器,乱序的,指定水位线低于事件事件2秒
WatermarkStrategy<ActionItem> watermarkStrategy = WatermarkStrategy.<ActionItem>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withTimestampAssigner(new SerializableTimestampAssigner<ActionItem>() {
@Override
public long extractTimestamp(ActionItem element, long recordTimestamp) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format( new Date(recordTimestamp)));
return element.getActionTime()*1000L;
}
});
//分配水位线
SingleOutputStreamOperator<ActionItem> assignTimestampsAndWatermarks = map.assignTimestampsAndWatermarks(watermarkStrategy);
乱序水位线可以指定推迟时间
//指定推迟时间,实际效果就是水位线比数据流中提取到的最大事件时间慢两秒
WatermarkStrategy.<ActionItem>forBoundedOutOfOrderness(Duration.ofSeconds(2))
乱序水位线可以指定延迟关闭时间
水位线到了应该应该关闭的时候,窗口依旧接收保持接收数据一段时间(这个窗口接收的低于窗口最高水位线的数据,高于的是下一个窗口处理的)
//实际效果,窗口延迟3秒关闭
WatermarkStrategy<ActionItem> watermarkStrategy = WatermarkStrategy.<ActionItem>forBoundedOutOfOrderness(Duration.ofSeconds(2)).withIdleness(Duration.ofSeconds(3))
乱序迟到数据输出到侧输出流
明显,不管是推迟水位线的推进,还是设置窗口延迟关闭的时间,总还是可能有数据超过这个范围,这类数据默认丢弃了,也可以用测流收集起来单独处理
//指定水位分配策略
KeyedStream<ActionItem, String> keyBy = map.assignTimestampsAndWatermarks(watermarkStrategy).keyBy(item -> item.getAction());
//时间窗口(使用水位线的时候创建窗口不再是处理时间而是事件时间)
TumblingEventTimeWindows tumblingWindow = TumblingEventTimeWindows.of(Time.seconds(5));
//定义侧流
OutputTag<ActionItem> ideaDataTag = new OutputTag<ActionItem>("ideaDataTag");
//开启窗口,并且设置测流输出延迟数据
WindowedStream<ActionItem, String, TimeWindow> window = keyBy.window(tumblingWindow).sideOutputLateData(ideaDataTag);
SingleOutputStreamOperator<Integer> apply = window.apply(new WindowFunction<ActionItem, Integer, String, TimeWindow>() {
@Override
public void apply(String key, TimeWindow window, Iterable<ActionItem> input, Collector<Integer> out) throws Exception {
AtomicInteger sum = new AtomicInteger();
input.forEach(item->{
sum.set(sum.get() + item.getActionTime().intValue());
});
out.collect( sum.get() );
}
});
//输出主流数据
apply.print();
//输出测流数据
apply.getSideOutput( ideaDataTag ).print();
自定义水位线生成策略
水位线生成策略主要包含时间分配器和水位生成器()
时间分配器-->提取事件时间
水位生成器-->通过事件时间生成水位线
//使用自定义水位线策略
WatermarkStrategy<ActionItem> watermarkStrategy = WatermarkStrategy.<ActionItem>forGenerator( item-> new MyWatermarkGenerator() ).withTimestampAssigner(new SerializableTimestampAssigner<ActionItem>() {
@Override
public long extractTimestamp(ActionItem element, long recordTimestamp) {
System.out.println(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format( new Date(recordTimestamp)));
return element.getActionTime()*1000L;
}
});
//水位线生成类
public class MyWatermarkGenerator implements WatermarkGenerator {
//记录最高的事件事件
private Long maxTime = 0l;
//每次元素过来只是记录最大的时间,然后周期的的把最大时间设置成水位线
@Override
public void onEvent(Object event, long eventTimestamp, WatermarkOutput output) {
maxTime = Math.max(maxTime, eventTimestamp);
}
//周期性的更新水位线
@Override
public void onPeriodicEmit(WatermarkOutput output) {
output.emitWatermark(new org.apache.flink.api.common.eventtime.Watermark(maxTime-1));
}
}
水位线生成周期
水位线默认不是每条数据都触发生成的,一般都是周期性生成的,默认是200毫秒,也可以自定义水位线,每次条数据都更新水位线
environment.getConfig().getAutoWatermarkInterval(),获取水位线生成间隔
environment.getConfig().setAutoWatermarkInterval(),修改水位线生成间隔
数据流的join
时间窗口join
效果是两条流在同一个时间窗口内,且key相等就能匹配上,然后进入后面的处理函数
流是两条,但是时间窗口只有一个,必须使用事件时间
缺点很明显,两个时间窗口的边界处,即便两条流的事件时间距离非常近也是匹配不到的
//两条流
DataStreamSource<String> dataStreamSource = environment.socketTextStream("192.168.100.66",8888);
DataStreamSource<String> dataStreamSource2 = environment.socketTextStream("192.168.100.66",9999);
//定义水位线策略
WatermarkStrategy<String> stringWatermarkStrategy = WatermarkStrategy.<String>forMonotonousTimestamps().withTimestampAssigner(new SerializableTimestampAssigner<String>() {
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.valueOf(element)*1000L;
}
});
//设置水位线,join必须使用事件时间
SingleOutputStreamOperator<String> watermarks1 = dataStreamSource.assignTimestampsAndWatermarks(stringWatermarkStrategy);
SingleOutputStreamOperator<String> watermarks2 = dataStreamSource2.assignTimestampsAndWatermarks(stringWatermarkStrategy);
//时间窗口
TumblingEventTimeWindows tumblingEventTimeWindows = TumblingEventTimeWindows.of(Time.seconds(5));
//两条流join
watermarks1.join(watermarks2)
//关联key,where是流1的key,equalTo是流2的key
.where(item -> item)
.equalTo(item -> item)
//指定窗口区间内相等
.window(tumblingEventTimeWindows)
//如果匹配到了以后怎么处理,f,s是匹配到以后两条流的记录
.<String>apply((f, s) -> {
return f + ":" + s;
})
.print();
间隔join
只有分组(keyBy)以后才能使用间隔join
intervalJoin方法是定义在KeyedStream接口里面的
相同分区内,如果流1某条数据的事件时间是5,设置的时间间隔是(-2,3),那么会和流2事件时间(3,8)里面数据匹配
间隔join比对条件是keyby的建值相等,并且时间在指定误差以内
对比窗口join减少了边界匹配不上的问题,而且也提供了侧输出流处理匹配不上的数据
//两条流
DataStreamSource<String> dataStreamSource = environment.socketTextStream("192.168.100.66",8888);
DataStreamSource<String> dataStreamSource2 = environment.socketTextStream("192.168.100.66",9999);
//水位线策略
WatermarkStrategy<String> stringWatermarkStrategy = WatermarkStrategy.<String>forBoundedOutOfOrderness(Duration.ofSeconds(0)).withTimestampAssigner(new SerializableTimestampAssigner<String>() {
@Override
public long extractTimestamp(String element, long recordTimestamp) {
return Long.valueOf(element)*1000L;
}
});
//设置水位线
SingleOutputStreamOperator<String> watermarks1 = dataStreamSource.assignTimestampsAndWatermarks(stringWatermarkStrategy);
SingleOutputStreamOperator<String> watermarks2 = dataStreamSource2.assignTimestampsAndWatermarks(stringWatermarkStrategy);
//分组
KeyedStream<String, String> keyBy1 = watermarks1.keyBy(item -> {
//return String.valueOf(Long.valueOf(item) + 1);
return String.valueOf(Long.valueOf(item));
});
KeyedStream<String, String> keyBy2 = watermarks2.keyBy(item -> item);
//测流标签
OutputTag<String> outputTagleft = new OutputTag<String>("left", Types.STRING);
OutputTag<String> outputTagright = new OutputTag<String>("right", Types.STRING);
//时间窗口
TumblingEventTimeWindows tumblingEventTimeWindows = TumblingEventTimeWindows.of(Time.seconds(5));
//间隔join
SingleOutputStreamOperator<String> process = keyBy1.intervalJoin(keyBy2)
//设置时间间隔上下边界
.between(Time.seconds(-2), Time.seconds(3))
//不匹配的数据输出都测流
.sideOutputLeftLateData(outputTagleft)
.sideOutputRightLateData(outputTagright)
//匹配到的数据处理
.<String>process(new ProcessJoinFunction<String, String, String>() {
@Override
public void processElement(String left, String right, Context ctx, Collector<String> out) throws Exception {
System.out.println("left:" + left + "--->" + "right:" + right);
out.collect(left + ":" + right);
}
});
//主流输出和测流输出
process.print();
process.getSideOutput(outputTagleft).print();
process.getSideOutput(outputTagright).print();
间隔join可以用侧流输出匹配不上的数据
//间隔join
SingleOutputStreamOperator<String> process = keyBy1.intervalJoin(keyBy2)
//设置时间间隔上下边界
.between(Time.seconds(-2), Time.seconds(3))
//不匹配的数据输出都测流
.sideOutputLeftLateData(outputTagleft)
.sideOutputRightLateData(outputTagright)
//匹配到的数据处理
.<String>process(new ProcessJoinFunction<String, String, String>() {
@Override
public void processElement(String left, String right, Context ctx, Collector<String> out) throws Exception {
System.out.println("left:" + left + "--->" + "right:" + right);
out.collect(left + ":" + right);
}
});
处理函数
process是最基础的处理函数,基本任何数据流都带有这个方法
普通的输出流的process方法需要传入ProcessFunction,一般process都是一条一条处理数据的,
分组的数据流的process方法需要传入一个KeyedProcessFunction,它的区别在于 可以通过上下文获取到分组key
窗口数据流的process方法需要传入一个ProcessWindowFunction,ProcessWindowFunction比较特殊是整个窗口一起处理的,别的都是单条处理
连接流的process方法需要传入CoProcessFunction,它定义了两个处理元素的方法,分别处理两条流
广播流的的process方法需要传入BroadcastProcessFunction,可以获取广播变量
ProcessFunction的例子
proceFunction接口函函数的三个参数一个数据流元素,一个数处理流程上下文,还有一个是收集器
SingleOutputStreamOperator<String> process = watermarks1.keyBy(item -> item).process(new ProcessFunction<String, String>() {
@Override
public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception {
System.out.println("值是:" + value);
//测流输出
ctx.output(new OutputTag<>("",Types.STRING),value);
//事件时间,水位线,处理时间
Long timestamp = ctx.timestamp();
System.out.println("timestamp:" + timestamp);
System.out.println("ctx.timerService().currentWatermark():" + ctx.timerService().currentWatermark());
System.out.println("ctx.timerService().currentProcessingTime():" + ctx.timerService().currentProcessingTime());
System.out.println("System.currentTimeMillis():" + System.currentTimeMillis());
//定义一个处理时间的定时器
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 1000L);
//定义一个事件时间的定时器
ctx.timerService().registerEventTimeTimer(timestamp + 1000L);
//ctx.timerService().deleteEventTimeTimer( timestamp + 1000L );
System.out.println("-----------------------------------------");
}
处理流程上下文
ProcessFunction.Context
可以拿到时间相关的参数
可以注册定时器
可以侧流输出
//测流输出
ctx.output(new OutputTag<>("",Types.STRING),value);
//拿到最大的事件时间
Long timestamp = ctx.timestamp();
System.out.println("timestamp:" + timestamp);
//拿到水位线
System.out.println("ctx.timerService().currentWatermark():" + ctx.timerService().currentWatermark());
//拿到处理时间
System.out.println("ctx.timerService().currentProcessingTime():" + ctx.timerService().currentProcessingTime());
System.out.println("System.currentTimeMillis():" + System.currentTimeMillis());
//定义一个处理时间的定时器
ctx.timerService().registerProcessingTimeTimer(ctx.timerService().currentProcessingTime() + 1000L);
//定义一个事件时间的定时器
ctx.timerService().registerEventTimeTimer(timestamp + 1000L);
定时器触发的方法
//定时器触发
@Override
public void onTimer(long timestamp, ProcessFunction<String, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("*********************触发时间:" + timestamp);
System.out.println("*********************ctx.timerService().currentWatermark():" + ctx.timerService().currentWatermark());
}
Process例子,求窗口内的TopN
//设置水位线,join必须使用事件时间
SingleOutputStreamOperator<String> watermarks1 = dataStreamSource.assignTimestampsAndWatermarks(stringWatermarkStrategy);
//求窗口内的TopN
SingleOutputStreamOperator<String> process = watermarks1
.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
.process(new ProcessAllWindowFunction<String, String, TimeWindow>() {
@Override
public void process(ProcessAllWindowFunction<String, String, TimeWindow>.Context context, Iterable<String> elements, Collector<String> out) throws Exception {
List<String> datas = new ArrayList<>();
for (String item : elements) {
datas.add(item);
}
//分组求count
Map<String, List<String>> map = datas.stream().collect(Collectors.groupingBy(item -> item));
List<Tuple2<String, Integer>> collect = map.keySet().stream().map(item -> {
Tuple2<String, Integer> tuple2 = new Tuple2<String, Integer>(item, map.get(item).size());
return tuple2;
}).collect(Collectors.toList());
//排序
collect.sort((a, b) -> {
return b.f1 - a.f1;
});
//输出tipN
out.collect("top1:" + collect.get(0).f0 + ":" + collect.get(0).f1);
out.collect("top2:" + collect.get(1).f0 + ":" + collect.get(1).f1);
}
});
process.print();
Process例子,求TopN,并且5秒输出一次最新的TopN
SingleOutputStreamOperator<String> process = watermarks1.process(new ProcessFunction<String, String>() {
//注意普通变量最好不要用,应该用状态变量,即便的隔离级别就是分区隔离
Map<String, Integer> keyCount = new HashMap<>();
//分区收集
@Override
public void processElement(String value, ProcessFunction<String, String>.Context ctx, Collector<String> out) throws Exception {
if (keyCount.get(value) == null) {
keyCount.put(value, 0);
}
keyCount.put(value, keyCount.get(value) + 1);
//5秒输出一次
Long time = (System.currentTimeMillis() / 5000L + 1) * 5000L;
ctx.timerService().registerProcessingTimeTimer(time);
}
@Override
public void onTimer(long timestamp, ProcessFunction<String, String>.OnTimerContext ctx, Collector<String> out) throws Exception {
super.onTimer(timestamp, ctx, out);
//这里可以排序以后再输出
out.collect("keyCount:" + timestamp + JSONUtil.toJsonStr(keyCount));
}
});
状态变量
普通变量和状态变量的区别在与,状态变量可以通过保存点和检查点保存状态,以便恢复到之前执行的状态。
普通成员变量子任务隔离的(一个子任务式的数据位于同一条执行线),状态变量有不同的隔离范围
按键分区状态(键控状态)
键控状态变量只有在keyby以后才能用
键控状态是按照分组隔离的,一条执行线可以有多个分组,一个分组只会在一条执行线上执行
键控状态有下面5种,前面三种都是存一个对象,
ValueState
ListState
MapState
AggregatingState
ReducingState
键控状态是通过runtimeContext.getXXState产生的。runtimeContext 可以通过RichFunction.getRuntimeContext获取
键控状态变量的使用
ValueState,ListState,MapState 类似
//设置水位线,join必须使用事件时间
SingleOutputStreamOperator<String> watermarks1 = dataStreamSource.assignTimestampsAndWatermarks(stringWatermarkStrategy);
SingleOutputStreamOperator<String> process = watermarks1.keyBy(item -> item).process(new KeyedProcessFunction<String, String, String>() {
public ListState<String> listState;
public MapState<String, String> mapState;
public ValueState<Integer> valueState;
/**
* 这两个是自带聚合逻辑的状态对象
*/
public AggregatingState<String, String> aggregatingState;
public ReducingState<String> reducingState;
//初始化状态对象
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//定义状态描述器
ListStateDescriptor<String> listStateDescriptor = new ListStateDescriptor<>("ListStateDescriptor", Types.STRING);
ValueStateDescriptor<String> valueStateDescriptor = new ValueStateDescriptor<>("valueState", Types.STRING);
MapStateDescriptor<String,String> mapStateDescriptor = new MapStateDescriptor<>("mapState", Types.STRING,Types.STRING);
//产生一个键控状态变
listState = getRuntimeContext().getListState(listStateDescriptor);
}
@Override
public void processElement(String value, KeyedProcessFunction<String, String, String>.Context ctx, Collector<String> out) throws Exception {
listState.get().forEach(item -> {
System.out.println("前:" + item);
});
listState.add(value);
listState.get().forEach(item -> {
System.out.println("后:" + item);
});
}
});
归约状态聚合状态里面自带了一个处理函数
AggregatingState,ReducingState 区别
//归约状态变量
ReducingStateDescriptor reducingStateDescriptor = new ReducingStateDescriptor<>("", new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
return value1+value2;
}
}, Types.INT);
//累加状态变量
AggregatingStateDescriptor aggregatingStateDescriptor = new AggregatingStateDescriptor("", new AggregateFunction<Integer, Integer, Integer>() {
@Override
public Integer createAccumulator() {
return 0;
}
@Override
public Integer add(Integer value, Integer accumulator) {
return value+accumulator;
}
@Override
public Integer getResult(Integer accumulator) {
return accumulator;
}
@Override
public Integer merge(Integer a, Integer b) {
return a+b;
}
}, Types.INT);
状态变量的TTL
可以给状态变量设置过期存活时间,续期策略,和过期数据被访问到了怎么返回
ValueStateDescriptor<Integer> valueStateDescriptor = new ValueStateDescriptor<>("ValueState", Types.INT);
//设置状态变量存活时间
StateTtlConfig ttlConfig = StateTtlConfig.newBuilder(Time.seconds(30))
//定时ttl的方式为读取和写入都更新ttl
.setUpdateType(StateTtlConfig.UpdateType.OnReadAndWrite)
//请求到过期但是还没删除的状态变量则呢么处理
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
.build();
//指定存活时间配置
valueStateDescriptor.enableTimeToLive( ttlConfig );
算子状态(受控状态
算子状态变量是子任务隔离的,隔离效果和普通成员变量一样,区别在于受控状态变量可以在通过保存点检查点恢复之前的状态。
状态的保存和恢复依赖保存点和检查点,状态通过状态后端决定数据是存在哪里,通过检查点和保存点保存快照数据
通过ManagedInitializationContext.getOperatorStateStore 可以拿到受控状态存储器
通过实现CheckpointedFunction接口就可以在其内快照和恢复方法参数中拿到ManagedInitializationContext
ManagedInitializationContext也可以拿到键控状态存储器ManagedInitializationContext.getKeyedStateStore
算子状态有两种
ListState
UnionListState
受控状态变量可能是几个子任务的数据合并而来的,不是一个数据,所以只能是列表,需要把它展开才能使用
比如之前是10个子任务,生成快照的时候ListState里面有10分数据,恢复的时候只有5个子任务,那么每个节点就是2份数据,这时候每个节点都要合并数据成一份才能使用。
UnionListState和ListState的区别在于,恢复数据的时候,ListState是子任务平均分配数据,UnionListState是每个子任务分得全量数据然后程序内选取需要的数据。
/**
* 算子状态变量,默认是子任务隔离的(广播变量除外)
*
* @throws Exception
*/
@Test
public void operatorState() throws Exception {
StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
environment.setParallelism(1);
DataStreamSource<String> dataStreamSource = environment.socketTextStream("192.168.100.66", 9999);
SingleOutputStreamOperator<Tuple2<String, Integer>> map0 = dataStreamSource.map(item -> {
String[] s = item.split(" ");
return Tuple2.of(s[0], Integer.valueOf(s[1]));
}, Types.TUPLE(Types.STRING, Types.INT));
SingleOutputStreamOperator<Integer> map = map0.map(new MyMapFunction(), Types.INT);
map.print();
environment.execute();
}
/**
* 一个实现了 CheckpointedFunction 的算子,这样就就能保存状态了
*/
class MyMapFunction implements MapFunction<Tuple2<String, Integer>, Integer>, CheckpointedFunction {
private int count = 0;
ListState<Integer> listState;
@Override
public Integer map(Tuple2<String, Integer> value) throws Exception {
return count++;
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
System.out.println("snapshotStatesnapshotStatesnapshotState");
listState.clear();
listState.add(count);
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
System.out.println("initializeStateinitializeState");
//ListState 恢复方式是一个子任务分配一部分数据。
listState = context.getOperatorStateStore().getListState(new ListStateDescriptor<Integer>("ListStateDescriptor", Types.INT));
//unionListState 恢复方式是 每个子任务都是全量数据
//listState = context.getOperatorStateStore().getUnionListState()
System.out.println("context.isRestored() = " + context.isRestored());
System.out.println("listState.get() = " + listState.get());
//在恢复模式的情况下,把受控变量赋值到普通变量
//为什么我们要用普通变量保存数据,而不是直接在受控变量上操作,因为受控变量可能是几个子任务的数据合并而来的,不是一个数据,是列表,所以不能直接使用,需要把它展开才能使用
if( context.isRestored() ){
for (Integer item : listState.get()) {
count+=item;
}
}
}
}
广播状态
广播变量需要配合广播流才能使用,广播变量是整个流内共享的
StreamExecutionEnvironment environment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
//演示广播变量,需要设置大于1个的并行度,这样才能看出不同子任务可以共享广播状态
environment.setParallelism(5);
//数据流
DataStreamSource<String> dataStreamSource = environment.socketTextStream("192.168.100.66", 9999);
//配置流
DataStreamSource<String> configDataStreamSource = environment.socketTextStream("192.168.100.66", 8888);
//创建广播流
MapStateDescriptor<String, Integer> mapStateDescriptor = new MapStateDescriptor<String, Integer>("mapStateDescriptor",Types.STRING,Types.INT);
BroadcastStream<String> broadcast = configDataStreamSource.broadcast(mapStateDescriptor);
//数据流关联广播流
BroadcastConnectedStream<String, String> connect = dataStreamSource.connect(broadcast);
SingleOutputStreamOperator<String> process = connect.process(new BroadcastProcessFunction<String, String, String>() {
@Override
public void processElement(String value, BroadcastProcessFunction<String, String, String>.ReadOnlyContext ctx, Collector<String> out) throws Exception {
ReadOnlyBroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(mapStateDescriptor);
Integer maxConn = broadcastState.get("maxConn");
if( Integer.valueOf( value ) > maxConn ){
out.collect("超过预期");
}
}
@Override
public void processBroadcastElement(String value, BroadcastProcessFunction<String, String, String>.Context ctx, Collector<String> out) throws Exception {
BroadcastState<String, Integer> broadcastState = ctx.getBroadcastState(mapStateDescriptor);
broadcastState.put( "maxConn", Integer.valueOf( value ) );
}
});
process.print();
environment.execute();
状态backend
状态后端的作用是保存状态。
状态,状态后端,检查点(保存点)都是为了数据恢复服务的。
状态后端有2种,默认的是默认配置是HasdMap
HasdMapStatesBackend:位于jvm内存中
RocksDBStatesBackend:位于磁盘RocksDB是一个数据库
状态后端可以全局配置,也可以每个节点配置,也可以代码里面配置,也可以在提交任务的命令行参数中配置
在代码里面修改状态后端
//设置状态后端为hashMap
//状态后端全局配置,可以每个节点配置,可以在代码里面配置,也可以在提交任务的命令行参数中配置
//可以在命令行提交任务的时候使用-Dstate.backend.type=rocksdb指定状态后端
//全局指定在 flink-conf.yaml里面的 state.backend.type
HashMapStateBackend hashMapStateBackend = new HashMapStateBackend();
//rocksDB 需要导包才能用(fink里面已经有了rocksDB的实现包,打jar包的时候不用打上)
EmbeddedRocksDBStateBackend rocksDBStateBackend = new EmbeddedRocksDBStateBackend(true);
//设置一些参数
rocksDBStateBackend.setDbStoragePath("xxxx");
rocksDBStateBackend.setWriteBatchSize(100);
//设置状态后端
environment.setStateBackend( rocksDBStateBackend );
checkpoint和savepoint
保存点和检查点的区别,检查点是程序周期性自动保创建的,保存点是人为主动保存的。
检查点和保存点都可以用来恢复之前的运行状态。
检查点
检查点事默认关闭的,需要手动开启,并且指定保存周期和建立保存点的方式,不同方式对程序执行精确有影响
没有保存点,可能因为程序关闭丢失数据
CheckpointingMode.EXACTLY_ONCE:精准一次性
CheckpointingMode.AT_LEAST_ONCE:至少一次
对齐保存点:如果是精准一次性,那么可能因为数据阻塞效率变低,如果是非阻塞模式可能出现一份数据被处理多次.
非对其保存点:分对其保存点是精准一次性的,并且也是非阻塞的,但是它是通过保存更多中间状态换来的。
建立检查点的默认模式是:对齐精准一次性方式。
可以设置非对齐方式启用,然后超时就切换成对其方式。
//启用检查点
environment.enableCheckpointing( 5000, CheckpointingMode.EXACTLY_ONCE );
CheckpointConfig checkpointConfig = environment.getCheckpointConfig();
//检查点保存位置
checkpointConfig.setCheckpointStorage( "hdfs://v200:8020/flink/checkpoint" );
//设置检查点保存超时时间
checkpointConfig.setCheckpointTimeout(5000L);
//最大并行的checkpoint数量(保存点可以并行保存的数量)
checkpointConfig.setMaxConcurrentCheckpoints(1);
//保存点间隔(一个保存点完成多久以后,才能执行下一个保存点,所以保存点并行度强制设置为1)
checkpointConfig.setMinPauseBetweenCheckpoints(10*1000L);
//取消的任务,外部存储应该保留还是删除
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//保存点最大失败次数
checkpointConfig.setTolerableCheckpointFailureNumber(10);
//启用非对齐方式的checkpoint
checkpointConfig.enableUnalignedCheckpoints();
//对其方式checkpoint超时时间
checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(2000));
//强制使用非对其方式的checkpoint
checkpointConfig.setForceUnalignedCheckpoints(true);
System.out.println( checkpointConfig.getCheckpointInterval() );
System.out.println( checkpointConfig.getCheckpointingMode() );
保存点
-
设置默认保存点存放位置
如果不设置每次都要指定保存点位置,设置就不用再指定fink-conf.yaml里面
#这行就是默认保存点位置 # state.savepoints.dir: hdfs://namenode-host:port/flink-savepoints -
建立保存点
Syntax: savepoint [OPTIONS][ ] #只是保存,不关联yarn #flink savepoint jobId [保存目录] ./flink savepoint b2914677c2aa44df66ea0a0411fef23f hdfs://vm200:9000/flink/savepoints #建立保存点指定保存目录并且关联yarnappId #flink savepoint jobId [保存目录] -yid yarnAppId ./flink savepoint b2914677c2aa44df66ea0a0411fef23f hdfs://vm200:9000/flink/savepoints -yid application_1710293758827_0002备注:即便是yarn运行模式也可以不指定 -yid,同样可以做到保存和恢复
非yarn模式可能需要 -m 指定 jobmanger -
优雅停止并且建立保存点
据说实现了 StoppableFunction接口的的source才能用,实际没有这个接口,试了一下不能用,保存报错
文档上说:Action "stop" stops a running program with a savepoint (streaming jobs only).实测是SocketStream不行Syntax: stop [OPTIONS]
#fink stop -p 保存目录 jobId ./flink stop -p hdfs://vm200:9000/flink/savepoints b3fce954271ea16f39bf61527a2d234d -
立即停止并且建立保存点
Syntax: cancel [OPTIONS]#flink cancel -s 保存目录 jobId ./flink cancel -s hdfs://vm200:9000/flink/savepoints 487960dda0bb853600429fe77d73c455 -
从保存点启动
Syntax: run [OPTIONS]#flink run -s :savepointPath -n [:runArgs] ./flink run -s hdfs://vm200:9000/flink/savepoints/savepoint-487960-79ef8fc03774 -c com.lomi.flink.TestRun ../examples/BigdataExample-1.0-SNAPSHOT.jar
fink打包
fink的基础依赖建议使用provide,因为线上环境已经有flink的基础jar,不需要打包上去(实际打包上去也没事)
<!--flink-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.2</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>1.17.2</version>
<scope>provided</scope>
</dependency>
依赖设置为scope的时候本地运行的时候指定带上provide依赖
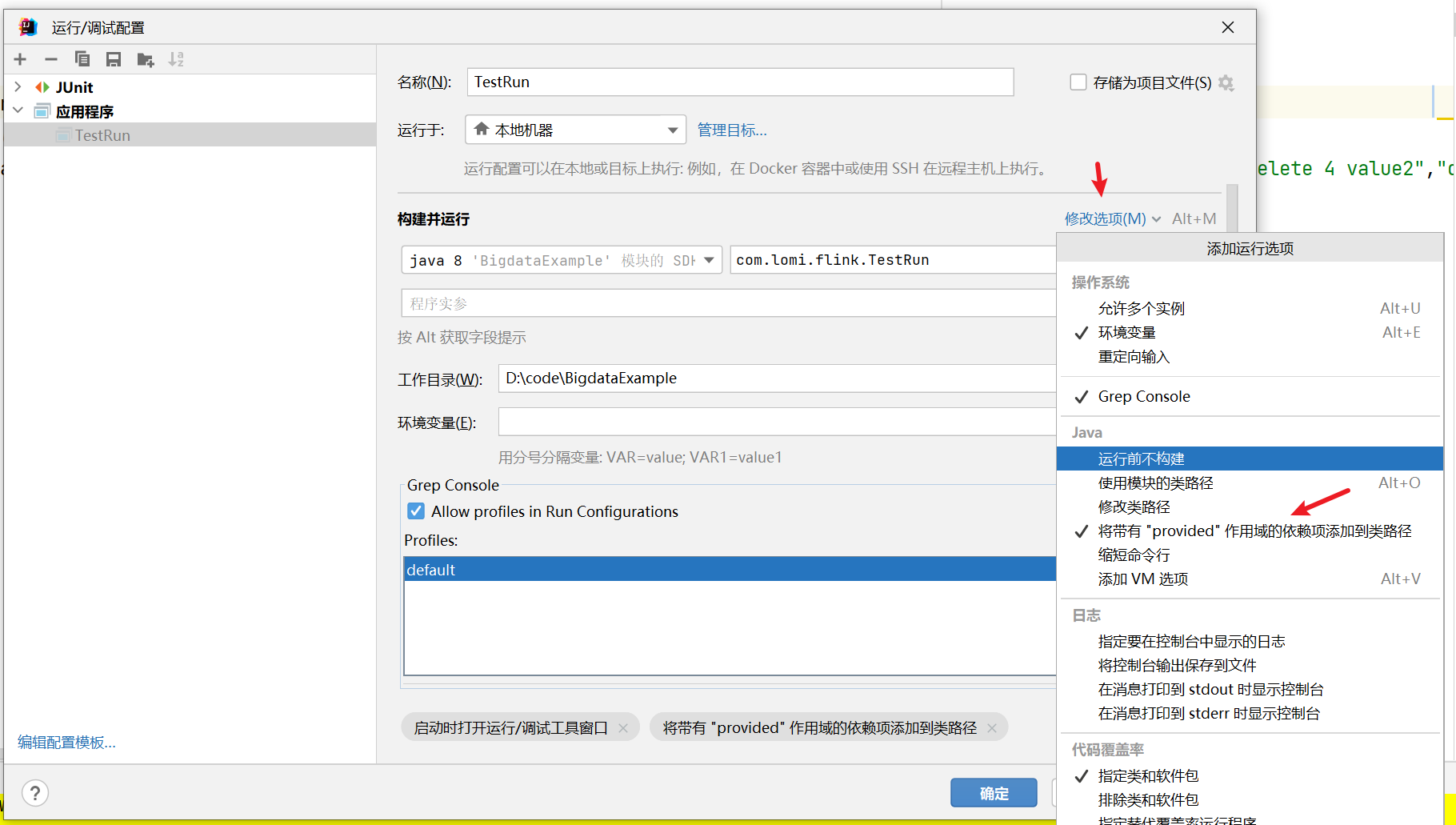
打包插件建议使用maven-shade-plugin
<build>
<!--flink打包-->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<!-- 修改主类-->
<mainClass>com.lomi.flink.TestRun</mainClass>
</transformer>
<transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer">
<resource>reference.conf</resource>
</transformer>
</transformers>
<relocations>
<relocation>
<pattern>org.codehaus.plexus.util</pattern>
<shadedPattern>org.shaded.plexus.util</shadedPattern>
<excludes>
<exclude>org.codehaus.plexus.util.xml.Xpp3Dom</exclude>
<exclude>org.codehaus.plexus.util.xml.pull.*</exclude>
</excludes>
</relocation>
</relocations>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2024-03-07 19:41 zhangyukun 阅读(111) 评论(0) 编辑 收藏 举报


