Snowflake 雪花算法 原理说明和注意事项
先看图中雪花算法的结构

第一段1位,固定0, 69年以后可能会用1,也就是说默认在一个系统中只能用最多69年,如果征用第一位可以使用139年。
第二段41位,用时间毫秒数数表示41位大概是69年多,默认表示1971年1月1日到当前时间的毫秒数,有的雪花算法优化支持设定这个起算时间,我们可以把它指定位我们系统立项的时间,这样的好处在于可以使用完整的69年,第一位改成1,还可以用在用70年,一句话,可以用到死。
第三段10位,2的10次方,同样1024 个标识符,可用最多支持1024 台节点的分布式器群。1024 多余中小公司来说太多了,有些多雪花算法的包装把它分成2段,workerId和datacenterId一段5位,也就是32个值。分别表示不同的服务和同一个服务的不同集群节点。
第四段12位,2的12次方4096个,这个是内部加锁单调递增的。也就是每毫秒最多产出4096个,如果你的业务需要单机平均每毫秒生产的数据量大于4096,那么大概不适合学号算法,或者你改改默认的算法,把第三段用不完的借几位给第4段。如果你的系统只是阶段性的超过没毫秒4096,雪花算法依旧是可以支持的,比如当前毫秒如果不够用了,就自动使用下一个毫秒应该生成的id。我们也可以指定这个向后面的毫秒应该生成的id借最多能接几个毫秒的(注意的是,hutool里面有个bugs)。一般默认不指定,每毫秒4096 以后就重复了,hutool 的默认做法死重复以后就等待到下一毫秒。
下面是一个hutool雪花算法的实现:默认使用时间是2010-11-4 9:42:54(DEFAULT_TWEPOCH),而不是1971年1月1日,默认是没毫秒生产id超过4096个以后就重复,但是可以通过设置timeOffset来指定最多向后面借多个毫秒的ID//
package com.lomi.entity;
/**
* 描述
*
* @Author ZHANGYUKUN
* @Date 2022/6/26
*/
//
// Source code recreated from a .class file by IntelliJ IDEA
// (powered by Fernflower decompiler)
//
import cn.hutool.core.date.SystemClock;
import cn.hutool.core.util.IdUtil;
import cn.hutool.core.util.StrUtil;
import java.io.Serializable;
import java.util.Date;
public class Snowflake implements Serializable {
private static final long serialVersionUID = 1L;
public static long DEFAULT_TWEPOCH = 1288834974657L;
public static long DEFAULT_TIME_OFFSET = 2000L;
private static final long WORKER_ID_BITS = 5L;
private static final long MAX_WORKER_ID = 31L;
private static final long DATA_CENTER_ID_BITS = 5L;
private static final long MAX_DATA_CENTER_ID = 31L;
private static final long SEQUENCE_BITS = 12L;
private static final long WORKER_ID_SHIFT = 12L;
private static final long DATA_CENTER_ID_SHIFT = 17L;
private static final long TIMESTAMP_LEFT_SHIFT = 22L;
private static final long SEQUENCE_MASK = 4095L;
private final long twepoch;
private final long workerId;
private final long dataCenterId;
private final boolean useSystemClock;
private final long timeOffset;
private long sequence;
private long lastTimestamp;
public Snowflake() {
this(IdUtil.getWorkerId(IdUtil.getDataCenterId(31L), 31L));
}
public Snowflake(long workerId) {
this(workerId, IdUtil.getDataCenterId(31L));
}
public Snowflake(long workerId, long dataCenterId) {
this(workerId, dataCenterId, false);
}
public Snowflake(long workerId, long dataCenterId, boolean isUseSystemClock) {
this((Date)null, workerId, dataCenterId, isUseSystemClock);
}
public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock) {
this(epochDate, workerId, dataCenterId, isUseSystemClock, DEFAULT_TIME_OFFSET);
}
public Snowflake(Date epochDate, long workerId, long dataCenterId, boolean isUseSystemClock, long timeOffset) {
this.sequence = 0L;
this.lastTimestamp = -1L;
if (null != epochDate) {
this.twepoch = epochDate.getTime();
} else {
this.twepoch = DEFAULT_TWEPOCH;
}
if (workerId <= 31L && workerId >= 0L) {
if (dataCenterId <= 31L && dataCenterId >= 0L) {
this.workerId = workerId;
this.dataCenterId = dataCenterId;
this.useSystemClock = isUseSystemClock;
this.timeOffset = timeOffset;
} else {
throw new IllegalArgumentException(StrUtil.format("datacenter Id can't be greater than {} or less than 0", new Object[]{31L}));
}
} else {
throw new IllegalArgumentException(StrUtil.format("worker Id can't be greater than {} or less than 0", new Object[]{31L}));
}
}
public long getWorkerId(long id) {
return id >> 12 & 31L;
}
public long getDataCenterId(long id) {
return id >> 17 & 31L;
}
public long getGenerateDateTime(long id) {
return (id >> 22 & 2199023255551L) + this.twepoch;
}
public synchronized long nextId() {
long timestamp = this.genTime();
if (timestamp < this.lastTimestamp) {
if (this.lastTimestamp - timestamp >= this.timeOffset) {
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", new Object[]{this.lastTimestamp - timestamp}));
}
timestamp = this.lastTimestamp;
}
if (timestamp == this.lastTimestamp) {
long sequence = this.sequence + 1L & 4095L;
//默认是这么写的,这里是一个应该是一个bug,如果是向下一秒借的情况,不需要等到下一毫秒,直接返回就行了
if ( sequence == 0L) {
timestamp = this.tilNextMillis(this.lastTimestamp);
}
//修正的写法
/* if ( sequence == 0L) {
if( timeOffset == 0 ){
timestamp = this.tilNextMillis(this.lastTimestamp);
}else{
timestamp = timestamp+1;
}
}*/
this.sequence = sequence;
} else {
this.sequence = 0L;
}
this.lastTimestamp = timestamp;
return timestamp - this.twepoch << 22 | this.dataCenterId << 17 | this.workerId << 12 | this.sequence;
}
public String nextIdStr() {
return Long.toString(this.nextId());
}
private long tilNextMillis(long lastTimestamp) {
long timestamp;
for(timestamp = this.genTime(); timestamp == lastTimestamp; timestamp = this.genTime()) {
}
if (timestamp < lastTimestamp) {
throw new IllegalStateException(StrUtil.format("Clock moved backwards. Refusing to generate id for {}ms", new Object[]{lastTimestamp - timestamp}));
} else {
return timestamp;
}
}
private long genTime() {
return this.useSystemClock ? SystemClock.now() : System.currentTimeMillis();
}
}
//测试例子(测试使用hutool 生产409600个ID ,100毫秒默认生成的最大值,后面 new Snowflake(new Date(), 0, 0, false, 409600000) 最后指的的 偏移毫秒数,我随便指定的,只要大于 100 就行)
public static void main(String[] args) {
Snowflake snowflake = new Snowflake(new Date(), 0, 0, false, 409600000);
Set<Long> ids = new HashSet<>();
Long a = System.currentTimeMillis();
for(int i = 0;i<409600;i++ ){
snowflake.nextId();
// ids.add( snowflake.nextId() );
}
System.out.println( System.currentTimeMillis()-a );
System.out.println( ids.size() );
}
hutool 的写法 用时:
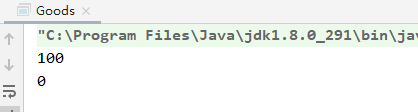
修正后的耗时:

正确性验证代码:生成 409600 个 id并且去重复,然后得到生成的个数
public static void main(String[] args) {
Snowflake snowflake = new Snowflake(new Date(), 0, 0, false, 409600000);
Set<Long> ids = new HashSet<>();
Long a = System.currentTimeMillis();
for(int i = 0;i<409600;i++ ){
//snowflake.nextId();
ids.add( snowflake.nextId() );
}
System.out.println( System.currentTimeMillis()-a );
System.out.println( ids.size() );
}
结果:
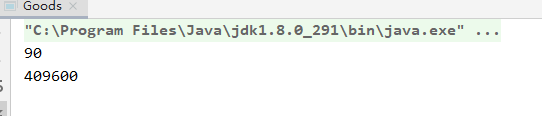
hutool 版本 5.7.22
雪花算法,要保持全局唯一,必须要指定唯一的dataCenterId和 workerId,正常这两个数都是0-31 之间的一个值。
如果我们自己的商用节点,应该依赖注册中心计数器之类的自动设置dataCenterId和 workerId,如果是小集群,固定几台机子手动的为每隔节点指定 dataCenterId和workerId也行(比如读取指定目录下的一个文件)
hutool 里面的 雪花算法能用吗?
hutool里面的没有注册中心,所以不能保证全局唯一的dataCenterId和workId
但是 hutool里面里面的 dataCenterId 是通过物理地址算出来的,然后workId 是通过 dataCenterId+当前进程Id 算出来的.
结论:同一台物理机上 dataCenterId会相等,不同物理机的 dataCenterId 大概率不会相等
同一个Java进程里面 workId 会相等,Java进程重启 workId 会变化 大概率不会相等
所以可以简单的看成hutool随机的指定了dataCenterId和workId重复的概率是1/1024,并且随着节点的增加重复概率会提升。
1节点不重复的概率是:1
2节点不重复的概率是:1-1/1024
3节点重复的概率是:1-(1-1/1024)*1/1023
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2022-06-25 23:48 zhangyukun 阅读(2739) 评论(1) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号