spring cloud alibaba 基本用法
-
maven import 属性
<!--spring alibaba--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2021.1</version> <type>pom</type> <scope>import</scope> </dependency>pom:
import: -
安装和nacos
下载地址:Releases · alibaba/nacos · GitHub
nacos下载以后默认是以集群方式启动的,测试的时候我们可以改成单机启动修改startup.cmd,添加 set MODE="standalone"
![]()
也可以通过 启动命令参数指定位命令行启动startup.cmd -m standalone
-
创建一个Spring boot项目并且注册到nacos

- 程导入阿里巴巴依赖
<dependencyManagement>
<dependencies>
<!--spring boot web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<version>2.4.2</version>
</dependency>
<!--actuator-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
<version>2.4.2</version>
</dependency>
<!--spring alibaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2021.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
-
子工程导入依赖
<dependencies> <!--spring boot web--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!--actuator--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency> <!--nacos--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> </dependencies> -
修改配置文件
server:
port: 7080
spring:
application:
name: user
cloud:
nacos:
discovery:
server-addr: localhost:8848 #指向nacos
#暴露信息
management:
endpoints:
web:
exposure:
include: "*"
-
通过项目名自动使用配置文件
配置文件查找格式:
${prefix}-${spring.profile.active}.${file-extension}
springcloud alibaba支持通过 spring.application.name来自动匹配配置文件,可以通过spring.cloud.nacos.config.prefi来配置(不配置就使用spring.application.name)
nacos配置文件拓展名的默认是.properties文件,如果指定成yaml和创建配置里面的选择的文件类型yaml对应(这时候dataid不能在加后缀名),如果过加了后缀名相当于自定义类型,程序里面的file-extension也要写成对应格式
1 程序里面不配置file-extension,默认去找.properties
2 配置file-extension:yaml,那么在nacos 配置文件的dataid 不应该有后缀名,文件类型选择yaml,或者nacos里面dataid文件后缀名为.yaml,任意指定文件类型(指定了后缀名文件类型无效)
3 程序里面file-extension:yml,那么dataid应该是 xxx.yml(这时候nacos文件类型不会通过文件类型追加文件名),建议不要这么搞,很乱
需要注意的是加载nacos配置中心的配置要写到bootstrap.yml里面去
- 第版本的spring boot 项目 默认不会优先加载 bootstarp.yml 需要手动处理
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
- 指定共享配置文件
shared-dataids: common.yml
新版本使用的 shared-configs:common.yml

8. 刷新配置文件
使用@RefreshScope写在类上,标记这里面的配置会随着nacos配置中心的刷新实时刷新
- 服务的熔断和降级 sentinel
相当于 hystrix
- 分布式事务 seata
分布式事务,spring cloud 全家桶里面没有类似的组件,类似于三方框架 类似于LCN,除此以外我们还可以用时 mq 的事务消息来实现分布式事务的最终一致性
- nacos 的 命名空间
正常我们会通过命名空间来区分项目,隔离配置
创建命名空间

创建配置文件:

使用对应命名空间的配置文件:

-
配置组
nacos 关于配置组的概念没有 命名空间强烈,组不需要单独创建,同样的组名就能取到,个人建议namaspan隔离项目,group隔离部署区域机房(小公司用默认组就可以了),profile隔离开发测试环境
简单的理解通过 namaspan + gourp + dataId 能找到确定的配置文件(dataId和 profile 和后缀名有关)
![]()
-
nacos 配置和服务器发现生产环境应该支持高可用,默认nacos 存储配置等数据是通过内置数据库,集群环境应该使用
修改config/application.propertise文件的如下配置
![]()

config/mysql-schema.sql是mysql的表结构文件需要提前在数据库中执行
- nacos 默认就是集群方式启动的,集群列表文件位于config/cluster.conf文件里面
正常我们从cluster.conf.example里面复制过来改,然后再里面写入所有子节点的IP和端口
-
nacos集群正常允许模式应该是外面有一个反向代理(指的一个反向代理集群),比如是nginx,然后访问nginx 的时候自动负载均衡到不同的nacos节点,我们程序里面配置的也应该是这个反向代理的地址
或者nacos外面直接就是LVS集群。 -
ngxin作为反向代理的时候怎么处理nginx的单点故障怎么处理?
可以通过lvs解决 -
sentinel
下载地址:Releases · alibaba/Sentinel · GitHub -
启动 sentinel dashboard 程序
java -jar sentinel-dashboard-1.8.6.jar & -
springboot 集成 sentinel
- 导入依赖
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
<version>2021.1</version>
</dependency>
- 修改配置文件

- 访问 http://127.0.0.1:8080/ 就能看到监控信息了(需要访问程序接口以后 sentinel dashboard 才有记录)


- 添加流控规则
![]()



-
sentinel 的流控规则是实时生效的,不需要重启
-
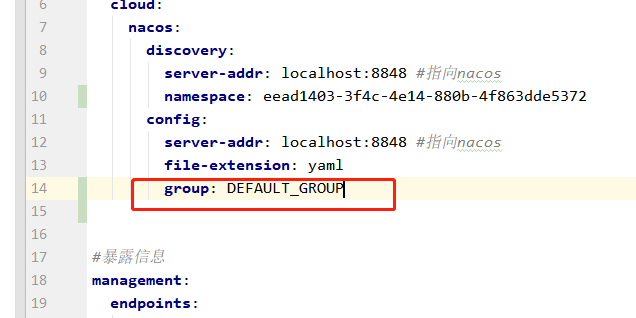
资源名就是
-
阈值类型
![]()
qps:没秒可以通过的请求数量 并发线程数:任意时间节点,只能有一个请求处理处理中。 -
流控模式
![]() 直接:对自己限流
直接:对自己限流
关联:一个接口达到阈值,对上流接口限流(比如支付达到阈值,限制下单接口)
链路:?? -
流控效果(只有QPS 才能选着流控效果,线程数不能选,因为线程数类型的阈值是在处理请求以后)
快速失败:直接返回 429 状态码,的失败信息
Warm Up(预热):默认的coldFactor是3,也就是初始限流 1/3 的阈值,然后一定时间内慢慢提升到指定阈值,是一种逐步放开限制到阈值的配置,这过程中超出负载和快速失败的结果一样。这种模式可以给系统预热的时间,吧缓存,内存等撑起来。
排队等待:超过流控的就等待,而不是失败,在最大等待时间内为处理的请求会一只等待,超时和快速失败一样的返回?
-
熔断在一定时长的时间窗口内,不在处理任何请求,直接相应失败。
![]()
-
sentinel熔断没有的半开状态,是通过时间窗口控制的,Hystrix有半熔断
关于降级和熔断,服务降级指的是服务相应太慢或者异常情况直接快速返回默认的优化提示,降级的过程中先回调用正常的方法,熔断是搞级别的降级,不会在调用正常的逻辑,直接走默认流程。或者说降级是针对单词请求给默认值,降级是后面一段时间都直接走默认值。sentinel 里面的限流和熔断 处理方式都是一小段时间直接返回,不在请求正确逻辑,应该都算作熔断。sentinel 好像没有对单次请求降级相关的设置?都是一段时间窗口内的设置。
老版本的sentinel关于熔断的配置,叫做降级规则,新版本叫做熔断规则,显然新版本更加合理。 -
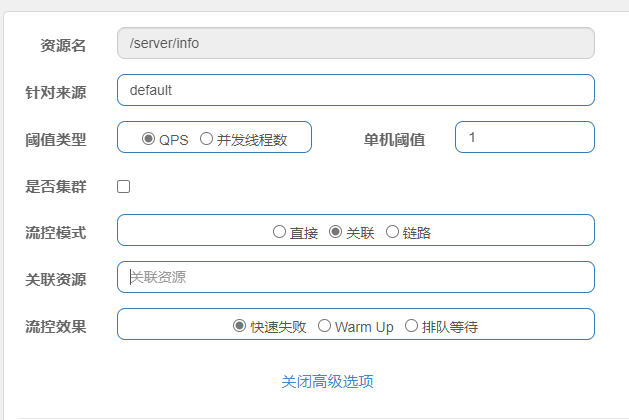
熔断策略-慢调用比例(调用时间超过一定时间的请求比例)
![]()
最大RT:最大响应时间
比例阈值:响应时间大于最大RT的比例取值0-1
熔断时间:熔断多久
最小请求数:避免第一个请求就超过最大RT的情况
统计时间:统计的时间窗口周期 -
熔断策略-异常比例(一定时间内异常比例高于一定值,就熔断指定时间)
![]()
-
熔断策略-异常数(和上面差不多,只是处罚条件是异常数量)
![]()
-
老版本的熔断是在当前时间窗口内熔断,如果这个时间窗口马上结束了,那么熔断会马上结束,如果是在时间窗口的初期,那么会持续几乎整个时间窗口的时间。新版的sentinel可以分别设置统计时间的时间窗口和熔断时间持续的时间窗口,也就是熔断时长固定了。
-
sentinel 的配置怎么保存?保存在哪里?
可以在sentinel配置文件中指定nacos,然后存在nacos哪里 -
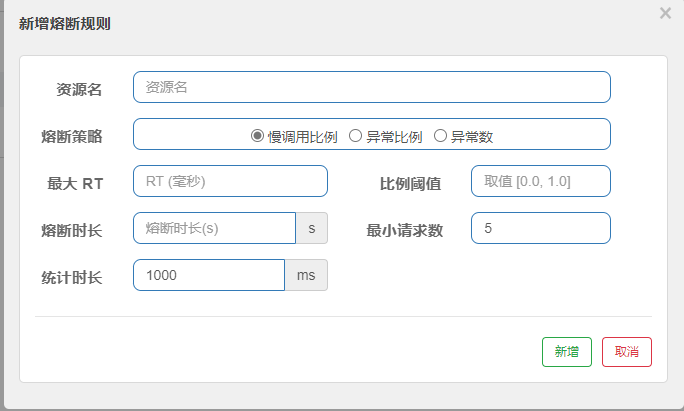
热点规则
sentinel 可以对指定接口的指定参数的不同情况进行限流,比如某个参数的值是指定值得时候开始限流
![]()
-
@SentinelResource 和 @HystrixCommand 区别
@SentinelResource(value="资源的名字",blockHandler="失败默认值的方法"),使用SentinelResource最好要指定失败处理方法,这个方法参数和原方法一样,但是要多加一个异常参数BlockException ,如果没有@SentinelResource 的blockHandler方法默认处理方法 只对限流熔断热点等配置规则的情况,对异常无效,fallback才对异常有效
@HystrixCommand 的fallback方法 对超时,异常,熔断有效 -
热点规则
如果一个接口带有指定参数(通过@SentinelResource 参数下标确定参数),那么久限流,并且在这个值等于不同值的时候可以指定不同的限流规则。下面配置指定的带有这个参数默认限流每秒1次请求,如果是张三提升到100次,李四提升到10次
![]()
-
热点配置 不和@SentinelResource 用可以吗?热点数据对对象类型的参数怎么配置?
-
系统规则
对整个app的总体配置,而不是对单个接口的配置
![]()

 直接:对自己限流
直接:对自己限流




load: windows无效的参数,linux/unix 才有效,一般是cpu数量的2.5倍
linux有个指标是
RT:response time
-
@SentinelResource的 value 和 请求的 url 都可以做流控资源
如果只有@SentinelResource指定的blockHandler,那么就只有默认异常页面
如果@SentinelResource指定的blockHandler ,并且使用SentinelResource 的 value 指定资源,那么会使用指定的 blockHandler 方法处理数据,这使用如果使用RequestMapping作为资源名字依旧返回的默认页面
如果RequestMapping 和 SentinelResource 的value 一样,那么轮着出现 默认页面和blockHandler 方法的结果,这就奇怪了,感觉应该是一个bug。结论:要使用自定义默认兜底数据,必须使用@SentinelResource,并且必须指定blockHandler方法,并且 SentinelResource 的value值不要和请求地址一样。

-
SentinelResource blockHandler 方法和fallback 的 区别
fallback:管理异常兜底
blockHandler:管配置的流控,熔断,等规则的兜底 -
我们可以通过 blockHandlerClass 和 fallbackClass 来指定 处理方法的所在类,不指定就是当前方法,处理方法在别的类需要是静态的。
兜底方法必须是参数列表相同,并且最后一个参数是blockHandler

-
为了避免重复和相应异常轮询问题,建议SentinelResource的 value 是固定开头+RequestMapping value
-
SentinelResource 还可以配置 那些异常生效那些异常不生效
默认throwAble就会抛出
![]()
-
sentinel代码级别的流控规则怎么配置?
-
sentinel 启用feign需要在配置文件中独立开启。默认情况下sentinel是对controller 做流控设置,如果需要在 feign配置需要在配置中指定开启,这时候控制的是调用方,Controller控制的是被调用方。
sentinel.feign.enable=true
-
sentinel 持久化到nacos
-
添加 sentinel-datasource-nacos 依赖
-
在sentinel配置文件中指定nacos地址
-
-
seata
阿里的分布式事务解决方案 -
seata-server的配置和启动
-
修改seata-server的配置文件config/application.yml
注册中心配置说明:重点需要关注配置里面group,application两个参数如果和后面程序中指定的不一样会找不到服务
配置中心说明:配置注册可以是两个nacos,这是写的是seata-server 这个服务可以托管在配置中心的配置文件需要注意group和data-id,我们其他的配置都会写到这里面去,比如seata使用的数据库。
![]()
-
在nacos中配置seata 的配置文件
![]()
内容如下
-



store:
mode: db
lock:
mode: db
session:
mode: db
db:
datasource: druid
dbType: mysql
# MySQL8的驱动
driverClassName: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.100.66:3306/seata?useUnicode=true&rewriteBatchedStatements=true
user: root
password: root
minConn: 5
maxConn: 30
globalTable: global_table
branchTable: branch_table
distributedLockTable: distributed_lock
queryLimit: 100
lockTable: lock_table
maxWait: 5000
server:
recovery:
committingRetryPeriod: 1000
asynCommittingRetryPeriod: 1000
rollbackingRetryPeriod: 1000
timeoutRetryPeriod: 1000
maxCommitRetryTimeout: -1
maxRollbackRetryTimeout: -1
rollbackRetryTimeoutUnlockEnable: false
distributedLockExpireTime: 10000
xaerNotaRetryTimeout: 60000
session:
branchAsyncQueueSize: 5000
enableBranchAsyncRemove: false
undo:
logSaveDays: 7
logDeletePeriod: 86400000
client:
rm:
asyncCommitBufferLimit: 10000
lock:
retryInterval: 10
retryTimes: 30
retryPolicyBranchRollbackOnConflict: true
reportRetryCount: 5
tableMetaCheckEnable: true
tableMetaCheckerInterval: 60000
sqlParserType: druid
reportSuccessEnable: false
sagaBranchRegisterEnable: false
sagaJsonParser: fastjson
tccActionInterceptorOrder: -2147482648
tm:
commitRetryCount: 5
rollbackRetryCount: 5
defaultGlobalTransactionTimeout: 60000
degradeCheck: false
degradeCheckAllowTimes: 10
degradeCheckPeriod: 2000
interceptorOrder: -2147482648
undo:
dataValidation: true
logSerialization: jackson
onlyCareUpdateColumns: true
logTable: undo_log
compress:
enable: true
type: zip
threshold: 64k
tcc:
fence:
logTableName: tcc_fence_log
cleanPeriod: 1h
log:
exceptionRate: 100
metrics:
enabled: false
registryType: compact
exporterList: prometheus
exporterPrometheusPort: 9898
transport:
type: TCP
server: NIO
heartbeat: true
enableTmClientBatchSendRequest: false
enableRmClientBatchSendRequest: true
enableTcServerBatchSendResponse: false
rpcRmRequestTimeout: 30000
rpcTmRequestTimeout: 30000
rpcTcRequestTimeout: 30000
threadFactory:
bossThreadPrefix: NettyBoss
workerThreadPrefix: NettyServerNIOWorker
serverExecutorThreadPrefix: NettyServerBizHandler
shareBossWorker: false
clientSelectorThreadPrefix: NettyClientSelector
clientSelectorThreadSize: 1
clientWorkerThreadPrefix: NettyClientWorkerThread
bossThreadSize: 1
workerThreadSize: default
shutdown:
wait: 3
serialization: seata
compressor: none
指定了seata的配置以后就可以启动seata了
执行bin\seata-server.bat启动
-
seata的基本使用
-
配置seata 的的依赖
<!--spring alibaba--> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>2021.1</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>io.seata</groupId> <artifactId>seata-spring-boot-starter</artifactId> <version>1.5.2</version> </dependency> -
配置spring seata 相关的配置 ,seata 的配置是顶级配置,不是挂在 spring.cloud 下面的配置,和 nacos sentinel 位置不一样,需要顶级写
注册中心:需要注意的是 registry 里面的配置group和 application 需要个前面 seata-server的配置一样,
配置中心:要注意group和 data-id,但是这个配置中心用来干嘛的?
-
seata:
enabled: true
application-id: ${spring.application.name}
tx-service-group: demo_tx_group
registry:
type: nacos
nacos:
application: seata-server
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
username: nacos
password: nacos
config:
type: nacos
nacos:
dataId: seataServer.properties
server-addr: 127.0.0.1:8848
group: SEATA_GROUP
username: nacos
password: nacos
service:
#指定事务分组至集群映射关系(等号右侧的集群名需要与Seata-server注册到Nacos的cluster保持一致)
vgroup-mapping:
demo_tx_group: default
然后再程序的服务层写上@GlobalTransactional 就可以了
正常来说就生效了,如果不生效大概就是数据源的问题,如果提示 找不到服务,就是配置的问题
如果@GlobalTransactional 不生效可以参考我的另外一篇博客 《seata @GlobalTransactional 不生效的问题解决方案》
如果提示 undolog表不存在:在你用本地数据库冲执行 创建 undolog表,用来写undo日志的做回滚的
CREATE TABLE `undo_log` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'increment id',
`branch_id` bigint(20) NOT NULL COMMENT 'branch transaction id',
`xid` varchar(100) NOT NULL COMMENT 'global transaction id',
`context` varchar(128) NOT NULL COMMENT 'undo_log context,such as serialization',
`rollback_info` longblob NOT NULL COMMENT 'rollback info',
`log_status` int(11) NOT NULL COMMENT '0:normal status,1:defense status',
`log_created` datetime NOT NULL COMMENT 'create datetime',
`log_modified` datetime NOT NULL COMMENT 'modify datetime',
`ext` varchar(100) DEFAULT NULL COMMENT 'reserved field',
PRIMARY KEY (`id`),
UNIQUE KEY `ux_undo_log` (`xid`,`branch_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8MB4 COMMENT='AT transaction mode undo table';
- seata的原理
seata 事务生成了一个xid(全局事务Id),调用远程接口的时候把它带过去,同一个xid下面的不同服务器的本地事务类似一个事务组的概念,他们会一起成功或者一起回滚。
AT ( Auto Transaction)模式 的事务回滚依赖于undo日志,不会长时间的把持锁,事务执行到可以提交就直接提交,并且立马可见(如果回滚了,读到的就是脏数据),如果可以接受脏数据,AT是比较好的选着。
XA(eXtended Architecture)模式下,强一致性,锁的时间更长,锁只有在所有事务都达到可以提交的情况才会一起提交并且释放。需要数据库实现XA协议。
TCC事务一个方法写三遍,编程复杂,效率高。效率可能是最高的,编程难度和代码侵入性也是最高的。
SAGA模式,针对长事务的解决方案
- AT 和 XA 事务是全局配置的
seata.data-source-proxy-mode: AT 或者 AX
配置了以后默认使用的全局事务就使用对应方式
-
TCC 事务在数据源代理模式为AT或者XA 配置下都生效
外层依旧需要全局事务注解

内存服务接口定义

服务实现

- SAGA 和AT 事务有点类似,只有正向的do和的undo和AT 模式undo是自动实现的,SAGA里面的UNDO 是程序员自己实现的。一个方法写两遍,并且依赖状态机来确定当前事务状态,因为undo是程序员提供的,不用每个服务都集成saga相关的组件,只需要服务的发起方集成saga状态机,并且通过状态来控制应该走do还是undo。
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2022-07-03 16:39 zhangyukun 阅读(242) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号