各种 垃圾收集器结构和原理
5垃圾收集器 (garbage collection)
1.串行JVM serial
垃圾收集器,也是最早的 垃圾收集器,串行执行回收,如今基本已经没人用了,那时候内存小,即便并行也可以很快完成回收
年轻代使用 serial
老年代使用 serial old
2.并行JVM parallel
垃圾收集器,并行收集,对象池并行收集垃圾,但是不是并发,收集垃圾的时候会停止业务线程,目前依旧是主流。JDK8 默认使的parallel
年轻代使用 parallel scavenge
老年代使用 parallel old
触发GC条件是当前分代区域满了
3.并发JVM CMS(Concurrent Mark-Sweep Collector)
并发收集,收集垃圾的大部分时间都不会阻塞业务线程。JDK1.4的时候诞生,JDK 14的时候删除
三色算法:
在对象头上面用2位来存放 黑白灰 标志 状态,一次GC的过程中,可达性分析策略通过GC root 向下找,初始所有节点都是白色,找到的对象标记成灰色,如果一个对象的所有子节点都已经找到,那么就标记成黑色。
gc的GC的过程不是一次走完,也不是一个线程,并发标记每次都是从灰色节点开始向下找。直到有用节点都标记完成(不存在灰色节点)并发标记结束,开整理有用对象(黑色对象被移动到区域的一边),并且清除无效区域(直接格式化没有另外一边)。
浮动垃圾:
1.在垃圾回收过程中已经标记过的黑色节点,由于业务的线程的运行变成不可达了,这种节点就是浮动垃圾
2.比如黑色节点A和黑色子子节点a,如果A.a = null,那么a就变成了浮动垃圾,这种垃圾本次垃圾回收过程中无法感知,依旧会被整理到不删除区域,只有下次GC才能删除。
3.浮动垃圾只是影响GC的回收率,并不会导致程序错误,如果要不产生浮动垃圾,只能在GC 的时候,停止业务线程,相对STW带来的影响,浮动垃圾完全可以接受。
写屏障( Incremental Update write barrier ):
目的是为了解决漏标的问题,三色标记算法中,白色节点指向黑色节点的时候,会把黑色节点设置成灰色,这样这个灰色节点下面的白色节点就会被重新扫描,而不是漏标。
写屏障漏标问题:
1 如果一个灰色节点有多子节点,并且出来了最后一个子节点还没有被扫描过(白色),别的都已经扫描过(灰色或者黑色)。
2 这时候如果有一个任意白色节点指向这个主节点已经扫描过的子节点,这个主节点本来就是灰色,保持不变,新来的子节点保持白色(如果不再次被扫描会被删除)
3 然后这个节点的最后一个白色节点被扫描,这个主节点被标记成黑色。黑色的主节点不本次标记过程中不会被再次扫描,标记完成以后新来的白色节点会被删除
4 上面问题是一个严重的bug,毕竟可达对象被清除了,程序会错误,这问题是致命的,所以只能重新标记,重新标记的过程中必须STW,防止再次出现漏标被删除的情况。
三色算法标记过程:
初始标记(STW)-->并发标记(不会STW)->重新标记(STW,为了解决写屏障漏标问题)-->并发清除(不会STW)
CMS最大的问题就是重新标记带来的STW次要问题是浮动垃圾必须下次GC才能清除,这些问题在G1中得到了解决
触发GC条件是当前分代区域使用比例达到一定程度,如果预留的空间不够,GC过程中可用内存就满了只能STW,并且这种STW比较长。
4.G1 (Grabage-First Collector)
介绍:开始使用分区(region)内存模型,并且也有逻辑上的内存分代,JDK7首次使用,JDK9 默认使用G1
SATB(snapshot at the begining ):代替增量更新,随便解决浮动垃圾
解决了浮动垃圾问题和重新标记需要STW问题,相当于把在黑色节点指向变动的时候,找个地方记录下来,待会看看这些变动里面有没有漏标和 浮动懂垃圾就行了。
有两种情况需要记录:
浮动垃圾,黑色节点连着父级指向它的引用断开
可能漏标漏标的情况,白色节点指向一个灰色节点
卡表,卡页,记录集:用于解决跨代引用
对于跨带引用,会在老年代中有一个地方记录这区域是否有对象指向年轻代。老年代被分成卡页,用一个字节数组表示卡页是否有跨带引用,如果有,这种页就是脏页,年轻代GC的时候GCroot 中 就要包含这些 脏页。
记录集的实现就是卡表,一个 类似比特数组的结构,里面用0,1 标记这卡页是否有跨带引用。
G1 默认把对内存分成 2048 个区,G1 年轻代 默认5% 最多 60% ,年轻代eden 和 survivor 依旧还是默认8:1:1,G1 年轻代默认5% 不是说老年代95%,而是 空余了很多未使用的区域。后面年轻代区域会逐步上升,知道达到最大比例。
G1 内存分区图
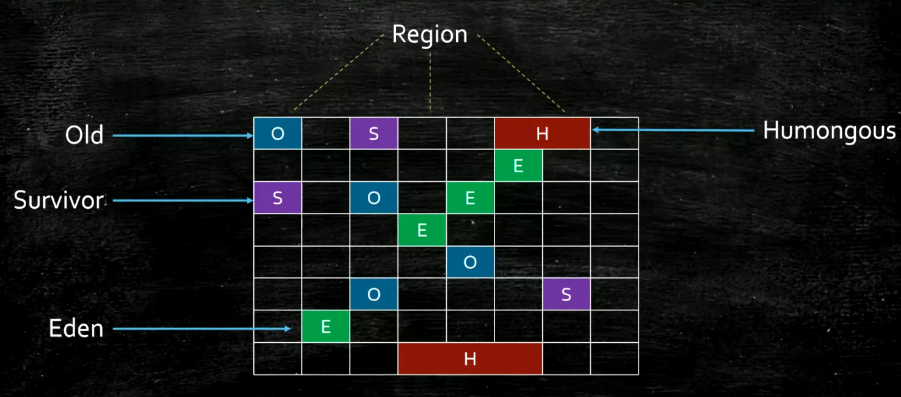
G1 有特殊的Humongous 区,用来存放大对象,超过半个区的 对象会被直接分配到Humongous 区
触发GC是当前region满了,直接把有用对象复制到其他同代的区域,然后直接格式化当前区域。
G1 回收不用回收全部堆,而是通过 估算停顿时间,然后回收部份回收全部region ,G1 默认最大停顿时间 200毫秒,分区模型以后,使用的基本都是 标记然后复制到别的分区,之前分代模型的GC年轻代使用复制算法,老年代使用标记压缩和这标记清除。
G1 并发清除阶段会STW,但是因为设置了最大停顿时间,所以不用一次全都清理完成,待会在清理就行了。
G1 三个GC 级别 YongGc ,MixGC(类似 CMS 的 FullGC), FullGc(STW,单线程回收,最大停顿时间会被打破),是一次完整的GC,耗时很长,FullGc是MixGC 的过程中,没有可用空区域才会触发,
正常我们设置合理的老年代GCMixGC的比例不要太高,停顿时间不要太短就可以尽量避免FullGC
5.ZGC
介绍:java 11 才第一次引入的,并且是实验性质版本,完全放弃分代模型,只有分区,并且不建议商用,带优化的空间比较大,是JVM发展的方向。ZGC目前完全没有分代的概念,并且只支持64位指针,只适合大内存的情况,并且最大支持4TB内存,并且每次STW 的时间控制在10毫秒以内,并且把复杂算法带来的性能下降比例控制在15% 以内。目前使用 parallel 和 G1 依旧是主流。小公司 parallel 足够,大公司 G1 足够,CMS 基本很少用,ZGC 大概 JDK17 才敢用。
染色指针:
在64位对象指针种分2位出来作为最为标记,1位用来存放对象指向的地址是否需要去变动表里面获取新的地址。
读屏障(Load Barrier):
ZGC 读屏障,对象复制 以后,在指针上面做好标记已经变动,下次访问这个对象的时候,直接更新到新的对象地址。(类似预惰性修改,下次查询的时候我们在真实的去修改指正指向第新地址就行了就行了,)
6.其他JVM shenandoah,epsilon
shenandoah:JDK12加入的新GC ,G1 基础上的升级版,解决了 并发删除的 STW 等一些问题。
epsilon:JDK11 和 ZGC 一起退出的版本,没有ZGC出名 没研究,估计也是G1 的升级版
3种 垃圾回收算法(GC algorithm )
1.复制算法(copying 复制算法),适合青年代,虽然STW,但是时间特别短,CMS 青年代也是用的 复制算法。
包内存分成2块,每次只用一块,每次把有用的对象复制到另外没用的一边,然后把当前这边全部清除。缺点是空间利用率比较低,优点是非常快
复制算法,不需要标记,直接遍历复制就行了,标记算法,扫描到标记灰色,子节点扫描玩,把父节点标记成黑色,后面整理的时候需要移动空着位置,没有整块删除快。
2.标记清除( Mark-Sweep ),适合老年代
先标记有用对象,然后把垃圾对象都清除掉,缺点会内存碎片化严重,不容易找到一块足够大的连续内存空间来存放新来的大对象。
3.标记压缩(Mark-Compact),适合老年代
标记有用对象,然后把他们移动到内存区域的一头(压缩空间),然后把另外另外的一头全都清除。缺点最费时。
确定一个对象是不是垃圾的2种办法
1.引用计数法
对象被引用一次计数器就+1,断开一个引用就-1,如果这个计数器变成0,就表示改对象是垃圾,循环引用情况下,计数器永远不会是0.
2.可达性分析法
通过GC root 向下找,能找到的就标记不是垃圾,其他都是垃圾。 一般都是这种,缺点标记过程比较慢
并发标记2种方式
1.三色算法
在对象头上面用2位来存放 黑白灰 标志 状态
2.染色指针
在64位对象指针种分2位出来作为最为标记,1位用来存放删除状态
分代模型内存模型图:

上图有 分代模型 和 各年代所占比例 和 使用的算法
一般对象在分代模型中的传递过程: eden --> (survivor1<-->survivor2)--old
对象头上有回收了几次依旧存活额计数器
CMS 默认存活6次进入老年区,serial,parallel,G1 都是 16次(这个对象头计数器应该只有4位,最多只有16次,进入老年区以后计数器就没用了,没有更高级的存活区域)
对象分配过程
1 优先栈上分配,做了逃逸分析以后,没有逃出局部变量控制范围的对象,会被分配到栈上。栈上的对象会随着方法结束栈帧被销毁直接释放。不许进入堆内存。
2 逃逸分析结果是被有可能 赋值给成员变量,返回值,下一个方法的实参的对象,会堆上分配,堆上分配优先分配到 本地线程分配缓存区(LTAB)。
3 线程本地分配缓冲区是eden区域里面给每个线程独立划分的一小块空间,多线程分配避免内存竞争同一块空间,所以每个线程在eden区有一块线程独占区
4 大对象直接进入老年区。有一个JVM 参数决定多大对象直接进入老年区。
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2022-06-17 21:52 zhangyukun 阅读(356) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号