kafka 原理和总结
首先kafka 和 rocketmq 机制非常类型
kafuka结构图(来源网络)
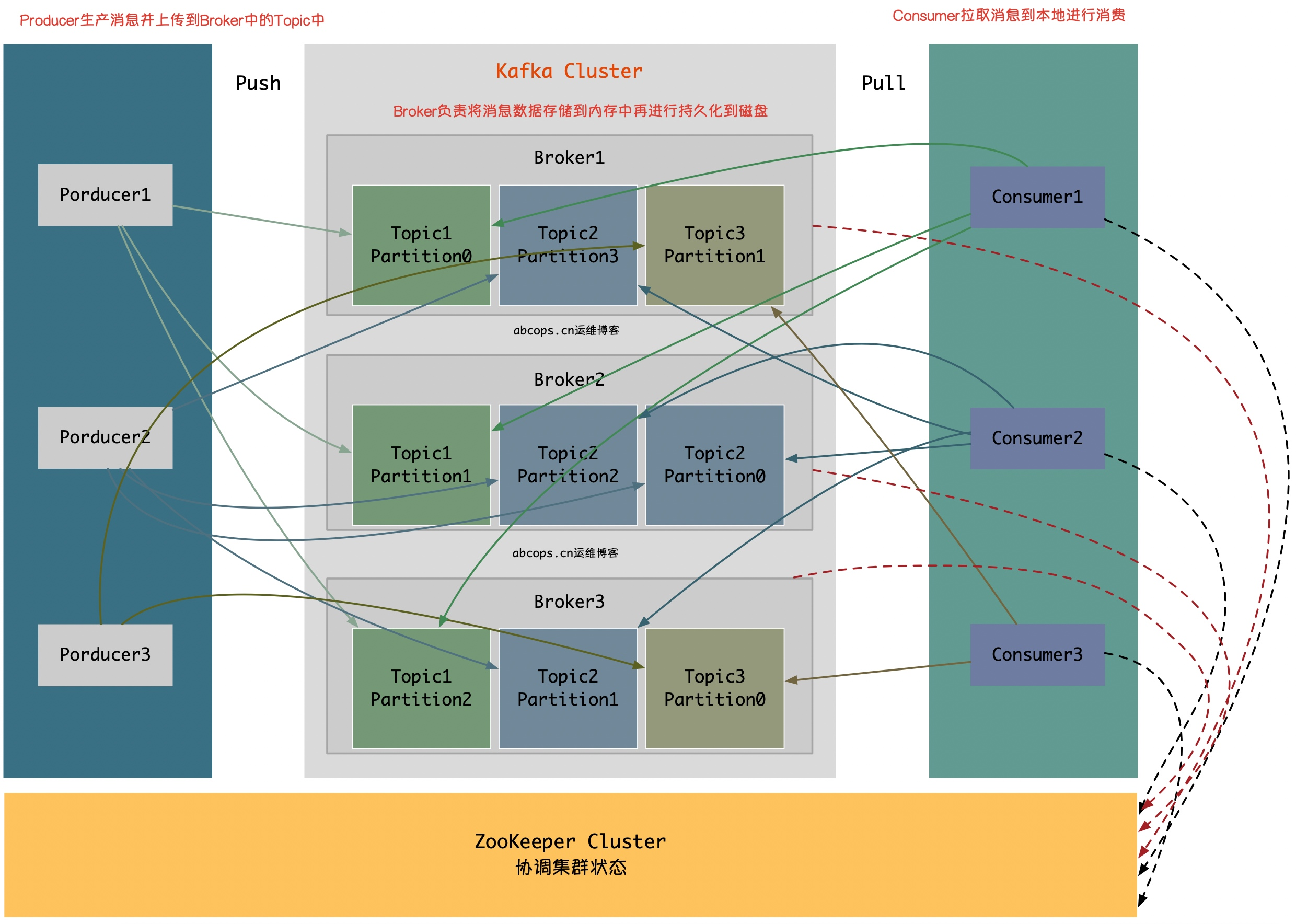
kafka中集群中的角色名词解释和作用
1 broker mq服务节点
2 producter 生产者
3 consumer 消费者
4 ISR (In-Sync Replicas) kafka 处于据同步的副本(节点),并不是说别的节点不同步,而是应为别的节点同步太慢,如果等待它们响应会拖慢集群的数据。
同步速度不达标的叫做OSR(out-Sync Replicas),两者加一起就是AR(all Replicas),如果OSR同步速度更上了,它会就会变成ISR。
5 offset 消息偏移量(可以理解成kafka消息下标,或者消息id,超过最大值以后会重置位0)
6 HW (High Watermark)高水位 ,副本 节点数据不一致的时候,共有offset 的最大值。
7 LEO (Log End Offset) 最大的一个offset, 副本节点数据不一致的时候,offset 的最大值,leader 挂掉以后 重新选举到数据完成同步的过程中,HW 到 LEO 之间的消息,消费者是访问不到的,直到数据同步完成,完成同步之前只能访问到高水位。这样可以保证发送broker 保存数据的一致性。
8 partition 分区,用作数据切片,kafka 对于一个主题的数据可以分成拆分成多分存储,从而提高写入速度,分区数 类似rocketmq 一个topic下面的的队列数量
9 replicas 副本,用作数据备份,为了数据安全,同样的数据可以保存多分,每一份都是一份副本
10 topic 主题 ,一个虚拟的概念,生产者向主题发送消息,消费者 订阅主题接受消息,发送到主题的消息 会按照分区切片,每个数据片 可以有多个副本
11 Leader 副本数据的主节点
12 Follower 副本数据的从节点
13 Controller borker中的 一个,某台Broker一旦成为Controller,它用于以下权力:完成对集群成员管理、主题维护和分区的管理,如集群broker信息、Topic维护、Partition维护、分区选举ISR、同步元信息给其他Broker等
kafka的运行机制和一些注意点
1 kafka 有一个独立的消息发送线程,主线程把消息传递给消息发送线程,然后小法发送线程积累一定量的消息或者等待一定时间后会异步的这批消息发送出去。
2 kafka 的消息发送发送是异步的,如果要同步发送需要把linger.ms设置位0(默认就是0),并且生产者那边需要使用 Future对象的get 方法阻塞主线程才能达到同步发送的效果。
3 如果需要高吞吐量,并且不在乎少量数据的丢失,可以配置+批量异步延时发送,大大的提高吞吐量(比如日志收集)。
4 如果异步发送,那么主线程就不知道消息发送的结果,这时候暂存的消息可能因为重启丢失,也可能应为borker 集群不可用,发送失败,但是这一切主线程都不知道。
5 如果需要消息可靠,那么必须要让主线程确认消息发送成功才继续,所以只能设置立即发送,并且主线程等待监听结果后再继续。并且需要配置生产者acks=all,确保发送消息0丢失。
6 生产者发送消息 acks 有三种模式
0 只管发,只要能正常建立连接,并且把数据发出去就完事,不等待broker的返回,不会重试,关于重试的配置都无效(效率最高,比如你不太关系日志因为网络波动丢几条 )
1 发送消息以后 leader 确认收到消息后返回成功才算ack,否者重试。(这时候 follower 副本并没有同步完成,如果 leader 挂科了,controller 控制下重新选出新的 leader,高水位位置以下没有这个消息,这个消息就丢失了),比如你不能忍受因为网络波动丢数据,但是可以忍受mq server 重启丢数据
-1/all 等待当前主题所有同步数据节点(ISR)收到消息以后才完成才算发送成功,否者重试。
7 ISR 选举策略,老版本有2种策略,分别是看消息offset差值和时间偏移量差值(默认差距10 秒以上就踢出ISR),新版本只保留了时间差值,原因是批量发送可能一批的消息数量就大于课这个 offset。
8 生产者 acks=all的时候,使用的 ISR 节点而不是所有副本所在节点,是为了提高相应速度,不能让太慢的节点拖满相应速度。并且 OUR 节点不会参与 leader的选举。
9 kafka 的消费者必须设置消费组,同一个主题的消息,在消费者组里面只会被一个消费者消费(除非,没有ack的消息,并且出发了消费者的重新分配(重启或者节点的变化))
如果消费者没有ack,就宕机了,那么这个消息还会被别的消费消费,如果还有别的消费者就被别的消费消费,如果没有就下一次重启完成以后开始重复消费。
10 消息的消费是消费者组维度的,也是就是说一个主题被多个消费者 组的消费者订阅,那么每个组都会收到一条这样的消息,并且组内只有一个消费者会消费这条消息。
11 同一个消费者组里面的不同消费者,可以订阅不同的主题(我觉得正常人都不会这么干,这样会显得很混乱 ),kafka的消息消费分配策略有两种一种是range(默认),一种是roundRobin
range:按照每一个主题的分区数,然后指定组内消费者消费指定主题的哪些分区(可以兼容同一个消费者组里面不同消费者订阅不同主题的情况)
roundRobin:把组内所有主题的所有分区,当成一个整体,分配给组内的每一个消费者。(这种明显更加均匀)
12 组内的消费者数量不应该多余主题的分区数,一个分区只能被一个消费者消费,多了消费只能闲着(注意是组内,不同组不存在这个问题)。
13 kafka 偏移量重置,发生在 有新的消费者组第一加入的时候,或者老的消费者组,太久没上线offset标记的消息已经被删除了的时候
auto.offset.reset=earliest 重置到现在可以消费的最小偏移量
auto.offset.reset=latest 重置到现在可以消费的最大的偏移量上
14 kafka消息的确认都是批量的,一批拉取过来的消息一起确认,不能单个确认
消费者消息确认有三种方式 延时自动确认,异步手动确认,同步手动确认(需要消费消息只能是同步手动确认),异步和自动不知道后续业务流程是否正常执行就把消息确认,这个消息业务逻辑就再也感知不到了。
15 消费者 offset 位置存储,
实现ConsumerRebalanceListener类,这类会在 消费者组重新分配分区给消费者的时候 调用里面的末班方法读取 offset 的位置(可以精确到一条消息,默认的 同步确认只能精确一次拉取的批量 ),如果我们offset 的值 和业务逻辑通过一个事物写到数据库,并且在消费者组重新分配分区给消费者的时候读取到这个值,就可以避免消息的重复消费,保证消费的幂等。
16 顺序消息
生产者有序性:使用顺序消息必须指定分区,也就是在一个分区内有序,如果你想整个topic消息都是有序的,那么只能给这个topic 设置一个分区,如果你只需要局部有序(对应的业务场景是同一个业务内需要有序,不同业务直接可以无序),那么你可以设置多个分区
消费者有序性:一个分区只会被一个消费者消费,并且是顺序消费。
rocketmq的顺序消息也是这样的。
17 kafka生产 拦截器 系列化器 分区器 执行顺序 拦截器>系列化器 > 分区器,他们的作用和名字一样
默认分区器是轮询的,但是开始位置是随机的。我们发送消息的时候可以指定分区,也可以通过指定key来指定分区(key的哈希值模分区数量),指定分区,比key优先。
18 生产发送消息的幂等
发送幂等消息是通过 producer id+给每条消息 在通过分区器的时候会产生一个唯一的 SequenceNumber来实现的,这样发送到同一个分区的同一个消息会被过滤(你程序发了两次消息对象 不会被过滤 ),重启 生产id 会变化变化,SequenceNumber也可能重复,者时候幂等性会被打破
打破的原因可能是把我们的2条消息当成一条消息,过滤了(重启后正好有个生产id和之前存在的一样,并且SequenceNumber也一样)
有些说是这条消息用不同的生产id发出去产生了两条,我感觉应该不可能,因为SequenceNumber 不是伴随消息对象产的,而是在 通过 分区器的时候产生的,重启以后这条消息不可能被重发。
需要设置 enable.idempotence=true(这时候 会强制 acks=all ,MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1,retries也会默认设置位大于0)
19 kafka 的事物消息
需要设置全局唯一的 transactional.id,kafka 会通过事务id 产生生产者id
并且在使用 sendOffsetsToTransaction 方法发送事务消息。
kafka 的事务消息依赖于消息的幂等性,只要设置了 transactional.id ,enable.idempotence就强制等于true
事务消息的原理,kafka 没有rocketmq的预消息(分两段,一段发送,一段确认,没有确认的消息不会被消费),它只是把消息放到事务的提交前夕,如果业务代码异常,就不发送,如果发送失败,就让已经整个事务一起回滚。
rocketmq 的 预消息,是在业务的过程中发送预消息,然后再事务提交的是确认,并且允许确认的时候网络出现问题,业务事务提交以后,可以通过又borker向生产所在组的任何节点发起查询,确认这个预消息应该被舍弃,还是投递。所以kafka 没有生产者组,rocketmq 有生产者组的概念。
20 kafka 精确一次性消息是怎么保证的
生产消息幂等性+(acks=all)+ (HW,LEO多节点数据同步方案)= exactly once (精确一次性投递消息)。
21 kafka 的消费者只能通过主动拉取的方式获取消息(轮询拉取,设置了一个间隔时间),不能通过被动推送获取消息。延时比较高。rocketmq是推拉结合,有一个长连接告诉是否有新的消息,然后由一个轮询线程拉取消息到本地,在推给监听消息的接口。
纯推送消费者是被动接受,没有兼顾到它的消费压力,纯拉取延时高rocketmq的做法兼顾的消费者消费能力和消息的及时性。
22 生产者业务线程发送消息以后,这些消息堆积在记录累积器(RecordAccumulator)里面,直到数量达到一定的程度,或者等待时间达到一定程度才有发送线程投递出去。
23 kafka 数据存储和索引方式
存了2分种 文件,一种 索引文件(.index文件),一种消息文件(.log文件),消息文件和索引文件的命名是通过里面内容的offset 的最大值来命名的,索引文件里面 按照offset值排序作为索引key,索引值是消息文件里面对应消息的开始位置。数据文件里面连的存储者多条消息内容,所以的时候只要通过offset 和 offset 的下一个值就能直接取出一个完整的消息。
查找过程,通过offset 找到 对应的两个文件,然后通过 offset 找到 确定的消息。
------------------------------------------------------------------------------代码例子------------------------------------------------------------------------------
Java客户端使用kafka的基本使用
1 导入配置:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>3.2.0</version> </dependency>
2 创建一个生产者类
package com.lomi.kafka;
import java.util.List;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
public class KafkaProducerTest {
public static String topicName = "topic3";
Properties properties = new Properties();
{
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.200:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
}
/**
* 同步发送(并且拿到消息回调)
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void sysnsend() throws InterruptedException, ExecutionException {
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
producer.send(new ProducerRecord<String, String>(topicName, "Message", "我发送了一条同步消息"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
System.out.println(metadata.serializedKeySize());
System.out.println(metadata.serializedValueSize());
}
}).get();
producer.close();
}
/**
* 异步发送 1秒钟
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void asynsend() throws InterruptedException, ExecutionException {
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
long start = System.currentTimeMillis();
int i = 0;
for(;System.currentTimeMillis()-start < 1000;) {
producer.send(new ProducerRecord<String, String>(topicName, "Message", "我发送了一条消息"+i++));
}
producer.close();
}
/**
* 发送消息的ack(最少一次,并且同步发送)
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void ack() throws InterruptedException, ExecutionException {
//设置为最少一次
properties.put(ProducerConfig.ACKS_CONFIG, "all");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
producer.send(new ProducerRecord<String, String>(topicName, "Message", "我发送了一条消息同步"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
System.out.println(metadata.serializedKeySize());
System.out.println(metadata.serializedValueSize());
}
}).get();
producer.close();
}
/**
* 发送幂等消息(会默认开启,最少一次)
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void idempotenceMsg() throws InterruptedException, ExecutionException {
//设置为最少一次
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, "true");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
producer.send(new ProducerRecord<String, String>(topicName, "Message", "我发送了一条幂等消息"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
System.out.println(metadata.serializedKeySize());
System.out.println(metadata.serializedValueSize());
}
}).get();
producer.close();
}
/**
* 发送有序消息
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void orderlyMsg() throws InterruptedException, ExecutionException {
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
//顺序消息需要指定分区,或者key
List<PartitionInfo> partitions = producer.partitionsFor(topicName);
producer.send(new ProducerRecord<String, String>(topicName,partitions.get(0).partition(), "Message", "我发送了一条顺序消息1"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
System.out.println(metadata.serializedKeySize());
System.out.println(metadata.serializedValueSize());
}
}).get();
producer.send(new ProducerRecord<String, String>(topicName,partitions.get(0).partition(), "Message", "我发送了一条顺序消息2"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
System.out.println(metadata.serializedKeySize());
System.out.println(metadata.serializedValueSize());
}
}).get();
producer.close();
}
/**
* 发送幂等消息(会默认开启,最少一次)
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void transactionMsg() throws InterruptedException, ExecutionException {
//设置事务ID
properties.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "transactionID1");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
producer.initTransactions();
producer.beginTransaction();
producer.send(new ProducerRecord<String, String>(topicName, "Message", "我发送了一条事务消息"), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
System.out.println(metadata.partition());
System.out.println(metadata.offset());
System.out.println(metadata.topic());
System.out.println(metadata.serializedKeySize());
System.out.println(metadata.serializedValueSize());
}
}).get();
//producer.commitTransaction();
producer.close();
}
}
3 创建一个消费者类
package com.lomi.kafka;
import java.time.Duration;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.clients.consumer.OffsetCommitCallback;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
public class KafkaConsumerTest {
String GROUPID = "groupE";
Properties properties = new Properties();
{
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.200:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
}
/**
* 自动确认消息
*
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void AUTO_COMMIT() throws InterruptedException, ExecutionException {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.200:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUPID);
//自动(效率最高)
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
//自动确认时间
properties.put("auto.commit.interval.ms", "1000");
properties.put("session.timeout.ms", "30000");
properties.put("auto.offset.reset", "latest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList(KafkaProducerTest.topicName));
int messageNo = 1;
System.out.println("---------开始消费---------");
for (;;) {
ConsumerRecords<String, String> msgList = consumer.poll(Duration.ofMillis(200));
for (ConsumerRecord<String, String> record : msgList) {
System.out.println(messageNo + "=======receive: key = " + record.key() + ", value = "+ record.value() + " offset===" + record.offset());
messageNo++;
}
}
//consumer.close();
}
/**
* 同步确认消息
*
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void commitSync() throws InterruptedException, ExecutionException {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.200:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUPID);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
properties.put("auto.commit.interval.ms", "1000");
properties.put("session.timeout.ms", "30000");
properties.put("auto.offset.reset", "latest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList(KafkaProducerTest.topicName));
int messageNo = 1;
System.out.println("---------开始消费---------");
for (;;) {
ConsumerRecords<String, String> msgList = consumer.poll(Duration.ofMillis(200));
for (ConsumerRecord<String, String> record : msgList) {
System.out.println(messageNo + "=======receive: key = " + record.key() + ", value = "+ record.value() + " offset===" + record.offset());
messageNo++;
}
if( !msgList.isEmpty() ) {
consumer.commitSync();
}
}
//consumer.close();
}
/**
* 异步确认消息
*
* @throws InterruptedException
* @throws ExecutionException
*/
@Test
public void commitAsync() throws InterruptedException, ExecutionException {
Properties properties = new Properties();
properties.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.1.200:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, GROUPID);
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
properties.put("auto.commit.interval.ms", "1000");
properties.put("session.timeout.ms", "30000");
properties.put("auto.offset.reset", "latest");
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(properties);
consumer.subscribe(Arrays.asList(KafkaProducerTest.topicName));
int messageNo = 1;
System.out.println("---------开始消费---------");
for (;;) {
ConsumerRecords<String, String> msgList = consumer.poll(Duration.ofMillis(200));
for (ConsumerRecord<String, String> record : msgList) {
System.out.println(messageNo + "=======receive: key = " + record.key() + ", value = "+ record.value() + " offset===" + record.offset());
messageNo++;
}
if( !msgList.isEmpty() ) {
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
System.out.println("异步确认");
}
});
}
}
//consumer.close();
}
}
4 kafka 开启事务消息,导致 spring事务管理员失效的问题
1 开始方式(配置了事务ID才能发送事务消息,开启以后在默写版本的spring里面会导致 原始的 事务管理员失效)
kafka:
bootstrap-servers:
- 192.168.1.200:9092
producer:
transaction-id-prefix: demo-tran-
2 处理事务管理员失效
package com.lomi.config;
import javax.sql.DataSource;
import org.springframework.beans.factory.ObjectProvider;
import org.springframework.boot.autoconfigure.jdbc.DataSourceProperties;
import org.springframework.boot.autoconfigure.transaction.TransactionManagerCustomizers;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.data.transaction.ChainedTransactionManager;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.kafka.transaction.KafkaTransactionManager;
/**
* 开启kafka 的事务消息,会导致 spring 的 事务管理员不初始化,全局都没有事务了,这个类特殊处理这个情况
*
* @author ZHANGYUKUN
* @date 2022年5月29日 下午6:53:50
*
*/
@Configuration
public class KafkaTransactionConfig {
private final DataSource dataSource;
private final TransactionManagerCustomizers transactionManagerCustomizers;
KafkaTransactionConfig(DataSource dataSource,ObjectProvider<TransactionManagerCustomizers> transactionManagerCustomizers) {
this.dataSource = dataSource;
this.transactionManagerCustomizers = transactionManagerCustomizers.getIfAvailable();
}
/**
* 导入kafka 事务消息以后原始 DataSourceTransactionManager 失效了,我们给它手动初始化一个
* @param properties
* @return
*/
@Bean
@Primary
public DataSourceTransactionManager transactionManager(DataSourceProperties properties) {
DataSourceTransactionManager transactionManager = new DataSourceTransactionManager(this.dataSource);
if (this.transactionManagerCustomizers != null) {
this.transactionManagerCustomizers.customize(transactionManager);
}
return transactionManager;
}
/**
* 定义一个兼容kafka和DB 事务的 事务管理员
* @param transactionManager
* @param kafkaTransactionManager
* @return
*/
@Bean
public ChainedTransactionManager kafkaAndDBTransactionManager(DataSourceTransactionManager transactionManager,
KafkaTransactionManager<?, ?> kafkaTransactionManager) {
return new ChainedTransactionManager(transactionManager, kafkaTransactionManager);
}
}
3 使用事务消息(不指定事务transactionManager 的还是用的默认的那个)
public static String topicName = "topic3";
@Autowired
KafkaTemplate<String,Object> kafkaTemplate;
@Override
@Transactional(transactionManager ="kafkaAndDBTransactionManager")
public void transationKafkaMsg(Goods goods,Boolean throwException) throws Exception {
// 设置事务ID
kafkaTemplate.send( topicName ,JSONObject.toJSONString( goods ) );
goodsExMapper.insert(goods);
// producer.commitTransaction();
if( throwException ) {
throw new RuntimeException("故意抛出一次");
}
}
cup r5 2600 16G内存,kafka ,zookeeper,生产者,消费者在一台机子上,只有一个节点,只有一个分区的情况下,10 秒约 可以产生并且消费500百万条简单消息。吞吐量惊人。
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2022-05-27 20:40 zhangyukun 阅读(160) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号