
mongo 语法总结
1 mongo 一个分布式无模式文档数据库
2 mongo Collection相当于 mymsql 的 表, docment 相当于 mysql 的行,mongo 的 docment 是无模式的,每一行都可以 是不同格式。
3 mongo 单个 docment 最大长度 默认是 16M 。如果要使用 16M 以上的 需要 使用 GridFS
4 文档的最大嵌套数为 100
5 名字空间长度限制:包括数据库与集合名称,总共不能超过123字节
6 mongo的 一些限制:https://www.cnblogs.com/chang290/p/3437527.html
7 创建一个集合
db.createCollection("aaa")
或者直接插入 db.集合名字.insert( {}) ,会创建 集合并且插入一条数据。
8 capped 的集合 : 有上限 , 一个是数据量的上限,一个是文档数量的上限。 超过这个上限会自动删除老的数据。

备注:capped 的 集合 不能删除中间的文档,只能自动清除或者全部清除。并且默认有一个索引。
9 mongodb 的 存储 引擎 有 wiredtiger 和 mmap 3.0 后才有 wiredTiger ,并且默认就是这个
10 mongo使用的 数据类型是 bson
bson 包含的数据类型有
Each BSON type has both integer and string identifiers as listed in the following table:
| Type | Number | Alias | Notes |
|---|---|---|---|
| Double | 1 | “double” | |
| String | 2 | “string” | |
| Object | 3 | “object” | |
| Array | 4 | “array” | |
| Binary data | 5 | “binData” | |
| Undefined | 6 | “undefined” | Deprecated. |
| ObjectId | 7 | “objectId” | |
| Boolean | 8 | “bool” | |
| Date | 9 | “date” | |
| Null | 10 | “null” | |
| Regular Expression | 11 | “regex” | |
| DBPointer | 12 | “dbPointer” | Deprecated. |
| JavaScript | 13 | “javascript” | |
| Symbol | 14 | “symbol” | Deprecated. |
| JavaScript (with scope) | 15 | “javascriptWithScope” | |
| 32-bit integer | 16 | “int” | |
| Timestamp | 17 | “timestamp” | |
| 64-bit integer | 18 | “long” | |
| Decimal128 | 19 | “decimal” | New in version 3.4. |
| Min key | -1 | “minKey” | |
| Max key | 127 | “maxKey” |
备注:mongo 默认的 数字类型是 double , db.user.insert( { age:1 } ) 这时候的 age 是 1 是 小数 ,如果要是用整数 应该用 NumberInt(1) , 这样的 的值才是整数。
db.user.insert( { age: NumberInt(1) } )
11 ObjectId 组成规则: 12 个字节组成。

但是 实际 我们看到的 是 24 位的 16 进制的 Id 。
一个 byte(字节) 是 8个 bit(二进制位),一个 16 进制数 需要 4 个bit表示(2的 4 次方),一个字节可以表示 2 个16 进制数。
12 使用mango 自带 shell 连接
mongo --host host --port port --authenticationDatabase database -u user -p password
或者
mongo host:port/database -u user -p password
13 选着 数据库
show dbs; 查看数据库
use 数据库名字 选着数据库
show collections 查看数据库有哪些 集合;
14 在 自带 shell 里面可以 导入 shell 命令
load("shellPath")
15 查看有哪些命令 db.help()
16 在 mongo shell 中 也可以通多代码的方式,连接 别的 数据库
var mongo = new Mongo("zhangyukun.run:26666");
var db = mongo.getDB("test1");
db.getCollection("User").find();
备注:在 4.13 的 shell 中提示 只支持 到3.6
17 mongo 的 CRUD
1 创建集合
db.createCollection("集合名字");
2 添加
db.集合名字.insert( bjson );
3 查询
db.集合名字.find( bson )
4 更新 ( 部分更新)
db.User.update({
age: 2
}, {
$set: {
age: 3
}
}, {
multi: true
})
备注: $set 是设置一个字段的值, $uset 是删除一个字段的值 , $inc 是 自增
multi:true ,表示不仅仅只是更新第一条,而是 符合调教的都修改,不写 默认是一条
5 创建索引
db.集合.createIndex( {"字段";1}] )
6 删除指定数据
db.user.remove( { bson} ); 删除
db.user.deleteOne({name:1}) 只会删除第一天
db.user.deleteMany({name:1}) 会删除所有
备注:文档上锁的 db.集合.drop() 是删除集合,实测删除了数据库。 慎用。
--------------------------------------------------------------------------------------------------------------查询选中器------------------------------------------------------------------------------------
18 筛选器
or $or:[ {a:1 },{ b:2 } ] db.user.find( {$or:[{ name:"1" },{ name:"2" }]} )
not or $nor 相当于 or 的 取反,用法 db.user.find( {$nor:[{ name:"1" },{ name:"2" }]} )
and db.user.find( {$and:[{ name:"1" },{ age:"2" }]} ) 一般 直接{name:1,age:2} 这么写 但是有些复杂的需要 只有 and 才能搞定
大于 {$gt:1} $gte 大于等于
小于 {$lt:2} $lte 小于等于
$eq 可以用于查询 集合 db.user.find( {"array":{$eq:1} } ) 表示 字段 array 里面 有 1 的 。 如果是简单 字段的 等于 可以是这么写 { "a":1 }
不等于 $ne
in $in
not $not db.user.find( { name: {$not:{$eq:"1"}} } ) 取反
not in $nin
$exists 字段不存在 db.user.find( {name:{$exists:0}} )
模糊查询: 使用正则表达式
{name:/张三/} 名字包含张三
{name:/^张三/} 名字 包含张三开头的
19
排序 sort( { name:1 } ), sort( { name:-1 } ) 分别是正序和倒叙。 1 正序 ,-1倒叙
20 取数量 count()
21 分页
limit(5).skip(10) 取 10 跳后面的 5 条。
22 使用 db.集合.find().explain() 可以做性能分析 同 mysql的 explain 关键字。
explain的三种模式
queryPlanner (默认是这个)
不会真正的执行查询,只是分析查询,选出winning plan。
executionStats
返回winning plan的关键数据,executionTimeMillis该query查询的总体时间。
allPlansExecution
执行所有的plans。
winningPlan.stage 记录了索引使用的 等级
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据索引去检索指定document
SHARD_MERGE:将各个分片返回数据进行merge
SORT:表明在内存中进行了排序
LIMIT:使用limit限制返回数
SKIP:使用skip进行跳过
IDHACK:针对_id进行查询
23 mongo 的字段比较,会比较数据类型,数字和字符串不能混用,
字段是 docment 类型 的 是整个匹配
字段是 array 的, 是用 array 的 没一个分别比较,只要有一个满足就 算 匹配。
24 mongo $in 和 $all 的区别
in 是用 in 的 元素 分别和 原字段 比较( 如果原字段是 array,那么分别和每一个比较 )
all 是整个匹配 ( 或者说 all 要求 all 集合里面的条件 全都 满足 )
这两个都可以用于普通字段和array 字段。正常 普通字段 in ,数组字段根据需求用 in或者 all ,普通字段用 in 和 all 没区别( 如果 all 是 多个元素 就有区别了(总是无法匹配) )。
25 mongo $mod 等于 多少的
db.user.find( { age:{ $mod:[11,0] } } )
26 正则 $regex mongo 的 like 都是通过正则 实现的,值得一提的是 数字类型的字段 正则 筛选无效。 需要字段是 String 类型。
db.user.find( { age:{ $regex: /[0-9]/ } } )
27 $text, $search 配合 全文检索 ,需要建立全文检索 索引 ( 但是 这个不支持 中文分词 ,没啥用 ,只能支持英文检索 )
db.blogs.ensureIndex({title:"text",content:"text"}) //在 title 和 content 上建立索引
下面是几个查询
执行简单的全文检索, text 和 search 都是关键字, 不需要指定搜索字段,加入到全文检索的 字段都会 搜索。
db.blogs.find({$text:{$search:"index"}})查询包含index或者operators的记录
db.blogs.find({$text:{$search:"index operators"}})查询包含mongodb但是不包含search的记录
db.blogs.find({$text:{$search:"mongodb -search"}})查询包含text search词组的记录
db.blogs.find({$text:{$search:"\"text search\""}})
28 $where mongo
db.user.find( {$where:"this.name != this.age"} ) 可以写字符串
db.user.find( {$where:function(){ return this.a == this.b }} ) 可以写一个函数
备注:mongo的 字段可以使 数字开头,这时候引用需要使用 this[字段名]
29 $elemmatch:{$gte:80 ,$lt:50} 筛选数组元素 满足所有的 match 条件。只有有一个能全匹配 ,就是 满足
30 $size 赛选数组元素个数
-----------------------------------update 修改器-----------------------------------
31 $inc 自增 1
{ $inc:{ "字段":1 } }
32 $mul 自乘
语法同上
33 $rename 给字段改名字
语法同上
34 $setOnInsert 如果没有查询到,就 insert ( 只有 upsert:true 的时候才生效,不指定和 false 都不生效 )
db.user.update({ name:110 }, {$setOnInsert:{aaa:1} },{upsert:true})
35 $set 修改指定集合 的指定字段的值 ,增修改。
36 $unset 删除一个 字段
{$unset:{字段:""} }
37 $min 如果 字段的值比当前值小,那么久给它赋值当前的值
{$min :{字段:""} }
38 $max 和min 相反
39 $currentDate 设置 字段为当前时间 ( 需要指定 时间类型 date or timestamp )
db.user.update({ name:100 }, {$currentDate:{aaa:{$type:"date"}} })
----------------------------------------------------------------------------数组相关的update----------------------------------------------------------------------------
40 $数组占位符
db.table.update({"score": 100, "num": 2}, {$set: {"num.$": 9}})
在修改的时候 $ 表示 前面 查询中 num 字段命中的 数组袁术中的一那个的下标。
41 $addToSet 把指定值添加到数组中
db.user.update( {name:"n1"},{ $addToSet :{item:1111} } )
42 $pop 移除 数组的第一个或者最后一个元素
db.user.update( {name:"n1"},{ $pop :{item:-1} } )
43 $pullAll 在数组中 删除
$pull 在数组中删除一个
用法同上
44 push 在数组中添加一个元素
pushAll 在数组中添加一个数组
用法同上
45 $each 遍历后面的没一个数组元素
db.user.update({
_id: ObjectId("5e99151888b48827b80023c3")
}, {
$push: {
name:{ $each: [1, 2, 9, 4]}
}
})
把 1,2,9,4 都加入到 name 字段的数组 尾部
备注:name 只是是 数组
46 $slice 在 a 字段数据尾部 添加 1,3,5,截取钱 5 和元素
db.user.update({
_id: ObjectId("5e99151888b48827b80023c3")
}, {
$push: {
a: {
$each: ["1", "3", "5"],
$slice: 5
}
}
})
备注:$each 必须写,如果只是想截取数组,那么 $each:[]
47 $sort 在添加以后重排序 排序 1 正序,-1 逆序
db.user.update({
_id: ObjectId("5e99151888b48827b80023c3")
}, {
$push: {
a: {
$each:[],
$sort: -1
}
}
})
备注:同上 each 必须写,如果没有添加的写个 空 数组
48 $position 插入的时候,从哪个位置插入( 默认是 数组尾部插入 )
db.user.update({
_id: ObjectId("5e99151888b48827b80023c3")
}, {
$push: {
a: {
$each: [666],
$position: 5
}
}
})
49 $bit 对字段做位 运算 and or xor 分别对应 与 或 亦或
db.user.update({
_id:ObjectId("5e99151888b48827b80023c3")
},{
$bit: {
a: {
and: NumberInt(888)
}
}
})
备注: 参与 bit 的必须是 int32 类型 , 要是用 NumberInt 插入 NumberInt
---------------------------------------------CURD---------------------------------------------
50 插入
db.coll.insert 如果传入一个数组就可以批量插入,有这个就够了
插入多个:db.user.insert( [{},{}] )
db.coll.insertOne 只能插入单个
db.coll.insertMany 里面直接是一个一个 foreach 操作。 只能是数组
51 查询
find
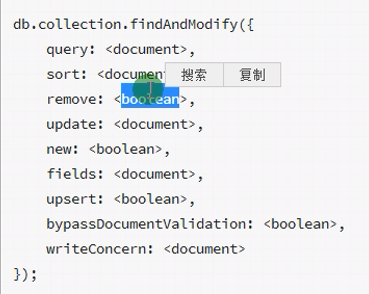
findAndModify 相当于把查询和批量修改 放在一个事务里面 ,下面的都是调用的这个
findOne
findOneAndupdate 修改(增量)
findOneAndReplace 替换(全量)
findOneAndDelete
52 删除
remove 有第二个参数,指定是否只删除一个
db.user.remove([{},{}])
db.user.remove({})
deleteOne 删除一个
deleteMany 删除多个
53 修改
update 增量更新 ,可以指定多条( multi:true )
updateOne 改一个
updateMangy 改多个
replaceOne 覆盖更新
54 bulkWrite 批量的 执行 写入操作,在一个请求中。但是,他们不是一个事务,如果一个失败,别的还是会执行。 主要作用是减少网络带框和请求次数。并且这些 批处理是按顺序执行的。
db.collection.bulkWrite([
{ deleteOne : { "filter" : <document> } }
] )
bulk 还可以 有一个编程 模型
var bulk = db.items.initializeUnorderedBulkOp();
bulk.insert( { item: "abc123", status: "A", defaultQty: 500, points: 5 } );
bulk.insert( { item: "ijk123", status: "A", defaultQty: 100, points: 10 } );
bulk.execute( );

有 无序 和有序 2种的 bulk 对象。
----------------------------------------------------------------索引部分----------------------------------------------------------------
55 创建索引
db.user.createCollection( {name:1} )
在 name 字段上创建索引 ,1 表示正序 ,-1 倒叙
备注: 老版本是 用的 ensureIndex 关键字创建索引。
56 创建复合索引
db.user.createCollection( {name:1,name2:1 } )
57 关于 索引的命中 ,和 mysql 的 索引类似 ,如果 复合索引,那么 查询的时候 顺序不一样 没关系,但是 索引的第一个必字段必须要带上,否者无法命中索引。
58 查看当前有哪些索引
db.user.getIndexes()
59 多键值索引( 数组索引) 用法和 普通索引一样 。只是建立 索引的时候在 数组上创建。 查询的 时候 isMultiKey 会等于 true 。

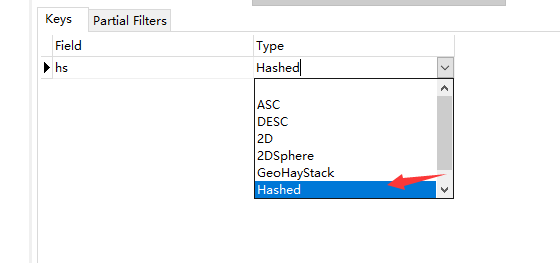
60 hash 索引
key 取 hash ,然后放到类似数组的结构中去。 创建的时候指定类型是hashed 就可以了。hashed 就是为了定值查询。
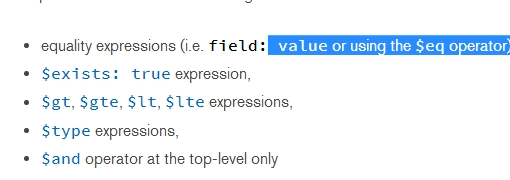
61 局部索引( Partial Indexs ) ,一般的索引都是 全局的 ,这个 值部分数据穿甲 索引。 3.2 以后才有的。通过 第二哥参数指定哪些数据创建索引。 局部索引 可以减少 维护索引的开销

上面的局部索引是在 rating > 5 的数据上 创建索引。
这个查询 支持的 筛选器
62 稀疏索引 ( sparse index ),针对 不规则的文档, 比如 name 字段只有部分 文档才有,全局索引 也会为 没有这字段的文档创建索引, 但是 稀疏索引不会。
稀疏索引是一种特殊的 局部索引。
需要 指定 第二个参数 sparse:true

63 唯一索引 ( unique index ) ,顾名知意 唯一
需要指定参数 unique:true
65 定时过期索引(TTL ) ,需要指定 expireAfterSeconds:多少秒 ,并 不精确误差比较大。后台清楚线程是60 秒执行一次。所以可能过期了 60面还存在。
在一定时间以后 ,活自动删除。

----------------------------------------------------------------索引管理----------------------------------------------------------------
66 索引的 CURD
查询索引:db.user.getIndexes( {"索引名字":1} )
删除索引: db.user.dropIndex( {"字段":1} ) 奇怪的是不能通过 索引名字删除

重建索引
db.集合名字.reIndex() ; 会删除索引,并且重建他们。 数据量大的时候可能开销很大。 慎用。
67 mongo索引 也有 类似 mysql 一样的 索引覆盖, 也就是 查询的 返回的字段都是在 索引中,这样查询效率极高,因为不需要读硬盘。 并且 也和mysql 一样 建议一个索引适配尽可能多的查询。
所以建议 内存一定要 可以完整的包含这个索引。
68 查询一个集合索引的大小,db.user.totalIndexSize() 占用空间的大小。
69 索引在内存还是在硬盘? 答 索引在 硬盘和内存都有。也就是说 最近使用过的索引会在内存,别的可能不在内存。下次使用的时候直接载入需要的索引,然后查询。
70 mongo query plan ??????
------------------------------------------------------------------------------------------------mongo 的分布式文件系统--------------------------------------------------------------------------------------------------------------------------------
71 GridFs mongo 的 分布式文件系统 ( 类似 HDFT ( hadoop 分布式文件系统) TFS( 淘宝分布式文件系统) )
72 使用 mongofiles 或者 语言客户端可以 上传文件。
上传文件命令:mongoFiles -d DBName -l filePath put 文件名
下载文件命令:mongoFiles -d DBName -l filePath get 文件名
文件列表: mongoFiles -d DBName -l filePath list
文件查询:mongoFiles -d DBName -l filePath search 文件名
文件删除:mongoFiles -d DBName delete 文件名
备注 可以通过 --prefix 来指定bucket 名字。 默认 bucket 是fs 。
备注:可以通过 -r 或者 --replace 来覆盖以前都文件(默认是 添加一个新的,但是 老的也存在 )
73 gridFS 存储数据的最小单元是 chunk 一个chunk 是 255 字节KB, 如果衣蛾文件大于 255K ,那么 就会用 多个chunk 来存储这文件。
74 mongo一个 bucket 会有生成 2个集合 比如 名为 bucket1 的 bucket 会生成 bucket1.chunk 和 bucket1.files
chunk 中是文件数据 , files 中是 文件描述信息。
------------------------------------------------------------------------------------------------mongo 聚合管道 --------------------------------------------------------------------------------------------------------------------------------
75 mongo的 $lookUp 可以实现 类似 join 的效果 。
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}
76 $match 类似 where
77 mongo 的 聚合格式
db.collectionName.aggregate( [ 管道1,管道3,管道3 ........ ], { 参数 } )
备注管道是有顺序的,比如第一个管道是 lookup,第二个是 match , 这样就相当于 sql 的 join 然后where
78 $group 分组
第一个 字段是 分组字段,后面的是分组后 使用聚合函数的显示字段
$group:
{
_id: <expression>, // Group By Expression
<field1>: { <accumulator1> : <expression1> },
...
}
}
{
$group: {
_id: "$item",
count: {
$sum: 1
}
}
}
上面是对 item 字段分组,然后 添加一个字段count ,count 的 值是 求个记录条数。
备注:group 和 sort 的聚合操作有 100MB 的限制,需要指定 运行使用 磁盘,才能处理大于100Mb 的 数据。
79 $project 相当于 select a,b,c 选着显示字段部分,可以指定字段不显示,也可以添加新的字段。
{ $project: { "<field1>": 0, "<field2>": 0, ... } }
80 $limit 和 $skip 相当于sql 的 分页
{ $skip: <positive integer> }
{ $limit: <positive integer> }
81 $out 吧结果输出到指定集合,类似 sql 的 吧子查询插入到指定 表
{ $out: "<output-collection>" }
82 轻量级的 group ( 相当于 通过 分组字段 map ,然后 reduce )

备注: result.total 是每个组一份, reduce 是在 每一组内部执行统计。
83 mongo存储引擎。
mmap:只有集合锁,读读效率比较高。
wiretiger: 有文档锁,写效率比较高
inmomory: 纯内存的
mongo 3.0以前只有 mmap,3.0 开始有wiretiger ,3.2 以后默认使用存储引擎就是 wiretigrt;
84 mongo的 集群
1 mater slave 主从 ,主写,从读,主死了,从不会顶上。 同步时间是10 秒,也就是有10 秒的延迟。
通过 oplong 复制 到slave
2 reqlica set 可以自动选举 和主从 差不多。都是一主 多从。 每个节点都有完整的 数据。
3 sharding 数据拆分,负载分摊。一个完整的高可用配置至少需要12 台服务器( mongo 是对指定数据库分片 ,别的数据不分)
mongos,configServer ,mongod shard 2个。 这4 种个 3 三。
数据分片的三种方式:
1 range 范围分片
2 hash 2的 14 次方个槽位,通过hash 算法决定 。
3 tag 手动指定
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2020-04-11 17:14 zhangyukun 阅读(3126) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号