mysql 索引优化 性能调优 锁
1 检查mysql 是否安装 rpm -qa|grep -i mysql
2 ntsysv 查看和设置开机启动列表
3 mysql 在 centos 上默认 的数据目录是 /var/lib/mysql
4 mysql 默认 安装配置文件在 /etc/my.cnf
5 mysql 命令所在目录 /usr/bin
6 mysql 默认 配置文件 位置 /usr/share/mysql
7 查询mysql 编码 show VARIABLES LIKE '%char%'
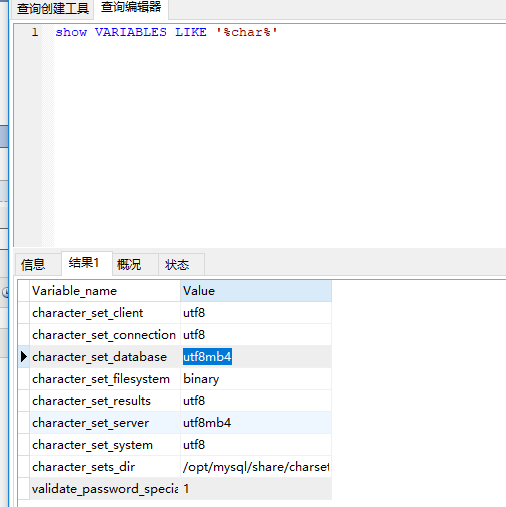
8 修改字符 在 /etc/my.cnf 里面 指定
上面的 那些参数
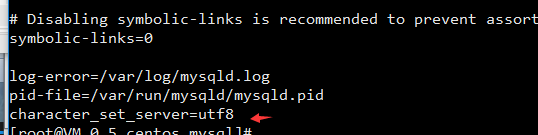
备注:如果在改编码之前建立的数据库 编码不生效。这时候重启数据库以后应该新建库。
9 mysql 的主要配置文件
log-bin 二进制日志文件--> 主从复制
log-error 错误日志,启动关闭日志 默认关闭的
log 查询日志 默认关闭的 记录查询语句
数据文件 /var/lib/mysql 一个数据库一个文件夹
frm 文件 存放表结构
myd文件 表数据
myi文件 表索引
10 mysql 架构图
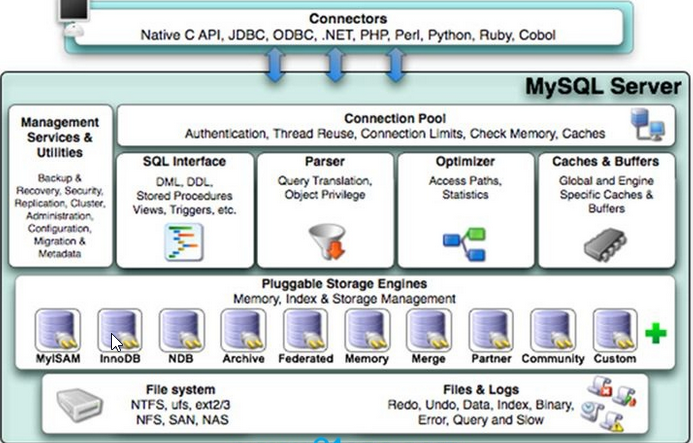
上面 阀盖分4 层 , 1 连接层 2 服务层 3引擎层 4存储层
11 常用 存储引擎 innodb ,myisam
innodb :改并发,偏向写
myisam:偏向读,纯读别 innodb快。写并发很低。
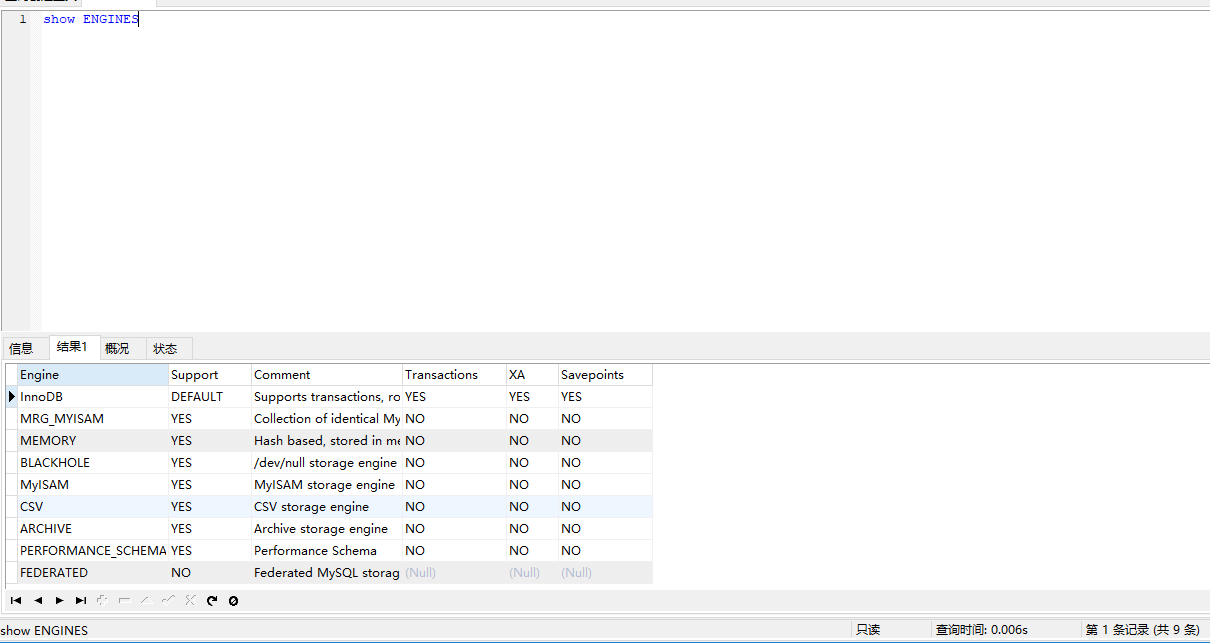
12 查询 有哪些引擎 show engines; mysql 一共有9 种 存储引擎 ,只有innodb 支持事务,默认的引擎也是 innodb;
或者 show VARIABLES LIKE '%engine%' (只能查询默认用的那个, )
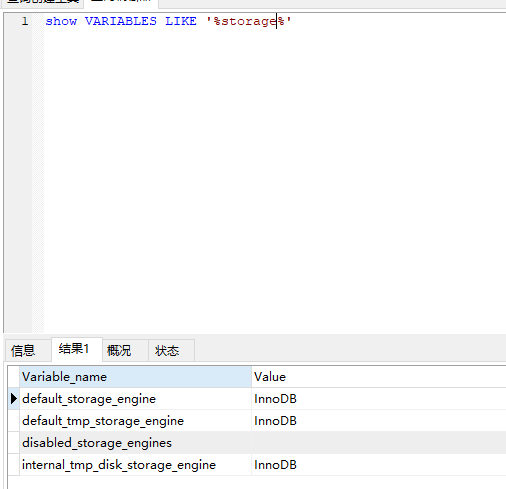
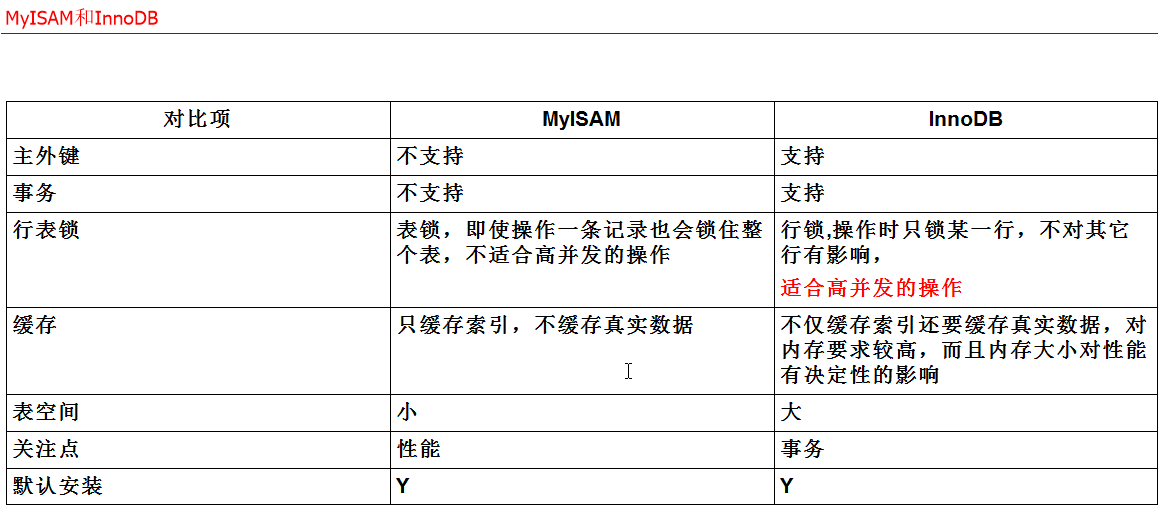
13 myisam 和 innodb 对比 图
14 percona 对mysql 数据库做了改进,新能和功能都有显著 的提高 , percona server 里面使用了 一种替代innodb 的 引擎 叫做 XtraDB 的引擎。中二哥引擎 提升了 innoDB 在高负债下的性能。
阿里使用mysql 是 使用 percona 原型 改造的。
15 查询慢, 执行时间长,等待时间长
没索性,索引失效 ,join 太多。连接数,mysql 最大线程数等,mysql 配置的一些参数等.....
16 创建 索引语句
单值索引:create index 索引名 on 表名(字段名);
复合索引:create index 索引ming on 表名( 字段1,字段2)
17 表关联的2种写法,一般建议用第二种
SELECT * from orders,pay_notification where orders.id = pay_notification.source_id 相当于内连接
SELECT * from orders INNER JOIN pay_notification on orders.id = pay_notification.source_id
18 4 种 join, 除了了inner join都叫做外连接。
left join:最连接 相当于 left outer join
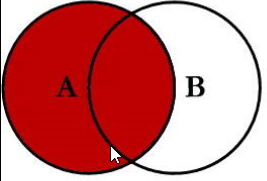
right join:right outer join 右连接
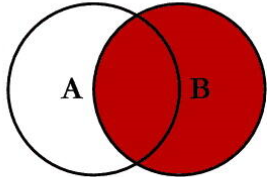
inner join: 只写 join 相当于
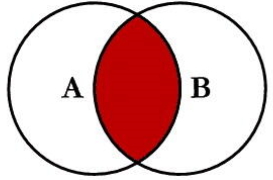
full join :或者写作 full outer join, mysql 不支持 全连接 可以用查询结果 的UNINE 代替。
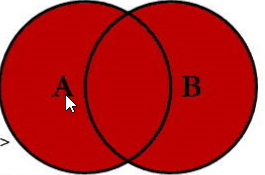
备注:如果要求取 不要共有部分,的一边 可以让 where 里面 on 的 关键字 is null;
19 机器解析 sql 最先看的是 from 的表,然后看on 连条件,然后才是 join ,后面才是 where 后面,最后 才是select 前面
20 union 合并连个结果 union 和 union all 的却别, union 去重并且按照默认规则排序,union all 不去重,并且不排序。
21 索引是一种数据结构。一种能便于提高查询速度的数据结构。索引是有序的。
22 mysql 索引的数据结构的2 种类型,btree 和 hash。
btree:多路搜索树,不一定是 二叉树
hash:顾名思义 用户 hash 算法
23 一般建议 使用符合索引,因为 一般的查询都只是查询一个字段,一张表的索引数量建议在5 个以内。
复合索引 只有第一个字段是可以 被单独索引的,
24 建立索引的2 种方式
create [unique] index 索引名 on 表名(列名);
alter 表名 add [unique] index 索引名 on (列名);
备注 主键是一种唯一并且非空的索引,
alter 表名 add primary key 索引名 on (列名);
25 查看 索引
show index from 表名;
26 删除索引
drop index 索引名 on 表名;
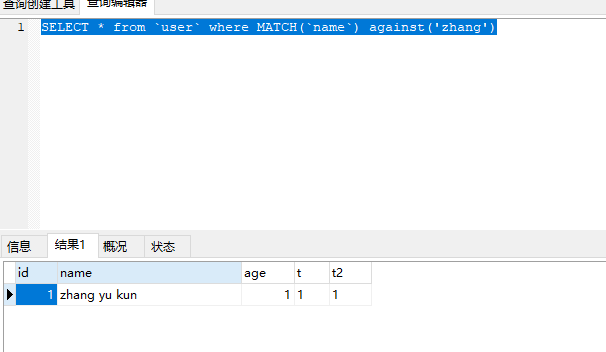
27 mysql 支持 full text 类型的 索引。 以前只能在myisam 上用,现在innnodb 也可以。
语法:SELECT * from `user` where MATCH(`name`) against('zhang') 貌似中文支持不好,我试了下中文不行
28 mysql 的 索引类型有三种 normal ,unique,full text
29 mysql 的 索引方式有2 种 btree 和 hash,但是 full text 好像不能指定索引方式。
30 那些地方应该用索引
1主键
2频繁查询的字段
3 表连接用的外键关联字段
4 排序字段
5 分组字段
31 不应该用索引的地方
1修改频繁的字段
2 where 条件不出现的字段
3 大量null 或者重复的字段。
4 表数据量少,几百条的数据没必要建立索引。
32 mysql 的 数据量瓶颈在哪里,有的 所 300W 有的 说500W 有的 说2000W。这些都和硬件配置有关。
一句话。当维护一个修改索引维护时间过长的时候,当mysql 机子的内存不能够完全承载 整个 索引的时候。就是mysql 的瓶颈。一般来说在千万级别。
33 排序字段如果通过索引去访问可以大大提高排序速度。 因为索引就是有序的。
34 EXPLAIN 加载 查询sql前面 可以查询 查询的 执行过程
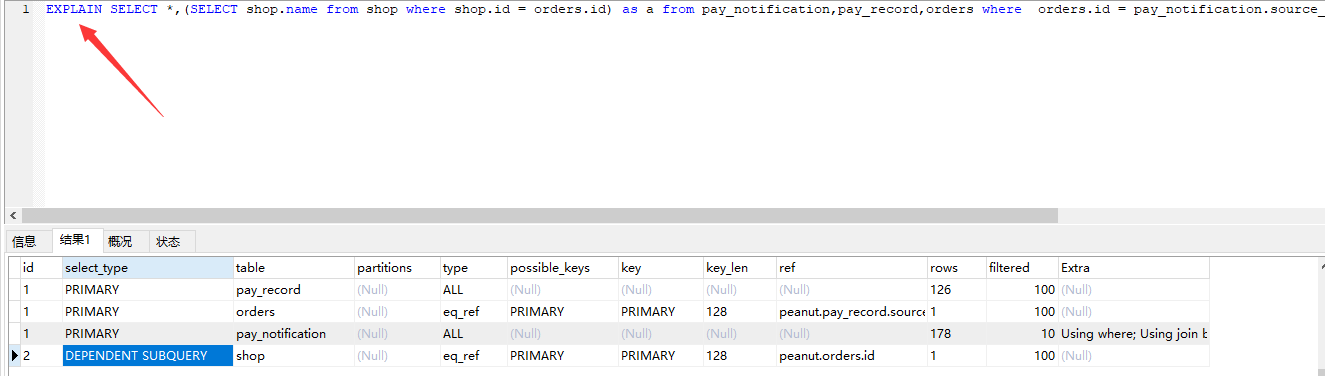
备注:
id 越大的 越先执行,id 相同的 按前到后的顺序执行。 union 操作 没有id,最后执行。
35 explain select_type: 查询类型
simple:不包含子查询,挥着union 的简单查询。
primary:包含子查询 或者 union 的查询的 主语句,也就是这时候最后加载的
sunquery:子查询
derived:派生表查询 ,在from 后面通过子查询结果产生的派生表的查询,分页插件查询总条数的时候必然会用到衍生变查询,吧原来的查询包裹了一层,5.7 以后好像取消了,直接叫做简单查询了。
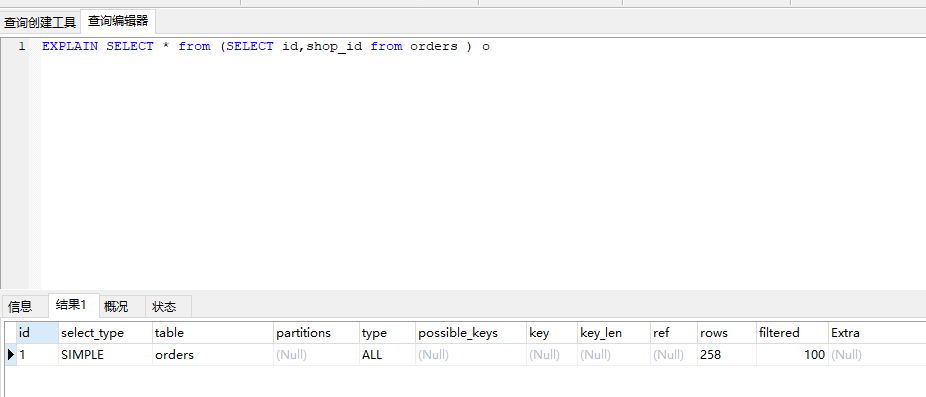
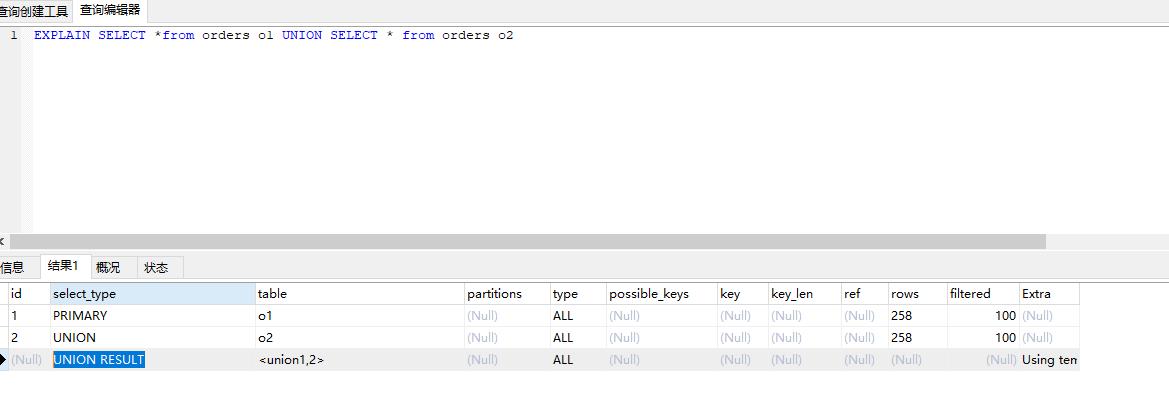
union: 如果 select 出现在 union 后面 就标记为 union
例子:EXPLAIN SELECT *from orders o1 UNION SELECT * from orders o2
UNION RESULT: union 的 合并结果 ,没有Id
36 explain type 解释: 描述检索范围
最好到最次一次是:system>const>eq_ref>ref>range>index>all

system:当表里面只有一条数据,并且是const 的条件下(一般只有系统表拆可能),实测,依旧是 all
const:主键索引 或者唯一查询
eq_ref:唯一性索引扫描。对于每一个索引键只有一条记录预支对应。(用到了索引,并且只有一条记录 )
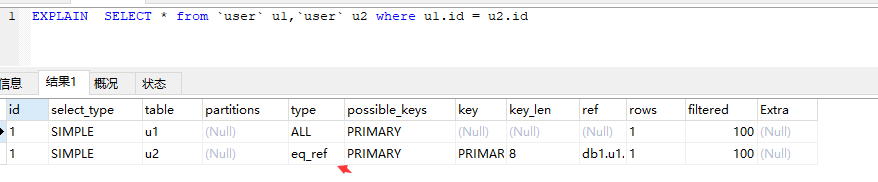
ref:非唯一索引扫描,返回匹配摸个单独值得所有行。

range:使用了索引,并且是范围查询。一般是between ,< ,> ,in,


index:全索引扫描,selelct 里面出现的字段 都在index 里面

all:全表扫描。如果数据量大的查询必须优化。
37 in 挂不上索引,是错误的 , 复合索引使 in会让索引失效。但是 单只索引不会。复合索引只有第一个字段可以单独索引是对的(或者说 只要用上第一个字段就可以用上索引,前提是别用范围查询)。


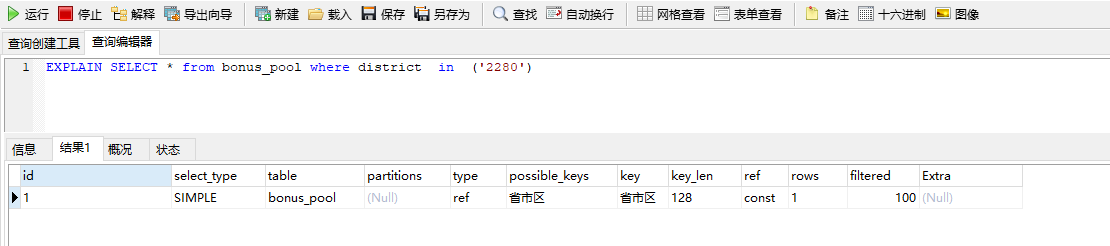

38 数据类型不一样 不能使用索引,比如 数字和 字符类型 混用

39 explain possible_key 查询的字段上如果涉及到多个索引,那么这里就是多个索引,这些索引可能有些没被使用。
40 explain key 查询最终使用到的索引。possible_key 没有值 ,key 可能也有值。possible_key 是通过 where推测的。
比如 where 里面 没有查询条件,但是 select 查询的都是 索引字段( 上面 type = index 的 情况 )。
41 explain key_len:本次查询使用到的 索引长度( 在一定范围内的索引内去查询),在不损失精度的情况下 越短越好。一般来说条件越多,len 越长 。
42 覆盖索引查询的 解释:
如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
41 explain ref: 用到了索引的那一列。
42 explain rows: 大概的估算出查询到结果 可能 需要读取的行数,越小越好。
43 explain Extra: 一些比较重要,但是有不适合在单独的列显示的额外信息。
using filesort :除了 默认主键索引排序以外的文件排序。 mysql 种无法使用 索引排序的 排序操作 叫做 文件排序,数据量大了,效率极低。 一般是因为排序 或者 分组 的时候没用上索引。 危险
如果 是复合索引.where 里面用了第一个字段 后面排序 截止用 第二个 ,是可以使用排序的,如果直接第三个就不可以。
using temporary:使用了临时表,比 文件排序效率更低。 一般是因为 分组没用上索引。 危险
using index: 覆盖索引查询 就会有这个。表示性能良好纯 索引查询。不需要 读取硬盘 的查找操作。 好事
using where: 用了 where 无所谓,正常
using join buffer: join 的时候用了 缓存区。正常
select tanles optimized away: 在统计最大最下数量的时候,智能的在查询阶段就完成了,而不用等到 查询结束再来统计。 好事
distinct:使用了去重复 无所谓
impossible where: 无效的where 比如 a = 1 and a = 2. 一般是where条件 有问题。
44 \G 竖着排 ,但是不能加 ; 号 。
--------------------------------------索引优化部分------------------------------------
45 范围 条件会让后面的索引失效,这时候可以考虑建立缩印的时候不带上 这种范围查询字段,在索引查询的基础上范围查询也不慢。
46 2表 join 的时候 左连接 在 右 变建索引,右连接在左表建立索引。这样效率比价高 ,虽然都生效。
47 3 表的 join 和上面一样,但是要在后面2 个表 连接字段加 索引。

48 like 查询 只有 只有后面加 通配符可以使用索引,前面加通配符不可以。
49 索引 使用 规律 终结:
复合索引的情况下:
1 第一个索引字段必须有
2 后面的 字段最好不要中断,如果中断了,只有中断之前的可以使用索引。但是有些时候中断了问题也不大,毕竟第一个字段 索引筛选后的结果 可能已经很少了。( 可以 索引字段不用完,但是最好连续)
3 不要在索引列做任何的 计算 函数 类型类型转换( 比如数字 和 字符型),这样会导致全表扫描。 一句话 索引字段别计算,类型装换也不行。
4 范围查询后面的查询 全失效 ( 范围查询以后 ,这个范围查询字段已经不用于检索了,而是用于结果的排序了, 使用索引类型变成 range 了)
比如:abc 三字段复合索引 : a=1 and b >1 and c =2 。这个查询 只有a 是索引检索,b是索引排序,c 没用上。 查询类型是 range 。
5 select 后面的查询的字段 用多少写多少,最好全部命中索引(只要查询的字段全在索引,但是不需要索引的字段全部出现),这样索引就直接返回,不需要 io 操作去读硬盘。
索引覆盖的情况下 explain 后面的 extra 里面会有 using index;这样效率极高。值得一提的是,如果索引覆盖查询,即便 where 后面的条件是范围查询, 索引使用等级 也会是 ref 而不会是range;
6 mysql 在使 不等于 ( != 或者 <> ) 的时候无法使用 索引,会导致全表扫描。 (单值和复合都一样)
7 is null, is not null 也不能使用索引(我们应该考虑一下 合不合适 填个默认值,如果合适就用默认值效率高很多) (单值和复合都一样)
8 like 通配符不能出现在 开头,只能出现在关键字后面,也就是必须用确定的关键字开头。(单值和复合都一样)
例子: a 'a%' 会用索引 , a '%a' 不会用索引,a '_a' 不会用索引
备注:如果非要用 通配符 开头,那么可以考虑 覆盖索引。这样查了索引就完事了,不会去 硬盘中查询。
9 不能类型转换,字符类型绝对不能失去 单引号。但是 数字类型可以 单引号( 就是这么奇怪),(单值和复合都一样)
10 复合索引中,or 会导致 索引失效。所以要少用。单值索引中不会。
11 in在 复合索引中会索引会失效,单值索引中不会。
50 索引放在那里的? ,一般来说 内存足够的情况下 索引在内存有完整的一份,硬盘也有。内存不够的时候,内存中有部分索引。这就是mysql 的瓶颈之一。这时候性能会急速下降。
51 char 比 varchar 查询快,因为它是全值匹配。但是比较占空间,但是 网上 说在没使用索引的情况下 varchar 比插入更加快。有空试试。数据量小看不出来。
52 where 1=1 会强制全表扫描,让索引失效,谣言。 以前版本不知道 ,现在的mysql 不会。没那么傻。亲测。
53 索引列的检索和 顺序无关, 比如 索引 index(a,b) 写成 where a=1 and b =2 和 where b=2 and a=1 一样,但是 最好按顺序写,避免 mysql 优化器给我们再次优化。
54 复合索引范围查询 后面的 索引失效,值的不是我们写的顺序,而是索引定义列的顺序, 比如下面 前三列都是索引检索,最后一个c4范围查找。

55 order by 后面的 字段 可以 和 前面where 的条件 共用索引,但是, 必须是连续的 ,并且 order by 的 后面的 字段 必须和索引字段 顺序一样,如下 ,排序 没有用上索引, 使用了字段排序。

56 上面的 特殊案例 如果 where 前面出现了一个确定值 ,那么 order by 字段会被忽略。 下面的 c2 被忽略了。

57 order by 和 group by 都需要排序,也可以使用索引,并且也最好要用上 索引
order by 用不上索引会产生 字段排序
group by 用不上索引会产生 字段排序和 临时表
58 索引选择的建议
1 对于单值索引,尽量选择对当前query 过滤性更好的的字段建立索引
2 复合索引中 ,过滤性好的索引应该在前面(最左边),过滤性高的 能一次性过滤很多数据
3 建立索引的时候尽可能包含更多where 中的字段( 但是也不能太多),越多速度越快,
59 like 通配符在后面的 这种范围查询,后面的索引查询不会失效。 因为使用因为 能确定前缀,范围明确。 但是依旧会是 range 的 索引使用等级。 下面的 like 后面 的 c3 也生效了。

60 sql 调优 的过程
1 先让程序跑着看看效果
2 如果 跑着效果不好,开启慢查询日志看看那些sql 慢。
3 使用 explain 分析 慢查询的 sql 的原因
4 使用 show profile 分析
5 考虑 数据库 参数调优 和 物理机的问题。
61 小表驱动大表 效率比较高。
62 in 和 exists 效率 在 主查询 数量量大于子查询( in 和 exists 部分)数据量的时候 in 效率高 ,否者 exists 效率高
简单的理解: in 里面不能有太多东西, exists 是 用主查询的结果去 找 exists 部分的主查询 验证。
exists:可以看到 id 相同 先执行的 item 的查询 ,然后去 exists 里面验证

in:先查询的 in 里面 ,然后在执行的 外面。

63 exists 里面的 子查询 select * 和 select 1 没有却别,mysql 活忽略这时候 select 字段清单。之关系 有 有和没有。值返回true和false;
64 如果有些时候不能避免 fieldsort , 那么 可能需要设置 把排序的缓冲区 设置大一些。
sort_buffer_size: 排序 缓冲区大写哦设置 在mysql.ini 里面,5.7 默认256K ,一般情况下 调大没有明显的作用。除非你确定需要。

max_length_for_sort_data: 排序字段允许最大数据条数(指的是 超过这个数量就不会使用单路排序算法) 默认1024
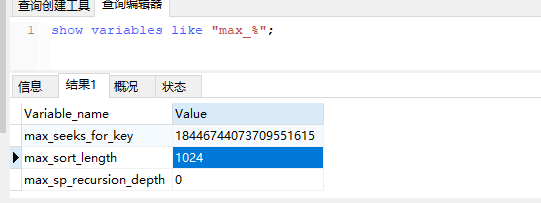
65 mysql 的 字段排序 算法( fieldsort )
双路排序算法:mysql 4.1 以前 只使用这种算法。
排序的时候,首先io一次读取值读取排序字段,在内存中排序完成以后,在io一次加载剩下的 字段。
缺点 : io操作 2 次,
优点:sort buffer 缓冲区 内存占用少。
单路排序算法:mysql 4.1 以后 有的这种排序,默认使用,当 数据条数大于 max_length_for_sort_data 的时候使用 双路 排序。
排序的时候,一次io 加载全部select 后面的字段,然后直接排序完成。
优点:只有一次IO 操作
缺点:使用 sort buffer 内存比较多,如果 sort_buffer_size 不够了,效率 比 双路排序更加低,因为这时候 ,一次加载 一部分记录,排序完成以后再加载一部分,知道 所有记录都排序了
,然后还要把多次排序 结果 合并起来,也就是多路合并。这个过程可能还会产生临时表,用于存放 局部排序的数据片段。而且也是多io 操作。双路排序 sort buffer 不够也会做类似的操作,
但是,明显 双路排序 sort buffer 超出的的可能信 会小很多。
66 mysql 慢查询 日志 ,默认是关闭的 ,开启以后。 超过 long_query_time的sql 会被 记录下来。 是否开启的 由 slow_query_log指定的。
long_query_time: 慢查询时间阙值参数 备注:修改这个值当前 回话不会生效。所以必须使用global 修改。
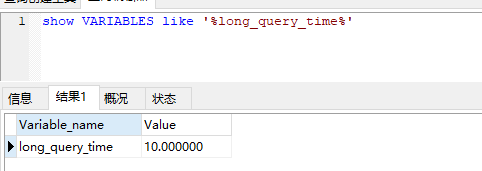
slow_query_log:慢查询 日志的 开关 。 建议不要长时间开启,只在零时开启。
slow_query_log_file: 慢查询日志记录文件

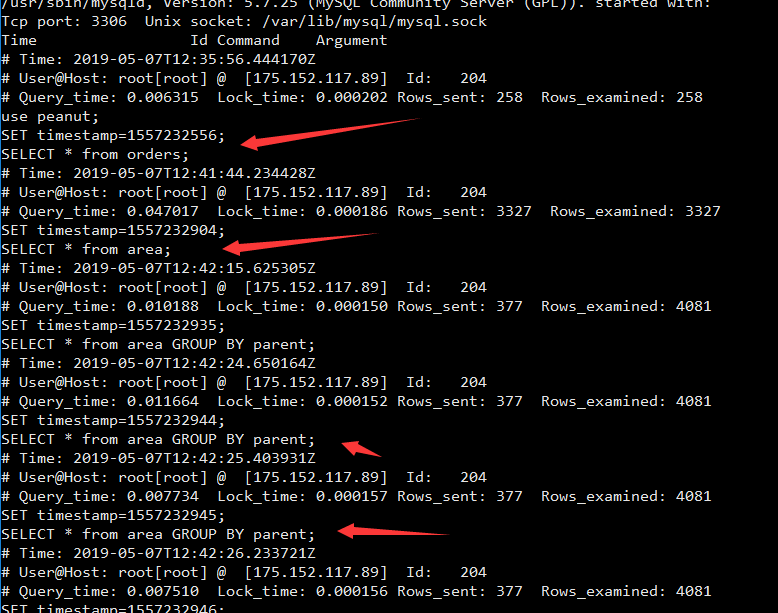
备注慢查询日志截图:
67 修改 mysql 配置参数
全局修改:去改 my.ini 文件
暂时生效: set global 参数ming=参数值;( 只对当前库有效,重启mysql 服务以后无效)
暂时回话: set 参数=参数值;
68 SELECT SLEEP(5) 可以让 sql 睡 5 秒中 。
69 SELECT 1,2 from dual; mysql 有个 虚拟表 叫做 dual ;
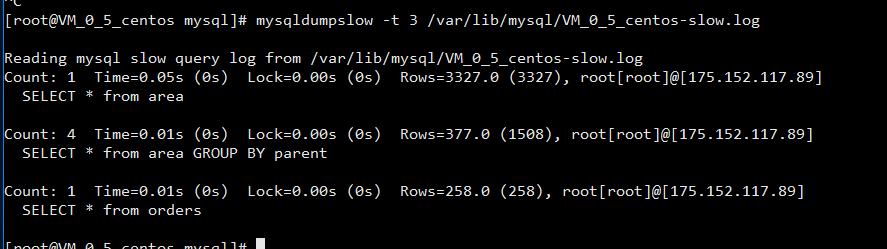
70 mysqldumpslow 可以分析 慢查询日志; 和用法
查询平均时间 最前面的三个:
71 修改 mysql的定界符
delimiter $$ ,修改 mysql的 定界符 为 $$ ,mysql 默认定界符 " ; " 就失效了 ;
72 调用存储过程
call 过程名字;
73 查看 profiling 是否开启
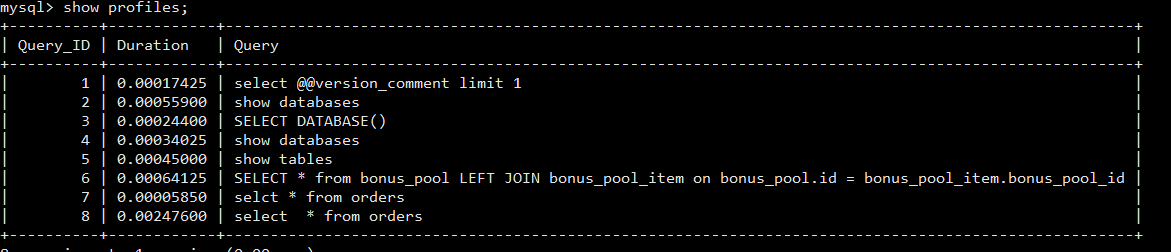
74 show profiles; 查询最近几条sql 的 执行时间 。 备注:不要用 三方工具连接数据库 ,比如 navicat ,三方工具 会额外的发送一些 状态 sql;
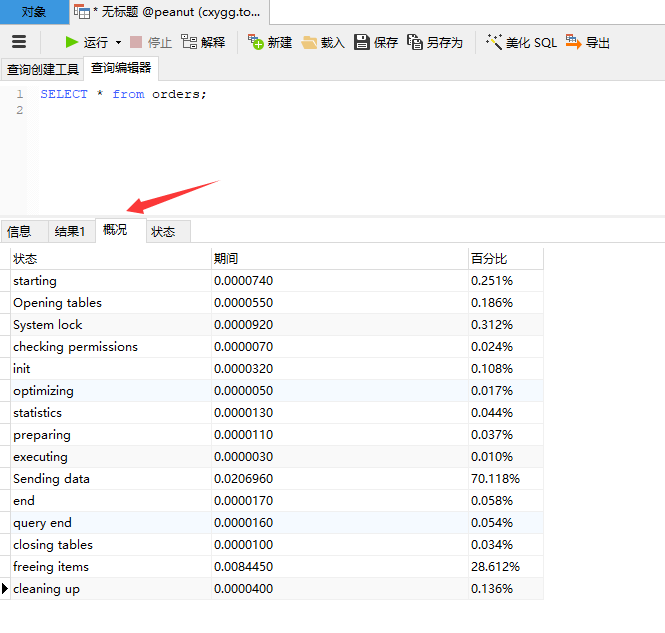
75 show profile cpu,block io for QUERY 70 查询 sql 执行 过程资源损耗
show profile :能显示的参数。
all:显示全部
block io: 显示 io 开销
CPU:cpu 使用时间
IPC:发送和接受相关的开销
memory: 内存相关开销
page faults: 显示错误日志相关的开销
source: 显示 source 相关的开销
swaps:显示交换次数相关的开销
show profile显示的正常过程:

值得一提的是:navicat 的 概述 里面显示了 查询的 过程的 profile 关于 耗时的部分。
76 show profile 一些比较危险特殊的过程:
converting heap to MYISAM:查询结果太大,内存不够用了,查询结果零时放在硬盘上了
createrting tmp table 创建零时表
coping to temp table on disk:把内存中的数据复制到硬盘上的零时表。 危险
locked: 锁了。
77 全局查询日志: 建议生产 永远不要开启。
set global general_log =1; 否生成sql日志
set global log_output='TABLE'; 吧日志输出到 mysql 数据库的 general_log 表里面。 默认是 FILE
备注:三方工具会产大量的 状态 查询 sql 的 日志。想看到 不看这些东西 ,或者说不产生这些东西,应该直接连接 命令行 连接 mysql。
78 show OPEN tables; 查询 表使用状态。
79 lock table 表名 read/write;表名 read/write 给表加一个读锁或者写锁。
备注:可以同时加多个 lock table 表名 read/write;表名 read/write
80 unlock tables; 解锁。
备注:unlock table 也可以解锁;
81 查看mysql 是否有争锁问题。
表锁:
Table_locks_immediate: 表立即响应的次数;
Table_locks_waited: 表锁的次数。
行锁:
Innodb_row_lock_waits:行锁的次数

82 MyISAM 不适合做写库的原因
MyISAM 的 读的 锁 阻塞所有读写请求。而且锁都是表锁,所以 所以不适合写。
83 innodb 支持行锁,前提 where 的 查询条件使用索引的时候使用的行锁,没有索引,或者索引因为 某些原因失效了,那么久变成表锁了)
备注:一般的 a=1 for update 即便 a 有索引,也不是只锁定了一行,这用的锁方式 是 行锁+间隙锁( next_key lock) 1 这行锁定 加入 1 前面是0 ,1 后面是 2, 那么锁定的 是 (0,2) 这样一个开区间 如果 查询一个 a = 1 的记录是不行的。吧别的记录 改成 a=1 也是不行的。
如果 1 前面 是0 ,后面 是 3 ,那么锁定的就是 (0,3) 1,2 都被锁定了区间(不完全是 ,还要看其他字段的顺序,如果 1,2 因为别的字段 排在区间外面去了就可以)。
84 事务的隔离型,很多人只认为是不能读到别的事务为提交的数据(脏读),其实还有一点 是个事务启动以后读到的数据就数据就恒定了(除了幻读的插入),别的事务在这个这个事务提交以前,对数据做任何提交了的修改,当前事务都看不到(需要RR的事务隔离级别)。最狠的是幻读,需要 插入也不能 读到,这个以前需要 序列化级别的 隔离,目前 mysql 的 RR 也可以做到。
85 间隙锁(需要 可重复地 隔离级别 )
update tab set a = 1 where id >10 and id < 20 。 执行治具话以后会会个 10 到20 的 id索引 都加上锁,即便这个 索引ID 不存在。
同理: select * from tab where id >10 and id < 20 for update 也会给 这些记录加上间隙锁。
86 for update 是行数还是表锁? for 是个指定记录加上写锁。防止修改,等待自己独占写的权限。 如果 查询是 常量 索引 查询,那么是函索,如果 索引失效,或者没有索引那么是表锁,或者是 ,如果是 索引生效,并且结果是范围,那么是 间隙锁,锁一个区间。
87 lock in share mode 和 for update
SELECT ... LOCK IN SHARE MODE走的是IS锁(意向共享锁),即在符合条件的rows上都加了共享锁,这样的话,其他session可以读取这些记录,也可以继续添加IS锁,但是无法修改这些记录直到你这个加锁的session执行完成(否则直接锁等待超时)。
SELECT ... FOR UPDATE 走的是IX锁(意向排它锁),即在符合条件的rows上都加了排它锁,其他session也就无法在这些记录上添加任何的S锁或X锁。如果不存在一致性非锁定读的话,那么其他session是无法读取和修改这些记录的,
但是innodb有非锁定读(快照读并不需要加锁),for update之后并不会阻塞其他session的快照读取操作,除了select ...lock in share mode和select ... for update这种显示加锁的查询操作。
所以:for update的加锁方式无非是比lock in share mode的方式多阻塞了select...lock in share mode的查询方式,并不会阻塞快照读。
88 意向锁, 查询后面加的锁就是意向锁。
89 页 锁 在 bdb 引擎中才有。
90 innodb 支持高并发的原因。因为 innodb支持分锁定读。 也就是 读取数据不需要加锁。因此,写不会阻塞读。适合做写数据库。
91 关于间隙锁
在唯一索引上更新和for update,使用间隙锁的时候,是一个共享锁,阻止写事务,但是不阻止读事务。如果这时候另一个事务也获取了这个共享锁,然后 两边都执行插入操作(修改操作不会),共享锁都想升级成独占锁,但是因为相互都在抱着共享锁等独占锁。所以会死锁。mysql 这时候会吧第二个执行的事务撤销。
在唯一索引上更新和for update,使用行锁的时候,是一个独占锁。
在普通索引上是独占锁。
普通索引锁住的是前开后闭区间,唯一索引锁住的是前后闭区间。
唯一索引等值查询(并且数据存在),不会使用间隙锁,而是使用行锁。
没有用上索引或者索引失效的更新或者 for update 都是锁表。
普通索引如果是等值查询(并且找到记录),修改只锁当前行,插入锁定当前行前面两个区间( 所以 行锁 和 间隙锁 只能在 使用唯一索引的时候才能 生效),如果查询是 索引覆盖,那么 锁的只在当前索引列,id 索引列依旧可以更新。
数据库的等锁超时是50秒,但是事务是没有超时的?
如果update更新的是0条数据,那么不会升级间隙锁为写锁。
获取间隙S锁,任何时候都可以,即便是已经事务获取到了X锁,获取X一定要求没有别的事务获取到X或者S锁。
补充一份最近的到的mysql高级课件:
链接:https://pan.baidu.com/s/1V--FX1vRhj--ndDdtqacIg
提取码:xc16
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2019-05-03 21:43 zhangyukun 阅读(270) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号