mycat 安装 分表 分库 读写分离
简单的 理解 一下 mycat :如图 mycat 是一个 连接数据库的中介。一个独立安装的 工具,他连接着真实的数据库,并且 把自己伪装成一个数据库。
程序连接 mycat ,mycat 连接 到真实 数据库。 mycat 这个中介 帮我们管理者分布式事务,数据切片,主从数据库。 在我们程序 看到的只是 逻辑数据库里面的 逻辑表。我们可以直接使用 jdbc 对他进行操作。就像正常的单表一样。 mycat 来管理 数据切片,主从,分布式事务问题。
实测 navicat formysql 11.0.9 可以连接mysql。
或者 命令行连接: mysql -uroot -P8066 -h127.0.0.1

centos mycat 安装:
1 下载: whet http://dl.mycat.io/1.6.6.1/Mycat-server-1.6.6.1-release-20181031195535-linux.tar.gz
2 解压: tar -zxvf Mycat-server-1.6-RELEASE-20161028204710-linux.tar.gz
3 启动: cd mycat/bin
./mycat start
备注: mycat 是 Java写的
查看 mycal 进程是否 正常启动 :ps -ef|grep mycat
备注2: mycat 是Java写的 ,需要安装jdk 安装方法: https://www.cnblogs.com/cxygg/p/9374475.html
4 停止 mycat : ./mycat stop
mycat 配置文件位于congif 下面:
最重要的三个文件:server.xml , schema.xml ,rule.xml
server.xml 配置 这 mycat 的 端口,用户名 密码。 和 用户名 下面有哪些逻辑数据库等全局的 配置。
schema.xml 里面配置着 逻辑数据库 下面有哪些逻辑表,逻辑表 存放数据的数据节点 在哪里。逻辑表是用干什么规则 来给数据分片的。
rule.xml 定义了一下 数据库分切片 规则,这些规则被 schema.xml 引用。
要让 mysql 跑起来 ,需要两个东西 第一 Java, 第二 需要真实的数据库。 比如一个mysql 。
mycat 的默认端口是 8066
下面 我们简单的见一下mycat 的 默认配置:
下面的配置位于:server.xml 里面
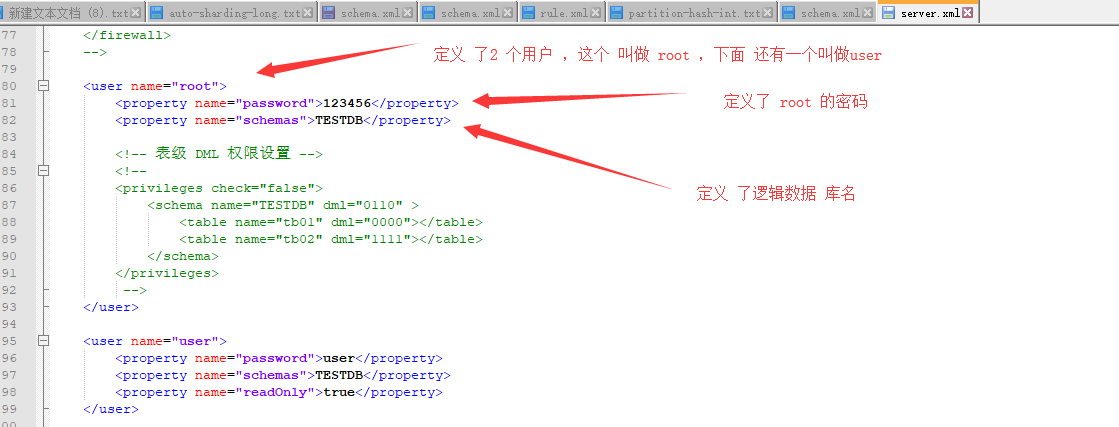
入上图:我们可以直接在 工具中连接它。( 这时候 mycat 还么有真实的 连接到 mysql )
下面 看一下 schema.xml 表:

备注: 可以直接给 逻辑数据库指定 一个数据节点,相当于给每个表都使用同样 的 数据节点。这种方式不支持数据切片,也就是说分库没法用了。只能 在 host上面做
rule.xml 里面配置 的 规则:
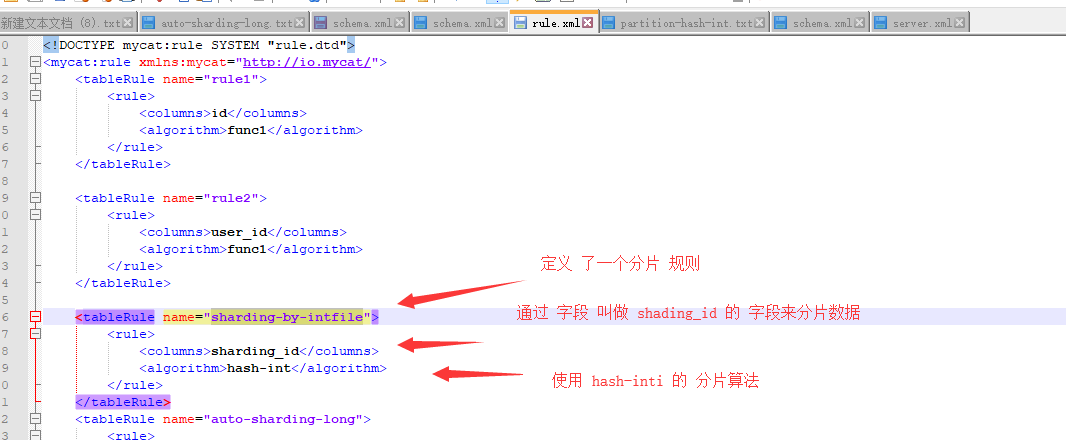


上面的这种 相当于 根据枚举值决定分到哪个分区, 10000 这个枚举值去 0 的 数据节点,10010这个 枚举 去1 的 数据节点。
配置把数据节点指向到mysql以后,启动 mycat ,就能看到这些 逻辑表了。
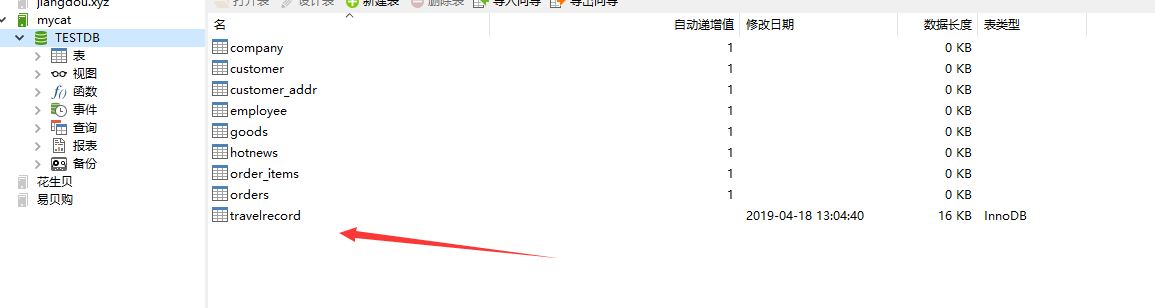
这些都是逻辑表:不是真实存在的。 建表语句创建表
执行:create table travelrecord (id bigint not null primary key,user_id varchar(100),traveldate DATE, fee decimal,days int);
然后 三个数据 节点都存在了这张表。( 数据节点的 数据库 需要提前创建 )
后面就可以正常 查询,插入修改了。 和 直接使用mysql 一样。
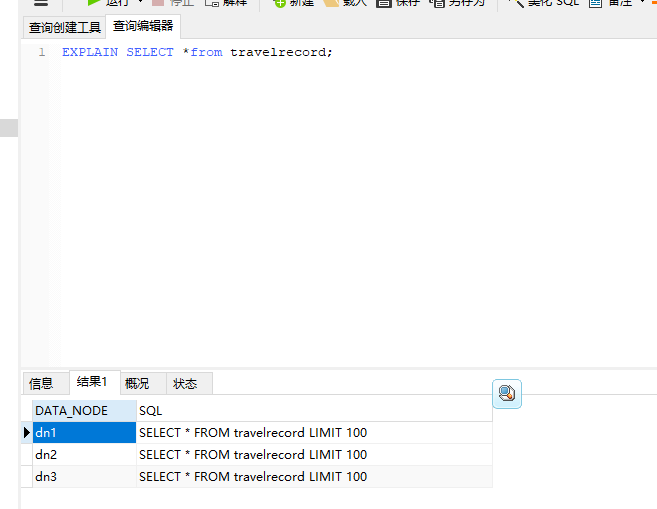
在 sql 前面 加 EXPLAIN 可以看 sql 被 是在哪个数据节点执行的:
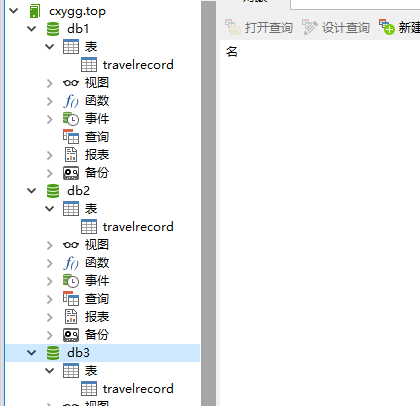
分库: mycat 的 分库是利用 一个逻辑数据库 指定 多个数据节点, 然后不同数据节点对应不同的 数据库。 并且 这些数据库中的 表不一样。

逻辑数据库db 分成 db1 和 db2 两个真实数据库
主从读写分离:mycat 主从是在 数据节点那一层来实现的。 一个数据节点,对外开 配置 读主机,和写主机。 mycat 支持 多主多从,但是 mycat 的 多主是以 个主写,其他的主在主节点挂了才提供些的功能,正常情况下这些主 ,可以用于 读节点 存在。( 需要设置 balance )
主1 从1 从2
主备1 主备从1 主备从2 主备1 和 主 不会 同事提供写功能
备注: 我说的 主备是指的 可写节点 的备用写节点,而不是 主从关系。
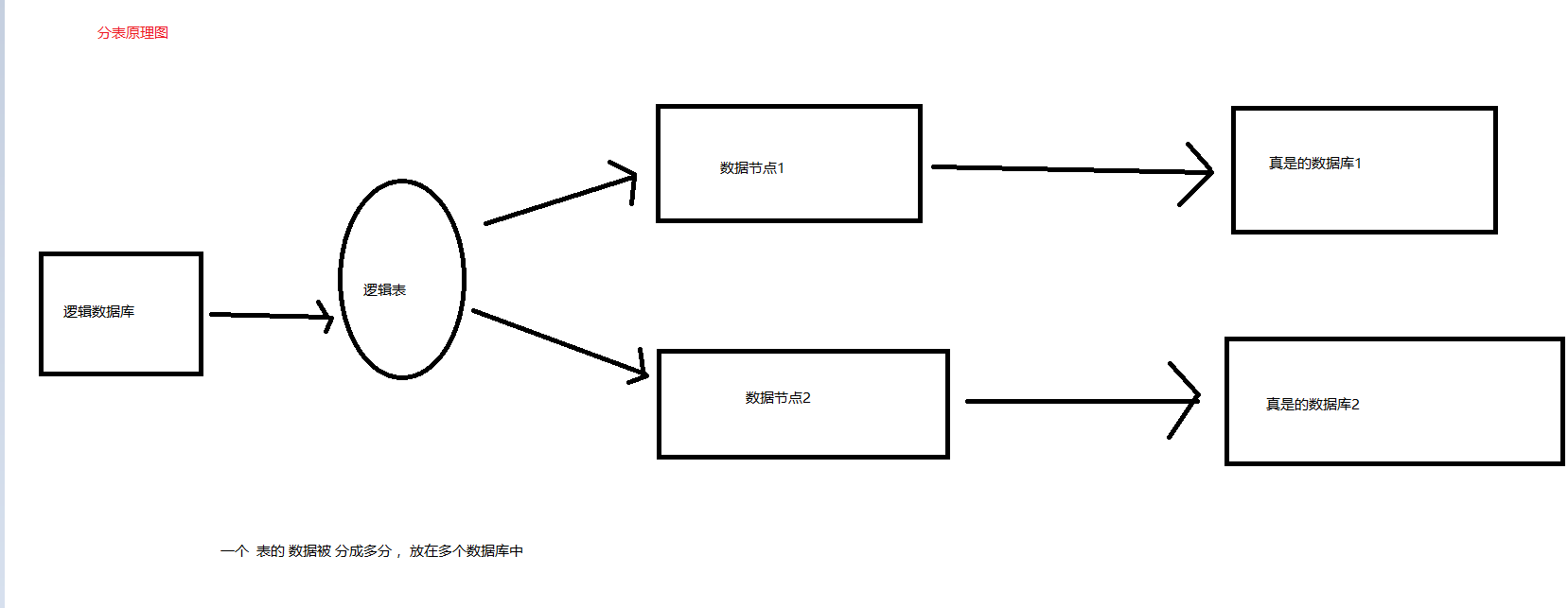
分表:mycat 的 分表,事垮库的分表。 不支持在同一个数据库 分表( 至少目前 我没有发现),mycat 的 分表 是吧一张表 分到 多个数据库中,(这个功能貌似 1.6 提供的 )
比如 逻辑表user ,分到 db1.user 和 db2.user 支持
比如 逻辑表user ,分到 db1.user1 和 db1.user2 不支持 (sharding sphere 有这个功能)
mycat 的 逻辑表的类型 有两种 在table 标签中用 type=global 指定为全局表,不写,普通表。
普通表: 正常的需要分库的表
全局表:每个库里面都有,而且是每个库都有完整的一样的这张表,任何修改操作都是 所有库都修改,查询 去其中一个查询。 全局表 可以和任意一个库的任意表join。 全局表一般用于,修改不频繁 ,数据量小的 表。
最后说一句。mycat 2016 年以后 基本就没什么 更新,慎用。 1.6.0 版本 是 2016 年发布的, 2018 年 发布了 1.6.6 版本。 和当年的 dubbo 一样 ,几年没更新,然后 spring cloud 占领了市场,虽然 dubbo 目前 捐给 Apache 了,有人更新和维护,但是 感觉已经 干不过 cloud 了。 mycat 可能 会被 sharding sphere 之类的东西 干死。 个人观点 mycat 设计理念 比 sharding sphere 好, mycat 作为 一个 数据库中间件,或者说 就是一个数据库中介。开发者完全不用关心主从 同步的问题,但是 sharding sphere 主从不同步的 处理的 需要程序员 自己考虑,有些时候 为了避免 主从同步 读到 从库,需要强制使用主库。 sharding sphere 说的在一个线程中 写入了数据,后面都会自动使用主库,但是实际体验在 spring 事物嵌套 ,有复制 事物传播机制的 时候,这个经常还是读的从库。
mycat的 配置的一些说明: 下面的内容摘自:https://www.cnblogs.com/li3807/p/8461811.html
mycat 不能实现事物的强一致性: 也就是说,如果对 在 commit 阶段以后的异常 mycat 无法处理。

XA(eXtended Architecture)是指由X/Open 组织提出的分布式交易处理的规范。XA 是一个分布式事务协议,由Tuxedo 提出,所以分布式事务也称为XA 事务。XA 协议主要定义了事务管理器TM(Transaction Manager,协调者)和资源管理器RM(Resource Manager,参与者)之间的接口
一般如果我们要做分布式是否可以用 mq 作为 作为 rm 的 统筹角色。做到最终一致性。
Schema.xml 作为 MyCat中重要的配置文件之一,管理着 MyCat的逻辑库、表、分片规则、DataNode以
及DataSource。弄懂这些配置,是正确使用MyCat的前提。
schema 标签
该标签用于定义MyCat实例中的逻辑库,MyCat可以有多个逻辑库,每个逻辑库都有自己的相关配置。可以使用 schema 标签来划分这些不同的逻辑库。
<schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100">
<table name="tableName" primaryKey="id" dataNode="dn1,dn2" rule="rule1"/>
</schema>
-
相关属性
- dataNode :字符串,分片节点名称,多个以","号分隔
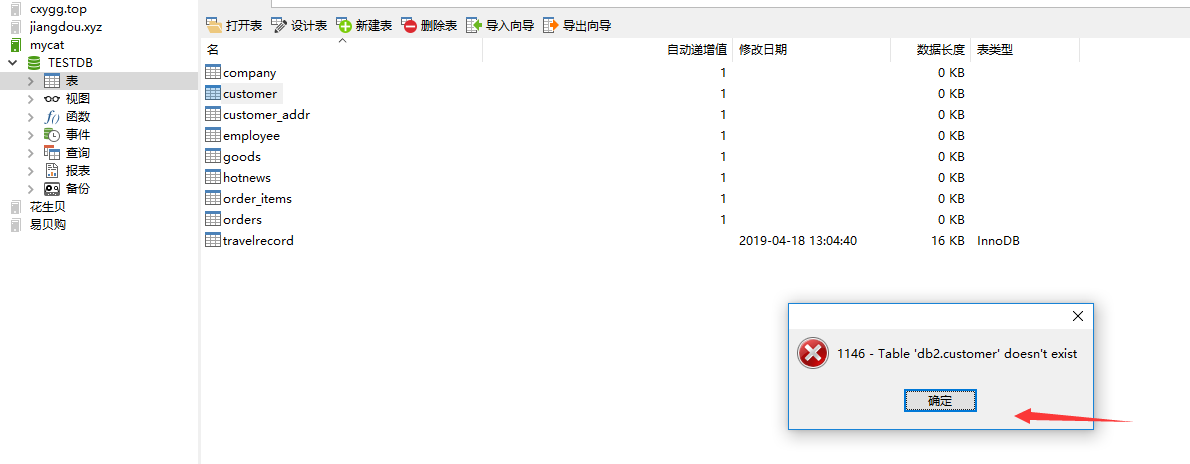
- checkSQLschema :布尔类型,当该值设置为 true 时,如果我们执行语句**select * from TESTDB.travelrecord;**则MyCat 会把语句修改为**select * from travelrecord;**。即把表示schema的字符去掉,避免发送到后端数据库执行时报**(ERROR 1146 (42S02): Table 'testdb.travelrecord' doesn't exist)。** 不过,即使设置该值为 true ,如果语句所带的是并非是schema指定的名字,例如:**select * from db1.travelrecord;** 那么MyCat并不会删除db1这个字段,如果没有定义该库的话则会报错,所以在提供SQL语句的最好是不带这个字段。
- sqlMaxLimit :int 类型,表示每条执行的SQL语句,如果没有加上limit语句,MyCat也会自动的加上所对应的值。例如设置值为100,执行**select * from TESTDB.travelrecord;**的效果为和执行**select * from TESTDB.travelrecord limit 100;**相同。 设置该值的话,MyCat默认会把查询到的信息全部都展示出来,造成过多的输出。所以,在正常使用中,还是建议加上一个值,用于减少过多的数据返回。 当然SQL语句中也显式的指定limit的大小,不受该属性的约束。 需要注意的是,如果运行的 schema为非拆分库的,那么该属性不会生效。需要手动添加limit语句。
table 标签
该标签属于 schema 的子标签,用于定义了MyCat中的逻辑表,所有需要拆分的表都需要在这个标签中定义。
-
相关属性
- name:定义逻辑表的表名,这个名字就如同我在数据库中执行create table命令指定的名字一样,同个schema标签中定义的名字必须唯一。
- dataNode:定义这个逻辑表所属的dataNode, 该属性的值需要和dataNode标签中name 属性的值相互对应。
- rule:该属性用于指定逻辑表要使用的规则名字,规则名字在rule.xml中定义,必须与tableRule标签中name属性属性值一一对应
- ruleRequired :该属性用于指定表是否绑定分片规则,如果配置为true,但没有配置具体rule的话 ,程序会报错
-
type:该属性定义了逻辑表的类型,目前逻辑表只有"全局表"和"普通表"两种类型。对应的配置:
- 全局表:global
- 普通表:不指定该值为globla的所有表
- needAddLimit :指定表是否需要自动的在每个语句后面加上limit限制,这个属性默认为 true
- primaryKey :该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的 DN上,如果使用该属性配置真实表的主键。难么MyCat会缓存主键与具体DN 的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的 DN,但是尽管配置该属性,如果缓存并没有命中的话,还是会发送语句给具体的 DN,来获得数据。
-
autoIncrement :mysql对非自增长主键,使用last_insert_id()是不会返回结果的,只会返回0。所以,只有定义了自增长主键的表才可以用last_insert_id()返回主键值。 mycat目前提供了自增长主键功能,但是如果对应的 mysql节点上数据表,没有定义auto_increment,那么在mycat层调用last_insert_id()也是不会返回结果的。 由于insert操作的时候没有带入分片键,mycat会先取下这个表对应的全局序列,然后赋值给分片键。这样才能正常的插入到数据库中,最后使用last_insert_id()才会返回插入的分片键值。 如果要使用这个功能最好配合使用数据库模式的全局序列。
- 使用autoIncrement="true" 指定这个表有使用自增长主键,这样mycat才会不抛出分片键找不到的异常。
- 使用 autoIncrement="false" 来禁用这个功能,当然你也可以直接删除掉这个属性。默认就是禁用的。
-
subTables :配置分表规则,并且在分表条件下,只能配置一个 dataNode,并且分表条件下不支持各种条件的 join 语句。配置实例如: subTables="t_order$1-2,t_order3" ,
分库模式下是:insert into table(xxx)values(1,name);
router:{
node1:insert into table(xxx)values(1,name) ,datanode1,
node2:insert into table(xxx)values(2,name) ,datanode2,
node3:insert into table(xxx)values(3,name) ,datanode3,
},
分表模式是: insert into table(xxx)values(1,name);
router:{
node1:insert into table1(xxx)values(1,name) ,datanode1,
node2:insert into table2(xxx)values(2,name) ,datanode1,
node3:insert into table3(xxx)values(3,name) ,datanode1,
},
childTable 标签
该标签属于 table 的子标签,该标签用于定义E-R分片的子表,通过标签上的属性与父表进行关联。
-
相关属性
- name :定义子表的表名
- joinKey :插入子表的时候会使用这个列的值查找父表存储的数据节点。
- parentKey :属性指定的值一般为与父表建立关联关系的列名。
- primaryKey :该逻辑表对应真实表的主键,例如:分片的规则是使用非主键进行分片的,那么在使用主键查询的时候,就会发送查询语句到所有配置的 DN上,如果使用该属性配置真实表的主键。难么MyCat会缓存主键与具体DN 的信息,那么再次使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的 DN,但是尽管配置该属性,如果缓存并没有命中的话,还是会发送语句给具体的 DN,来获得数据。
- needAddLimit :指定表是否需要自动的在每个语句后面加上limit限制,这个属性默认为 true
dataNode 标签
dataNode 标签定义了 MyCat中的数据节点,也就是我们通常说所的数据分片。一个dataNode 标签就是
一个独立的数据分片,比如我们要创建使用名字为lch3307数据库实例上的db1物理数据库,这就组成一个数据分片,最后,我们使用名字dn1标识这个分片,实例配置如下:
<dataNode name="dn1" dataHost="lch3307" database="db1"></dataNode>
-
相关属性
- name :定义数据节点的名字,这个名字需要是唯一的,我们需要在 table标签上应用这个名字,来建立表与分片对应的关系。
- dataHost :该属性用于定义该分片属于哪个数据库实例的,属性值是引用 dataHost标签上定义的name属性
- database:该属性用于定义该分片属性哪个具体数据库实例上的具体库,因为这里使用两个纬度来定义分片,就是:实例+具体的库。因为每个库上建立的表和表结构是一样的。所以这样做就可以轻松的对表进行水平拆分。
dataHost标签
该标签在mycat逻辑库中也是作为最底层的标签存在,直接定义了具体的数据库实例、读写分离配置和心跳语。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native">
<heartbeat>select user()</heartbeat>
<!-- 可以有多个写入主机 -->
<!-- 第一个主机 -->
<writeHost host="hostM1" url="localhost:3306" user="root" password="123456">
<!-- balance=3 所有读请求使用该服务器执行,可以有多个读主机 -->
<readHost host="hostS1" url="localhost:3306" user="root" password="123456" />
</writeHost>
<!-- 第二个主机 -->
<writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/>
</dataHost>
-
相关属性
- name :唯一标识dataHost 标签
- maxCon:指定每个读写实例连接池的最大连接。也就是说,标签内嵌套的 writeHost、readHost标签都会使用这个属性的值来实例化出连接池的最大连接数
- minCon :指定每个读写实例连接池的最小连接,初始化连接池的大小
-
balance:负载均衡类型,目前的取值有4 种:
- balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost上。
- balance="1",全部的readHost与 stand by writeHost 参与 select语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1与 M2互为主备),正常情况下,M2,S1,S2都参与 select语句的负载均衡。
- balance="2",所有读操作都随机的在writeHost、readhost上分发。
- balance="3",所有读请求随机的分发到wiriterHost对应的readhost执行,writerHost 不负担读压力
- dbType :指定后端连接的数据库类型,目前支持二进制的mysql协议,还有其他使用 JDBC连接的数据库。例如:mongodb、oracle、spark等。
- dbDriver:指定连接后端数据库使用的Driver,目前可选的值有native和 JDBC。使用native的话,因为这个值执行的是二进制的mysql协议,所以可以使用mysql、maridb 和 postgresql(1.6版本),其他类型的数据库则需要使用 JDBC驱动来支持,如果使用JDBC的话需要将符合 JDBC 4标准的驱动JAR包放到 MYCAT\lib目录下,并检查驱动JAR包中包括如下目录结构的文件:META-INF\services\java.sql.Driver,在这个文件内写上具体的Driver 类名,例如:com.mysql.jdbc.Driver
-
switchType:主从数据库切换类型,目前的取值有4种:
- -1 表示不自动切换
- 1 默认值,自动切换
- 2 基于MySQL主从同步的状态决定是否切换心跳语句为 show slave status
- 3 基于MySQL galary cluster的切换机制(适合集群)心跳语句为 show status like 'wsrep%'
- tempReadHostAvailable:如果配置了这个属性writeHost 下面的readHost仍旧可用,默认0 可配置(0、1)
heartbeat标签
这个标签属于dataHost的子标签内指明用于和后端数据库进行心跳检查的语句。例如,MYSQL可以使用select user(),Oracle可以
使用select 1 from dual等。
这个标签还有一个connectionInitSql 属性,主要是当使用Oracla数据库时,需要执行的初始化SQL语句就
这个放到这里面来。例如:alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss' ,示例代码:
<heartbeat>select user()</heartbeat>
writeHost 和 readHost 标签
这两个标签都属于dataHost的子标签,用于指定后端数据库的相关配置给 mycat,用于实例化后端连接池。唯一不同的是,writeHost指
定写实例、readHost指定读实例,组着这些读写实例来满足系统的要求。
在一个dataHost内可以定义多个writeHost和readHost。但是,如果writeHost指定的后端数据库宕机,那么这个writeHost绑定的所有readHost都将不可用。另一方面,由于这个writeHost宕机系统会自动的检测到,并切换到备用的writeHost上去。
-
相关属性
- host:用于标识不同实例,一般writeHost我们使用*M1,readHost我们用*S1
-
url:后端实例连接地址,如果是使用native 的dbDriver,则一般为address:port 这种形式。用 JDBC或其他的
dbDriver,则需要特殊指定。当使用JDBC 时则可以这么写:jdbc:mysql://localhost:3306/
- user:后端存储实例需要的用户名字
- password :后端存储实例需要的密码
- weight :权重,配置在readhost 中作为读节点的权重
-
usingDecrypt :是否对密码加密,默认否=0, 如需要开启配置=1,同时使用加密程序对密码加密,加密命令为:
# java -cp Mycat-server-1.6-RELEASE.jar io.mycat.util.DecryptUtil 1:host:user:password
其中 Mycat-server-1.6-RELEASE.jar 位于 mycat/lib 目录中,1:host:user:password,其中 1 表示 db端加密标识
能耍的时候就一定要耍,不能耍的时候一定要学。
--天道酬勤,贵在坚持posted on 2019-04-17 23:34 zhangyukun 阅读(272) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号