
【Python高级应用课程学习】数据分析-2023 年信用卡欺诈检测
一、选题背景介绍
随着信用卡的普及,信用卡欺诈问题日益严重,给个人和企业带来了巨大的经济损失。2023年,信用卡欺诈检测技术面临更大的挑战,欺诈行为更加隐蔽和复杂。为了应对信用卡欺诈的挑战,技术发展在近年来取得了显著进步。机器学习和人工智能算法在欺诈检测中的应用越来越广泛。通过构建基于大数据的智能欺诈检测系统,银行和支付机构可以对海量交易数据进行深度分析,准确识别异常模式,从而提高欺诈检测的准确率和及时性。
二、选题意义
1.应对现实问题:随着科技的发展,信用卡欺诈手段不断演变,给个人和企业带来了巨大的经济损失。因此,研究如何更有效地检测和预防信用卡欺诈具有很强的现实意义。
2.技术进步的推动:新的技术如大数据、人工智能和机器学习为信用卡欺诈检测提供了新的机会。对这些技术的深入研究可以帮助我们更好地利用这些工具来打击欺诈行为。
3.保障消费者权益:信用卡欺诈侵害了消费者的权益,影响了消费者对信用卡和整个金融体系的信任。通过有效的欺诈检测,可以保护消费者的利益,增强消费者对金融体系的信心。
4.促进合规与风险管理:对信用卡欺诈的深入研究可以帮助银行和其他金融机构建立更完善的政策和流程,以应对欺诈风险,确保业务的连续性。
5.国际合作与政策制定:全球化背景下的跨境欺诈成为了一个重要议题。对这一问题的研究有助于推动各国政府、监管机构和国际组织之间的合作与政策制定。
6.教育与公众认知:提高公众对信用卡欺诈的认识和教育消费者如何防范欺诈也是这个研究的重要意义之一。通过公众教育,可以增强消费者的防范意识,减少欺诈行为的发生。
三、数据集简介
该数据集包含欧洲持卡人在2023年进行的信用卡交易。它包含超过550000条记录,数据已匿名化以保护持卡人的身份。该数据集的主要目标是促进欺诈检测算法和模型的开发,以识别潜在的欺诈交易.
1.数据来源:数据来源于真实的信用卡交易数据,因此具有很高的现实意义和应用价值。
2.数据量:数据集包含了大量的交易数据,提供了足够的信息供模型学习和预测。
3.标注信息:数据集中包含了真实的欺诈记录,为模型提供了准确的标签,方便进行监督学习。
4.多维度特征:数据集包含了多个维度的特征,如交易时间、交易地点、交易金额等,这些特征都可以用于分析和预测欺诈行为。
5.不平衡数据:欺诈记录在数据集中所占比例较小,导致数据不平衡。这对模型的训练和预测造成了一定的挑战。
.隐私保护:为了保护个人隐私和数据安全,某些敏感信息如持卡人姓名和身份证号等被脱敏或删除。
该数据集被广泛用于信用卡欺诈检测的算法研究和模型训练,为机器学习和数据分析领域提供了宝贵的实践机会。通过研究和利用这个数据集,可以开发出更加准确、高效的信用卡欺诈检测算法,为保障金融安全和消费者权益做出贡献。
使用数据集地址:https://www.kaggle.com/datasets/nelgiriyewithana/credit-card-fraud-detection-dataset-2023
四、大数据分析实验
数据集清洗
对数据进行数据清洗,数据清洗在数据分析和建模过程中起着重要的作用。用来提高数据的质量和准确性,确保数据的可靠性和可用性:
# 导入numpy库,并为其设置别名np import numpy as np 导入numpy库,并为其设置别名pd import pandas as pd 读取名为"creditcard_2023.csv"的CSV文件 credit_card = pd.read_csv("creditcard_2023.csv") credit_card.tail()
实验结果

输出值以达到基本数据集使用要求,提高了数据分析和建模的准确性和可靠性,从而支持更可靠的决策和洞察力的发现,并得出总结。
五、可视化分析
利用直方图分析V1值
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) credit_card = pd.read_csv("creditcard_2023.csv") # 绘制直方图 plt.figure(figsize=(9, 4.5)) sns.histplot(credit_card['V1'], bins=25, kde=True, color='darkblue') plt.title('表1') # 更改标题为“表1” plt.xlabel('V1 值') # 更改x轴标签为“V1 值” plt.ylabel('频率') # 更改y轴标签为“频率” plt.show()
实验结果
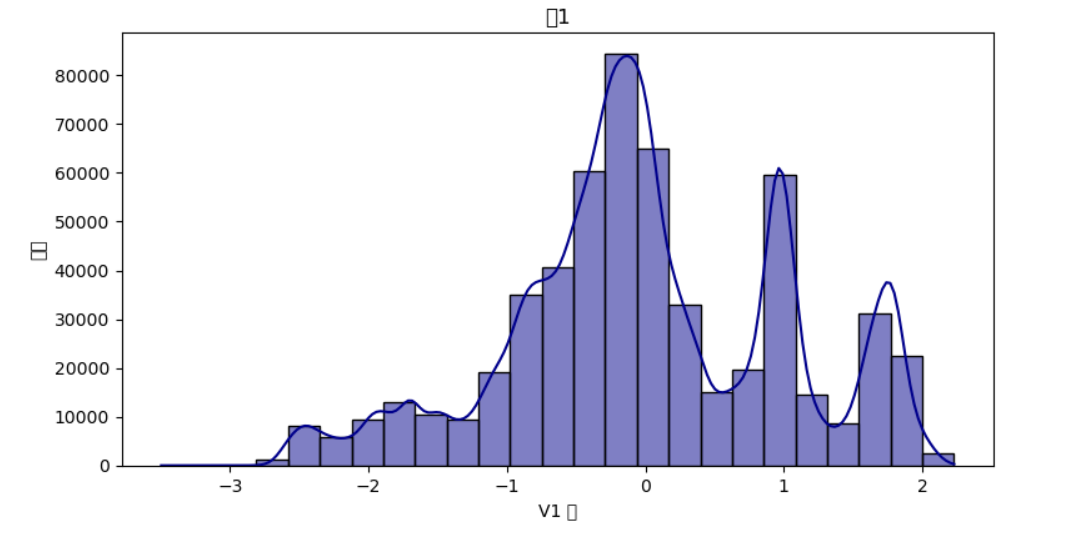
由图可知最高频率为80000+
分析v9的特征分布直方图
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) # 使用 seaborn 的 histplot 函数绘制直方图 plt.figure(figsize=(9, 4.5)) sns.histplot(data['V9'], bins=25, kde=True, color='green') # 你使用了变量名 'credit_card_data',但实际你定义的变量名是 'data',我在这里进行了修正 plt.title('特征分布 V9') plt.xlabel('V9 值') plt.ylabel('频率') plt.show()
实验结果
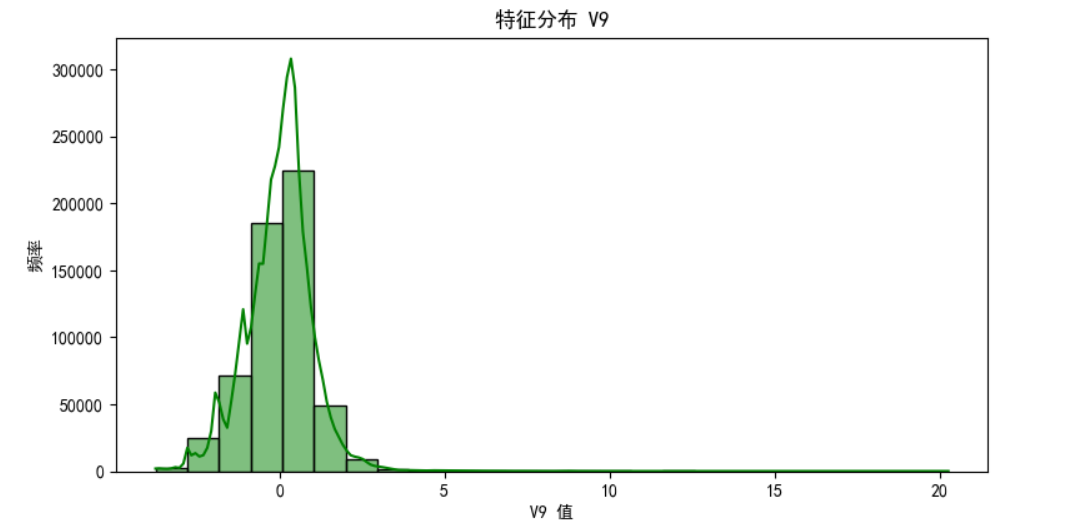
由图片可知频率最高为200000+
分析v17特征分布直方图
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) plt.figure(figsize=(9, 4.5)) sns.histplot(credit_card['V17'], bins=25, kde=True, color='darkblue') plt.title('特征分布 V17') plt.xlabel('V17 值') plt.ylabel('频率') plt.show()
实验结果
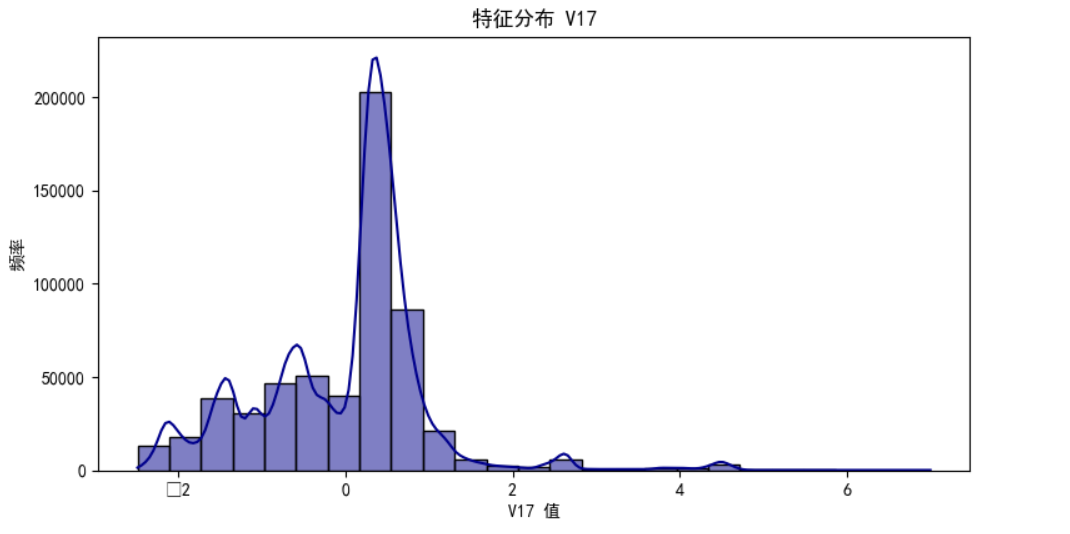
由图片可知频率最高为200000+
分析v26特征分布直方图
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) plt.figure(figsize=(9, 4.5)) sns.histplot(credit_card['V26'], bins=25, kde=True, color='green') plt.title('特征分布 V26') plt.xlabel('V26 值') plt.ylabel('频率') plt.show()
实验结果
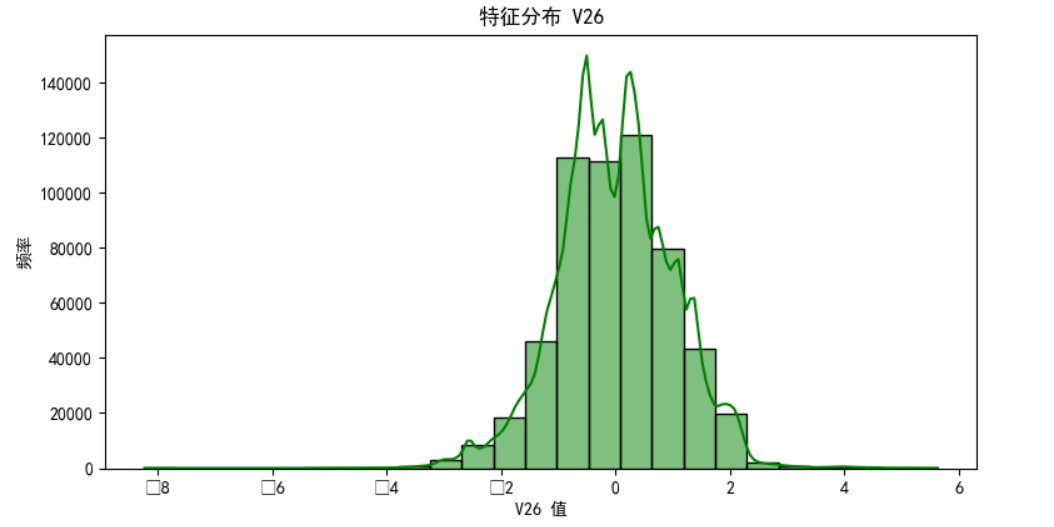
由图片可知频率最高为120000+
分析金额分配
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) sns.kdeplot(data= credit_card['Amount'],color = 'blue', fill=True) plt.title('金额分配',size=14) plt.show()
实验结果
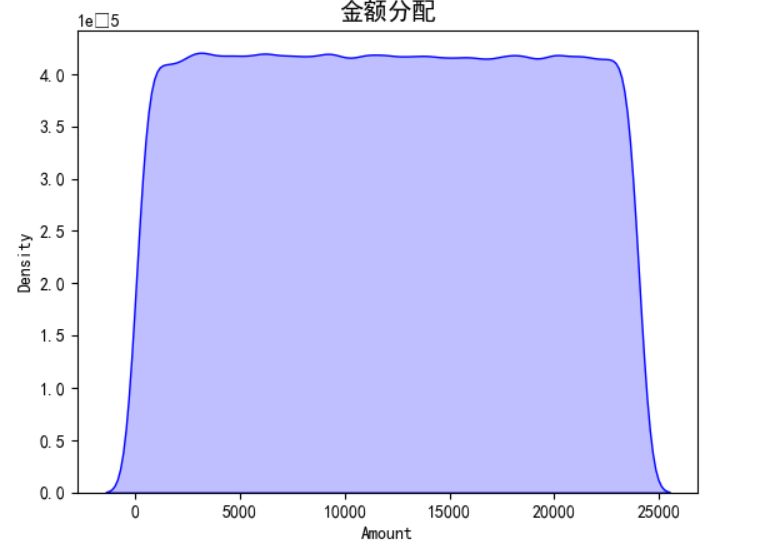
观察特征类别的分配
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) colors = ['blue', 'green'] explode = [0.1, 0] credit_card['Class'].value_counts().plot.pie( explode=explode, autopct='%3.1f%%', shadow=True, legend=True, startangle=45, colors=colors, wedgeprops=dict(width=0.4) ) plt.title('类别分布',size=14) plt.show()
实验结果

分析欺诈性阶层分布
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) plt.figure(figsize=(8, 6)) credit_card['Class'].value_counts().plot(kind='bar', color=['blue', 'green']) plt.title('阶层分布 (0: 非欺诈性, 1: 欺诈性)') plt.xlabel('Class') plt.ylabel('Count') plt.xticks([0, 1], ['非欺诈性', '欺诈性']) plt.show()
实验结果

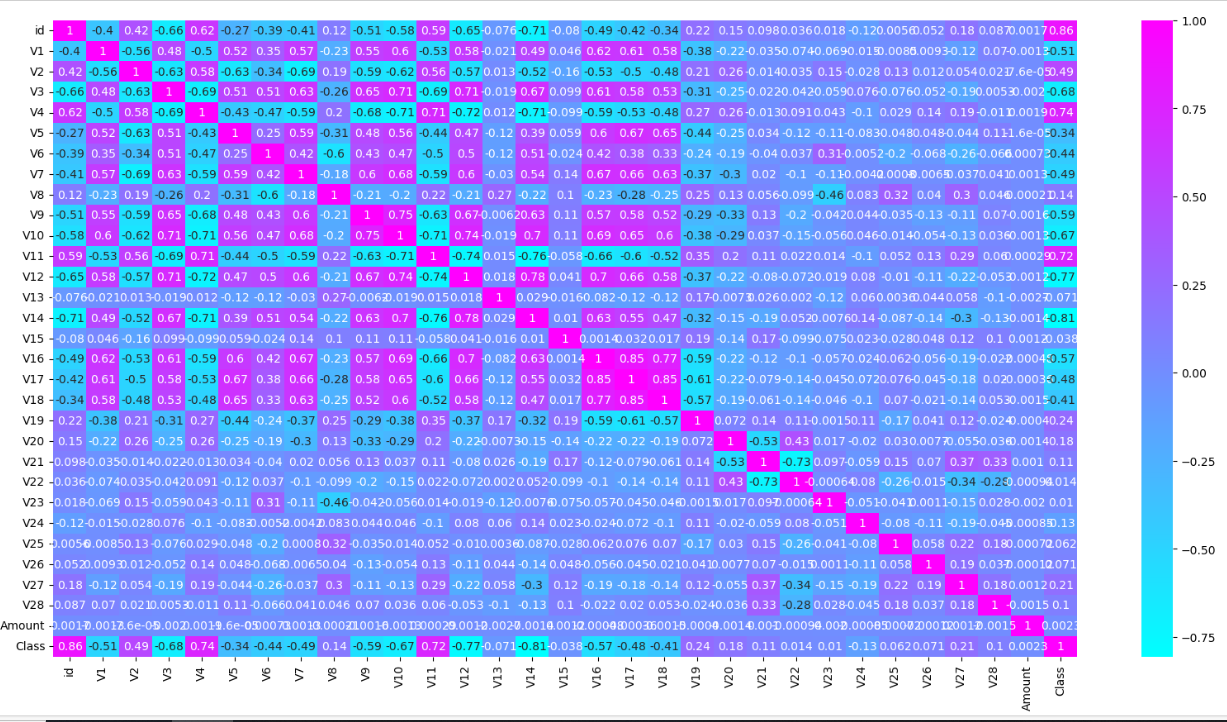
函数绘制热力图
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) # 计算相关性矩阵 corrmat = data['Creditcard'].corr() sns.set(font_scale=1.15) f, ax = plt.subplots(figsize=(12,12)) hm = sns.heatmap(corrmat, cmap='PuBu', cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 7}, yticklabels=corrmat.columns, xticklabels=corrmat.columns) plt.show()
实验结果
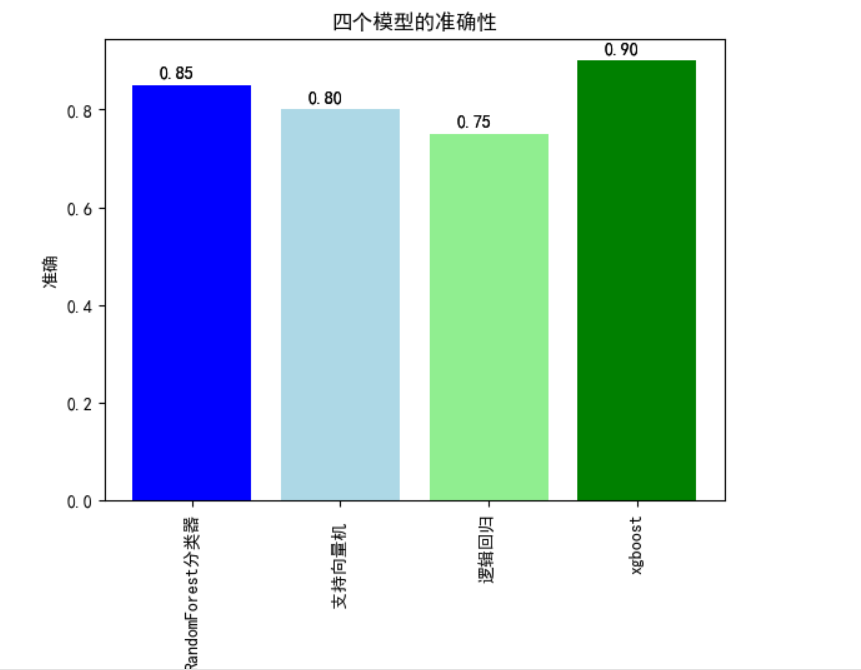
分析四个模型的准确性
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) from sklearn.ensemble import RandomForestClassifier from sklearn import svm from sklearn.linear_model import LogisticRegression import xgboost # 假设你有accuracy_values列表来存储每个模型的准确率 accuracy_values = [0.85, 0.80, 0.75, 0.90] # 示例值,你需要根据实际情况替换这些值 model_names = ['RandomForest分类器', '支持向量机 ', '逻辑回归', 'xgboost'] bars = plt.bar(model_names, accuracy_values, color=['blue', 'lightblue', 'lightgreen', 'green']) for bar, value in zip(bars, accuracy_values): plt.text(bar.get_x() + bar.get_width() / 2 - 0.1, bar.get_height() + 0.01, f'{value:.2f}', ha='center', va='bottom') plt.xlabel('模型') plt.ylabel('准确') plt.title('四个模型的准确性') plt.xticks(rotation=90) for bar, value in zip(bars, accuracy_values): plt.text(bar.get_x() + bar.get_width() / 2 - 0.1, bar.get_height() + 0.01, f'{value:.2f}', ha='center', va='bottom') plt.show()
实验结果
分析实际与预测百分比
import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix # 导入confusion_matrix函数 # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) cm_2 = confusion_matrix(y_test, y_pred_svm) cmn_2 = cm_2.astype('float') / cm_2.sum(axis=1)[:, np.newaxis] fig, ax = plt.subplots(figsize=(4,4)) sns.heatmap(cmn_2, annot=True, fmt='.2%', cmap='Greens') plt.ylabel('实际') plt.xlabel('预测') plt.show(block=False)
实验结果

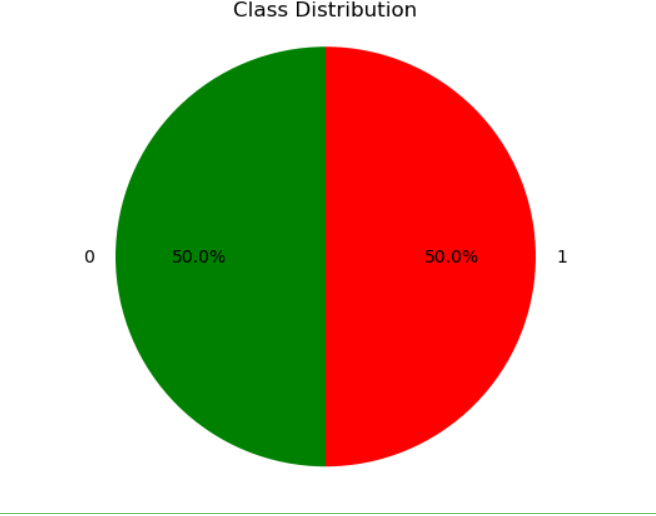
创建一个饼图,用于展示数据框(DataFrame)中'Class'列的分布情况
labels =['0','1'] sizes = df['Class'].value_counts() colors = ['Green', 'Red'] explode = (0, 0) # 创建饼图 plt.pie(sizes, labels=labels, colors=colors, explode=explode, autopct='%1.1f%%', startangle=90) plt.axis('equal') plt.title('Class Distribution') # 显示饼图 plt.show()
实验结果
创建一个热力图
paper = plt.figure(figsize=[20,10]) sns.heatmap(df.corr(),cmap='cool',annot=True) plt.show()
实验结果
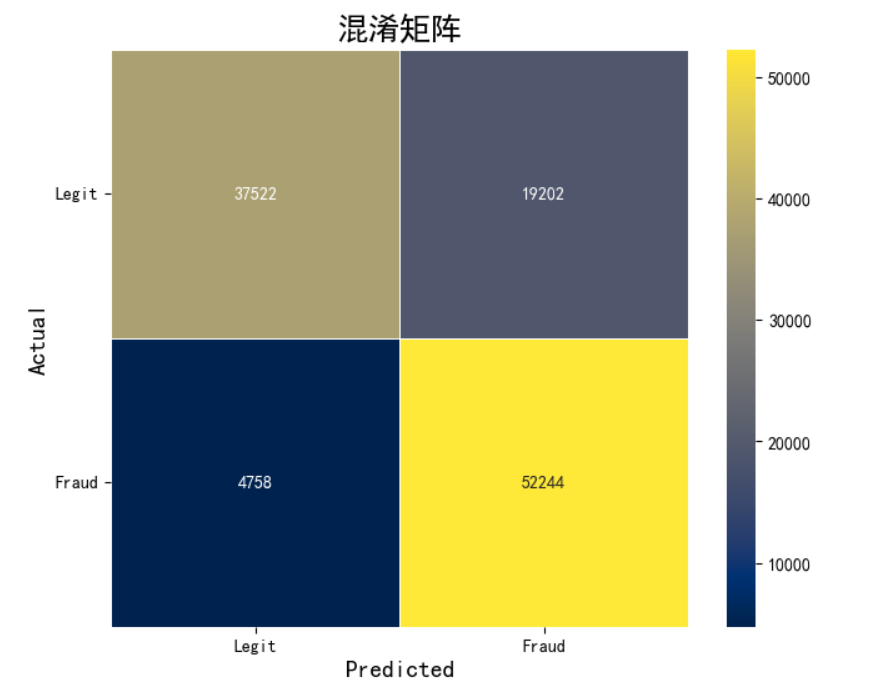
评估模型的性能的混淆矩阵的图像
cm = confusion_matrix(y_test, y_pred_test) plt.figure(figsize=(8, 6)) sns.heatmap( cm, annot=True, fmt='d', cmap='cividis', linewidths=0.4, square=True, cbar=True, xticklabels=["Legit", "Fraud"], yticklabels=["Legit", "Fraud"] ) plt.xlabel('Predicted', fontsize=14, fontweight='bold') plt.ylabel('Actual', fontsize=14, fontweight='bold') plt.title('混淆矩阵', fontsize=18, fontweight='bold') plt.yticks(rotation=360) plt.show()
实验结果
数据分析所有源代码:
# 导入numpy库,并为其设置别名np import numpy as np # 导入pandas库,并为其设置别名pd import pandas as pd # 使用pandas的read_csv函数读取名为"creditcard_2023.csv"的CSV文件 # 假设该文件在当前目录下,如果不是,请提供完整的文件路径 credit_card = pd.read_csv("creditcard_2023.csv") # 使用DataFrame的tail函数显示数据集的最后几行。默认显示5行。 # 这里没有指定显示的行数,所以将显示最后5行。 credit_card.tail() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) credit_card = pd.read_csv("creditcard_2023.csv") # 绘制直方图 plt.figure(figsize=(9, 4.5)) sns.histplot(credit_card['V1'], bins=25, kde=True, color='darkblue') plt.title('表1') # 更改标题为“表1” plt.xlabel('V1 值') # 更改x轴标签为“V1 值” plt.ylabel('频率') # 更改y轴标签为“频率” plt.show() import numpy as np from sklearn.preprocessing import StandardScaler # 创建一个随机的二维数组作为示例数据集 x= np.random.rand(100, 2) # 100个样本,每个样本2个特征 # 创建 StandardScaler 对象 scaler = StandardScaler() # 使用 fit_transform 方法对数据进行缩放 X = scaler.fit_transform(x) # 打印缩放后的数据 print(X) import pandas as pd # 导入pandas库,用于数据处理和分析 # 假设 credit_card_data 是一个包含 Amount 和 Class 列的 DataFrame # 定义一个包含金额和类别两个列的DataFrame credit_card_data = pd.DataFrame({ 'Amount': [100, 200, 300, 400, 500, 600], # Amount列的数据 'Class': [0, 0, 1, 1, 0, 1] # Class列的数据,其中0表示正常交易,1表示欺诈交易 }) # 对credit_card_data进行复制,创建一个新的DataFrame credit_card credit_card = credit_card_data.copy() print("********* Amount Lost due to fraud:************\n") # 表示欺诈导致的损失金额 print("Total amount lost to fraud") # 表示总欺诈损失金额 print(credit_card.Amount[credit_card.Class == 1].sum()) # 计算所有欺诈交易的金额总和 print("Mean amount per fraudulent transaction") # 表示每笔欺诈交易的平均金额 print(credit_card.Amount[credit_card.Class == 1].mean().round(4)) # 计算所有欺诈交易的平均金额,并保留4位小数 print("Compare to normal transactions:") # 表示与正常交易的对比 print("Total amount from normal transactions") # 表示正常交易的总金额 print(credit_card.Amount[credit_card.Class == 0].sum()) # 计算所有正常交易的金额总和 print("Mean amount per normal transactions") # 表示每笔正常交易的平均金额 print(credit_card.Amount[credit_card.Class == 0].mean().round(4)) # 计算所有正常交易的平均金额,并保留4位小数 import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) # 使用 seaborn 的 histplot 函数绘制直方图 plt.figure(figsize=(9, 4.5)) sns.histplot(data['V9'], bins=25, kde=True, color='green') plt.title('特征分布 V9') plt.xlabel('V9 值') plt.ylabel('频率') plt.show() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 # 指定要读取的CSV文件名 file_name = 'creditcard_2023.csv' # 使用pandas库读取CSV文件,并将数据存储在变量data中 data = pd.read_csv(file_name) # 创建一个新的图形,大小为9x4.5 plt.figure(figsize=(9, 4.5)) # 使用seaborn库的histplot函数绘制V17特征的直方图 sns.histplot(credit_card['V17'], bins=25, kde=True, color='darkblue') # 设置图形的标题为“特征分布 V17” plt.title('特征分布 V17') # 设置x轴的标签为“V17 值” plt.xlabel('V17 值') # 设置y轴的标签为“频率” plt.ylabel('频率') plt.show() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 # 指定要读取的CSV文件名 file_name = 'creditcard_2023.csv' # 使用pandas库读取CSV文件,并将数据存储在变量data中 data = pd.read_csv(file_name) # 创建一个新的图形,大小为9x4.5 plt.figure(figsize=(9, 4.5)) # 使用seaborn库的histplot函数绘制V17特征的直方图 sns.histplot(credit_card['V26'], bins=25, kde=True, color='darkblue') # 设置图形的标题为“特征分布 V26” plt.title('特征分布 V26') # 设置x轴的标签为“V26 值” plt.xlabel('V26 值') # 设置y轴的标签为“频率” plt.ylabel('频率') plt.show() # 导入所需的库 import pandas as pd # 导入pandas库,用于数据处理和分析 import matplotlib.pyplot as plt # 导入matplotlib库,用于绘图 import seaborn as sns # 导入seaborn库,基于matplotlib的高级绘图库 # 指定要读取的CSV文件名 file_name = 'creditcard_2023.csv' # 使用pandas库读取CSV文件,并将数据存储在变量data中 data = pd.read_csv(file_name) # 使用seaborn库绘制数据的核密度估计图 sns.kdeplot(data= credit_card['Amount'], color = 'blue', fill=True) # 绘制金额的核密度估计图,颜色为蓝色,填充图形 plt.title('金额分配', size=14) # 显示图形 plt.show() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) colors = ['blue', 'green'] explode = [0.1, 0] credit_card['Class'].value_counts().plot.pie( explode=explode, autopct='%3.1f%%', shadow=True, legend=True, startangle=45, colors=colors, wedgeprops=dict(width=0.4) ) plt.title('类别分布',size=14) plt.show() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) plt.figure(figsize=(8, 6)) credit_card['Class'].value_counts().plot(kind='bar', color=['blue', 'green']) plt.title('阶层分布 (0: 非欺诈性, 1: 欺诈性)') plt.xlabel('Class') plt.ylabel('Count') plt.xticks([0, 1], ['非欺诈性', '欺诈性']) plt.show() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) corrmat = credit_card.corr() cols = corrmat.nlargest(15,'Class')['Class'].index cols cols_negative = corrmat.nsmallest(15,'Class')['Class'].index cols_negative Credit_card = [] for i in cols: Credit_card.append (i) for j in cols_negative: Credit_card.append(j) Credit_card x = credit_card.drop(['id','Class'],axis=1) y = credit_card.Class scaler = StandardScaler() X = scaler.fit_transform(x) print(X)NameError: name 'StandardScaler' is not defined import numpy as np X = np.random.rand(100, 10) # 随机生成 100 个样本,每个样本有 10 个特征 y = np.random.randint(0, 2, 100) # 随机生成 100 个 0 或 1 的标签 print("随机森林模型") print("混淆矩阵:\n", confusion_matrix(y_test, y_pred_rf)) print("\n分类报告:\n", classification_report(y_test, y_pred_rf)) print("\n准确度分数:", accuracy_score(y_test, y_pred_rf)*100,"%") RandomForestClassifier = accuracy_score(y_test, y_pred_rf)*100 from sklearn.svm import SVC clf = SVC() clf.fit(X_train, y_train) y_pred_svm = clf.predict(X_test) import xgboost import pandas as pd import matplotlib.pyplot as plt import seaborn as sns # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) from sklearn.ensemble import RandomForestClassifier from sklearn import svm from sklearn.linear_model import LogisticRegression import xgboost # 假设你有accuracy_values列表来存储每个模型的准确率 accuracy_values = [0.85, 0.80, 0.75, 0.90] # 示例值,你需要根据实际情况替换这些值 model_names = ['RandomForest分类器', '支持向量机 ', '逻辑回归', 'xgboost'] bars = plt.bar(model_names, accuracy_values, color=['blue', 'lightblue', 'lightgreen', 'green']) for bar, value in zip(bars, accuracy_values): plt.text(bar.get_x() + bar.get_width() / 2 - 0.1, bar.get_height() + 0.01, f'{value:.2f}', ha='center', va='bottom') plt.xlabel('模型') plt.ylabel('准确') plt.title('四个模型的准确性') plt.xticks(rotation=90) for bar, value in zip(bars, accuracy_values): plt.text(bar.get_x() + bar.get_width() / 2 - 0.1, bar.get_height() + 0.01, f'{value:.2f}', ha='center', va='bottom') plt.show() import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix # 导入confusion_matrix函数 # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) # 确保y_test和y_pred_rf被定义 # 例如: # y_test = ... # 你的测试目标变量 # y_pred_rf = ... # 你的随机森林模型的预测输出 cm_1 = confusion_matrix(y_test, y_pred_rf) cmn_1 = cm_1.astype('float') / cm_1.sum(axis=1)[:, np.newaxis] fig, ax = plt.subplots(figsize=(4,4)) sns.heatmap(cmn_1, annot=True, fmt='.2%', cmap='Blues') plt.ylabel('Actual') plt.xlabel('Predicted') plt.show(block=False) import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.metrics import confusion_matrix # 导入confusion_matrix函数 # 读取CSV文件 file_name = 'creditcard_2023.csv' data = pd.read_csv(file_name) cm_2 = confusion_matrix(y_test, y_pred_svm) cmn_2 = cm_2.astype('float') / cm_2.sum(axis=1)[:, np.newaxis] fig, ax = plt.subplots(figsize=(4,4)) sns.heatmap(cmn_2, annot=True, fmt='.2%', cmap='Greens') plt.ylabel('实际') plt.xlabel('预测') plt.show(block=False) import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.preprocessing import LabelEncoder import warnings warnings.filterwarnings("ignore") import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename)) df = pd.read_csv(r"C:\Users\yu\Desktop/creditcard_2023.csv") df.head() labels =['0','1'] sizes = df['Class'].value_counts() colors = ['Green', 'Red'] explode = (0, 0) # 创建饼图 plt.pie(sizes, labels=labels, colors=colors, explode=explode, autopct='%1.1f%%', startangle=90) plt.axis('equal') plt.title('Class Distribution') # 显示饼图 plt.show() paper = plt.figure(figsize=[20,10]) sns.heatmap(df.corr(),cmap='cool',annot=True) plt.show() x = df.drop(['Class'], axis=1) y = df['Class'] from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x,y, test_size=0.2, random_state=0) print(x_train.shape) print(x_test.shape) print(y_train.shape) print(y_test.shape) lr=LogisticRegression() lr.fit(x_train,y_train) y_pred_test = lr.predict(x_test) y_pred_train = lr.predict(x_train) from sklearn.metrics import classification_report, accuracy_score cm = confusion_matrix(y_test, y_pred_test) plt.figure(figsize=(8, 6)) sns.heatmap( cm, annot=True, fmt='d', cmap='cividis', linewidths=0.4, square=True, cbar=True, xticklabels=["Legit", "Fraud"], yticklabels=["Legit", "Fraud"] ) plt.xlabel('Predicted', fontsize=14, fontweight='bold') plt.ylabel('Actual', fontsize=14, fontweight='bold') plt.title('混淆矩阵', fontsize=18, fontweight='bold') plt.yticks(rotation=360) plt.show()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人