黑马JavaWeb-day06、07、08(SQL部分)
MYSQL概述
数据模型
关系型数据库(RDBMS):建立在关系模型基础上,由多张相互连接的二维表组成的数据库。
- 使用表存储数据,格式统一,便于维护
- 使用SQL语言操作,标准统一,使用方便,可用于复杂查询
SQL简介
SQL:一门操作关系型数据库的编程语言,定义操作所有关系型数据库的统一标准。
通用语法:
- SQL语句可以单行或多行书写,以分号结尾。
- SQL语句可以使用空格/缩进来增强语句的可读性
- MYSQL数据库的SQL语句不区分大小写。
- 注释:
- 单行注释:-- 注释内容或# 注释内容
- 多行注释:/注释内容/
SQL分类
- DDL:data definition language,数据定义语言,用来定义数据库对象(数据库、表、字段)
- DML:data manipulation language,数据操作语言,用来对数据库表中的数据进行增删改
- DQL:data query language,数据查询语言,用来查询数据库表中的记录
- DCL:data control language,数据控制语言,用来创建数据库用户、控制数据库的访问权限
DDL
数据库操作
查看所有数据库
show databases;

创建数据库
create database db_name;
create语句有一个可选项,表示只有在db_name不存在的时候才创建它
create database if not exists db_name;

使用数据库
use db_name;

查询当前正在use的数据库
select database();

删除数据库
drop database [if exists] db_name;

上面的database也可以换成schema
表操作
创建表
create table tb_name(
字段1 字段类型 [约束] [comment 字段1注释],
......
字段n 字段类型 [约束] [comment 字段n注释]
)[comment 表注释];

约束:作用域表中字段上的规则,用于限制存储在表中的数据,保证数据库的正确性、有效性、完整性。

create table tb_user(
id int primary key auto_increment comment 'ID 唯一标识',
username varchar(20) not null unique comment '用户名',
name varchar(10) not null comment '姓名',
age int comment '年龄',
gender char(1) default '男' comment '性别'
) comment '用户表';
MYSQL中的常见数据类型



查询数据库下的表
show tables;
查看指定表结构
desc tb_name;

修改表结构

alter table tb_user add qq varchar(11) comment 'QQ';
drop table [if exists] tb_name;
但现在有了GUI,基本上不会用SQL语句了,而是直接用GUI操作代替了。
DML
增(INSERT)
指定字段添加数据:
insert into tb_name(字段名1,字段名2) values(值1,值2);
全部字段添加数据
insert into tb_name values(值1,值2,...);
批量添加数据(指定字段)
insert into tb_name(字段名1,字段名2) values(值1,值2),(值1,值2);
批量添加数据(全部字段)
insert into tb_name values(值1,值2,...),(值1,值2,...);
改(UPDATE)
update tb_name set 字段名1 = 值1,字段名2 = 值2,...[where 条件]
update tb_user set name='张三' where id = 1;
删(DELETE)
删除记录
delete from tb_name [where 条件];
DQL
基本查询
创建数据库和表
create database db02; -- 创建数据库
use db02; -- 切换数据库
-- 员工管理(带约束)
create table tb_emp (
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate date comment '入职时间',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
-- 准备测试数据
INSERT INTO tb_emp (id, username, password, name, gender, image, job, entrydate, create_time, update_time) VALUES
(1, 'jinyong', '123456', '金庸', 1, '1.jpg', 4, '2000-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:35'),
(2, 'zhangwuji', '123456', '张无忌', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:37'),
(3, 'yangxiao', '123456', '杨逍', 1, '3.jpg', 2, '2008-05-01', '2022-10-27 16:35:33', '2022-10-27 16:35:39'),
(4, 'weiyixiao', '123456', '韦一笑', 1, '4.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:35:41'),
(5, 'changyuchun', '123456', '常遇春', 1, '5.jpg', 2, '2012-12-05', '2022-10-27 16:35:33', '2022-10-27 16:35:43'),
(6, 'xiaozhao', '123456', '小昭', 2, '6.jpg', 3, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:45'),
(7, 'jixiaofu', '123456', '纪晓芙', 2, '7.jpg', 1, '2005-08-01', '2022-10-27 16:35:33', '2022-10-27 16:35:47'),
(8, 'zhouzhiruo', '123456', '周芷若', 2, '8.jpg', 1, '2014-11-09', '2022-10-27 16:35:33', '2022-10-27 16:35:49'),
(9, 'dingminjun', '123456', '丁敏君', 2, '9.jpg', 1, '2011-03-11', '2022-10-27 16:35:33', '2022-10-27 16:35:51'),
(10, 'zhaomin', '123456', '赵敏', 2, '10.jpg', 1, '2013-09-05', '2022-10-27 16:35:33', '2022-10-27 16:35:53'),
(11, 'luzhangke', '123456', '鹿杖客', 1, '11.jpg', 2, '2007-02-01', '2022-10-27 16:35:33', '2022-10-27 16:35:55'),
(12, 'hebiweng', '123456', '鹤笔翁', 1, '12.jpg', 2, '2008-08-18', '2022-10-27 16:35:33', '2022-10-27 16:35:57'),
(13, 'fangdongbai', '123456', '方东白', 1, '13.jpg', 1, '2012-11-01', '2022-10-27 16:35:33', '2022-10-27 16:35:59'),
(14, 'zhangsanfeng', '123456', '张三丰', 1, '14.jpg', 2, '2002-08-01', '2022-10-27 16:35:33', '2022-10-27 16:36:01'),
(15, 'yulianzhou', '123456', '俞莲舟', 1, '15.jpg', 2, '2011-05-01', '2022-10-27 16:35:33', '2022-10-27 16:36:03'),
(16, 'songyuanqiao', '123456', '宋远桥', 1, '16.jpg', 2, '2010-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:05'),
(17, 'chenyouliang', '12345678', '陈友谅', 1, '17.jpg', null, '2015-03-21', '2022-10-27 16:35:33', '2022-10-27 16:36:07'),
(18, 'zhang1', '123456', '张一', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:09'),
(19, 'zhang2', '123456', '张二', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:11'),
(20, 'zhang3', '123456', '张三', 1, '2.jpg', 2, '2018-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:13'),
(21, 'zhang4', '123456', '张四', 1, '2.jpg', 2, '2015-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:15'),
(22, 'zhang5', '123456', '张五', 1, '2.jpg', 2, '2016-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:17'),
(23, 'zhang6', '123456', '张六', 1, '2.jpg', 2, '2012-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:19'),
(24, 'zhang7', '123456', '张七', 1, '2.jpg', 2, '2006-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:21'),
(25, 'zhang8', '123456', '张八', 1, '2.jpg', 2, '2002-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:23'),
(26, 'zhang9', '123456', '张九', 1, '2.jpg', 2, '2011-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:25'),
(27, 'zhang10', '123456', '张十', 1, '2.jpg', 2, '2004-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:27'),
(28, 'zhang11', '123456', '张十一', 1, '2.jpg', 2, '2007-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:29'),
(29, 'zhang12', '123456', '张十二', 1, '2.jpg', 2, '2020-01-01', '2022-10-27 16:35:33', '2022-10-27 16:36:31');

查询多个字段:
select 字段1,字段2,字段3 from tb_name;
查询所有字段(通配符)
select * from tb_name;
设置别名
select 字段1 [as 别名1], 字段2[as 别名2] from 表名;
去除重复记录
select distinct 字段列表 from tb_name;
-- 1. 查询指定字段name、entrydata 并返回
select name, entrydate from tb_emp;
-- 2. 查询返回所有字段
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;
select * from tb_emp;
-- 3. 查询所有员工的name、entrydata并起别名(姓名、入职日期)
select name as 姓名, entrydate as 入职日期 from tb_emp;
-- 4. 查询已有员工关联了哪几种职位(distinct 关键字去重)
select distinct job from tb_emp;
条件查询(where)
select 字段列表 from tb_name where 条件列表;

-- 1. 查询指定字段name、entrydata 并返回
select name, entrydate from tb_emp;
-- 2. 查询返回所有字段
select id, username, password, name, gender, image, job, entrydate, create_time, update_time from tb_emp;
select * from tb_emp;
-- 3. 查询所有员工的name、entrydata并起别名(姓名、入职日期)
select name as 姓名, entrydate as 入职日期 from tb_emp;
-- 4. 查询已有员工关联了哪几种职位(distinct 关键字去重)
select distinct job from tb_emp;
-- 1. 查询 姓名 为 杨逍 的员工信息
select * from tb_emp where name = '杨逍';
-- 2. 查询 id小于等于5 的员工信息
select * from tb_emp where id <= 5;
-- 3. 查询 没有分配职位 的员工信息
select * from tb_emp where job is null;
-- 4. 查询 有职位 的员工信息
select * from tb_emp where job is not null;
-- 5. 查询 密码字段不是‘123456’ 的员工信息
select * from tb_emp where password != '123456';
-- 查询 入职日期 在‘2000-01-01’ (包含) 到 '2010-01-01'(包含) 之间的员工信息
select * from tb_emp where entrydate >= '2000-01-01' and entrydate <= '2010-01-01';
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01';
-- 查询职位是2(讲师),3(学生主管),4(教研主管)的员工信息
select * from tb_emp where job in (2,3,4);
-- 查询姓名为两个字的的员工
select * from tb_emp where name like '__';
-- 查询姓张的员工
select * from tb_emp where name like '张%';
分组查询(group by)
分组查询往往伴随聚合运算
聚合函数:将一列数据作为一个整体,进行纵向计算。
select 聚合函数(字段列表) from tb_name;
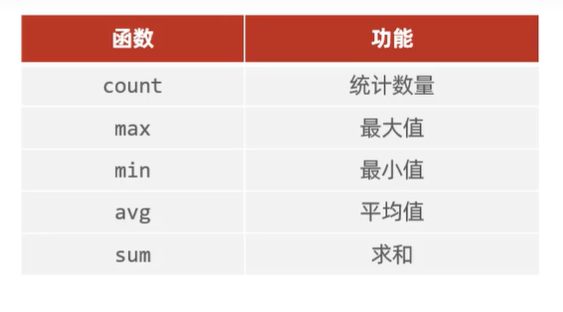
-- 1. 统计该企业员工数量 -- count
-- A。 count(字段)
select count(id) from tb_emp;
-- B.count(常量)
select count(1) from tb_emp;
-- count(*)
select count(*) from tb_emp;
-- 2. 统计该企业最早入职的员工 -min
select min(entrydate) from tb_emp;
-- 3.统计该企业员工id的平均值 avg
select avg(id) from tb_emp;
-- 4.统计该企业员工id的和 sum
select sum(id) from tb_emp;
需要注意null不参与所有聚合函数的运算
select 字段列表 from tb_name [where 条件] group by 字段名分组[having 分组后的过滤条件];
-- 分组
-- 1. 根据性别分组,统计男性和女性员工的数量 -count(*)
select gender,count(*) from tb_emp group by gender;
-- 2. 先查询入职时间在'2015-01-01'(包含)以前的员工,并对结果根据职位分组,获取员工数量大于2的职位
select job from tb_emp where entrydate <= '2015-01-01' group by job having count(*) >= 2;

排序查询(order by)
select 字段列表 from tb_name [where 条件列表] [group by 分组字段] order by 字段1 排序方式1, 字段2 排序方式2,...;
-- 排序方式
-- ASC:升序(默认值)
-- DESC:降序
-- 排序查询
-- 1. 根据入职时间,对员工进行升序排序
select * from tb_emp order by entrydate;
-- 2. 根据入职时间,对员工进行降序排序
select * from tb_emp order by entrydate desc ;
-- 3. 根据入职时间 对员工进行升序排序, 入职时间相同, 再按照更新时间进行降序排序
select * from tb_emp order by entrydate, update_time desc ;
分页查询(limit)
select 字段列表 from tb_name limit 起始索引,查询记录数;
-- 分页查询
-- 1. 从起始索引0 开始查询员工数据, 每页展示5条记录
select * from tb_emp limit 0,5;
-- 2. 查询 第1页 员工数据, 每页展示5条记录
select * from tb_emp limit 0,5;
-- 3. 查询 第2页 员工数据, 每页展示5条记录
select * from tb_emp limit 5,5;
-- 4. 查询 第3页 员工数据, 每页展示5条记录
select * from tb_emp limit 10,5;
-- 起始索引 = (页码 - 1)* 煤业展示的记录数
多表设计
一对多
只需要在多的一方增加关联一的一方的一个字段
-- 部门表
-- 员工表
create table tb_emp
(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID', -- 员工的归属部门
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
create table tb_dept
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
测试数据
-- 部门表测试数据
insert into tb_dept (id, name, create_time, update_time) values
(1,'学工部',now(),now()),
(2,'教研部',now(),now()),
(3,'咨询部',now(),now()),
(4,'就业部',now(),now()),
(5,'人事部',now(),now());
-- 员工表测试数据
INSERT INTO tb_emp
(id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time) VALUES
(1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()),
(2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()),
(3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()),
(4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()),
(5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()),
(6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()),
(7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()),
(8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()),
(9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()),
(10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()),
(11,'luzhangke','123456','鹿杖客',1,'11.jpg',1,'2007-02-01',1,now(),now()),
(12,'hebiweng','123456','鹤笔翁',1,'12.jpg',1,'2008-08-18',1,now(),now()),
(13,'fangdongbai','123456','方东白',1,'13.jpg',2,'2012-11-01',2,now(),now()),
(14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()),
(15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()),
(16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2010-01-01',2,now(),now()),
(17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());
但是上面两张表在数据库层面并没有建立关联,当删除父表中的记录时,子表中已经删除的父表信息依然存在,无法保证数据的一致性、完整性。
为了解决上面的问题需要外键
create table tb_name(
字段名 数据类型,
...
[constraint] [外键名称] foreign key (外键字段名) references 主表(字段名)
);
-- 建表完成后,添加外键
alter table tb_name add constraint 外键名称 foreign key(外键字段名) references 主表(字段名);
一对一
多用于单表的拆分,将一张表的基础字段放在一张表中,其他字段放在另一张表中,以提升效率。
多对多
实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
测试脚本
-- 学生表
create table tb_student(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
no varchar(10) comment '学号'
) comment '学生表';
-- 学生表测试数据
insert into tb_student(name, no) values ('黛绮丝', '2000100101'),('谢逊', '2000100102'),('殷天正', '2000100103'),('韦一笑', '2000100104');
-- 课程表
create table tb_course(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '课程名称'
) comment '课程表';
-- 课程表测试数据
insert into tb_course (name) values ('Java'), ('PHP'), ('MySQL') , ('Hadoop');
-- 学生课程表(中间表)
create table tb_student_course(
id int auto_increment comment '主键' primary key,
student_id int not null comment '学生ID',
course_id int not null comment '课程ID',
constraint fk_courseid foreign key (course_id) references tb_course (id),
constraint fk_studentid foreign key (student_id) references tb_student (id)
)comment '学生课程中间表';
-- 学生课程表测试数据
insert into tb_student_course(student_id, course_id) values (1,1),(1,2),(1,3),(2,2),(2,3),(3,4);
多表查询
数据准备
#建议:创建新的数据库
create database db04;
use db04;
-- 部门表
create table tb_dept
(
id int unsigned primary key auto_increment comment '主键ID',
name varchar(10) not null unique comment '部门名称',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '部门表';
-- 部门表测试
insert into tb_dept (id, name, create_time, update_time)
values (1, '学工部', now(), now()),
(2, '教研部', now(), now()),
(3, '咨询部', now(), now()),
(4, '就业部', now(), now()),
(5, '人事部', now(), now());
-- 员工表
create table tb_emp
(
id int unsigned primary key auto_increment comment 'ID',
username varchar(20) not null unique comment '用户名',
password varchar(32) default '123456' comment '密码',
name varchar(10) not null comment '姓名',
gender tinyint unsigned not null comment '性别, 说明: 1 男, 2 女',
image varchar(300) comment '图像',
job tinyint unsigned comment '职位, 说明: 1 班主任,2 讲师, 3 学工主管, 4 教研主管, 5 咨询师',
entrydate date comment '入职时间',
dept_id int unsigned comment '部门ID',
create_time datetime not null comment '创建时间',
update_time datetime not null comment '修改时间'
) comment '员工表';
-- 员工表测试数据
INSERT INTO tb_emp(id, username, password, name, gender, image, job, entrydate,dept_id, create_time, update_time)
VALUES
(1,'jinyong','123456','金庸',1,'1.jpg',4,'2000-01-01',2,now(),now()),
(2,'zhangwuji','123456','张无忌',1,'2.jpg',2,'2015-01-01',2,now(),now()),
(3,'yangxiao','123456','杨逍',1,'3.jpg',2,'2008-05-01',2,now(),now()),
(4,'weiyixiao','123456','韦一笑',1,'4.jpg',2,'2007-01-01',2,now(),now()),
(5,'changyuchun','123456','常遇春',1,'5.jpg',2,'2012-12-05',2,now(),now()),
(6,'xiaozhao','123456','小昭',2,'6.jpg',3,'2013-09-05',1,now(),now()),
(7,'jixiaofu','123456','纪晓芙',2,'7.jpg',1,'2005-08-01',1,now(),now()),
(8,'zhouzhiruo','123456','周芷若',2,'8.jpg',1,'2014-11-09',1,now(),now()),
(9,'dingminjun','123456','丁敏君',2,'9.jpg',1,'2011-03-11',1,now(),now()),
(10,'zhaomin','123456','赵敏',2,'10.jpg',1,'2013-09-05',1,now(),now()),
(11,'luzhangke','123456','鹿杖客',1,'11.jpg',5,'2007-02-01',3,now(),now()),
(12,'hebiweng','123456','鹤笔翁',1,'12.jpg',5,'2008-08-18',3,now(),now()),
(13,'fangdongbai','123456','方东白',1,'13.jpg',5,'2012-11-01',3,now(),now()),
(14,'zhangsanfeng','123456','张三丰',1,'14.jpg',2,'2002-08-01',2,now(),now()),
(15,'yulianzhou','123456','俞莲舟',1,'15.jpg',2,'2011-05-01',2,now(),now()),
(16,'songyuanqiao','123456','宋远桥',1,'16.jpg',2,'2007-01-01',2,now(),now()),
(17,'chenyouliang','123456','陈友谅',1,'17.jpg',NULL,'2015-03-21',NULL,now(),now());
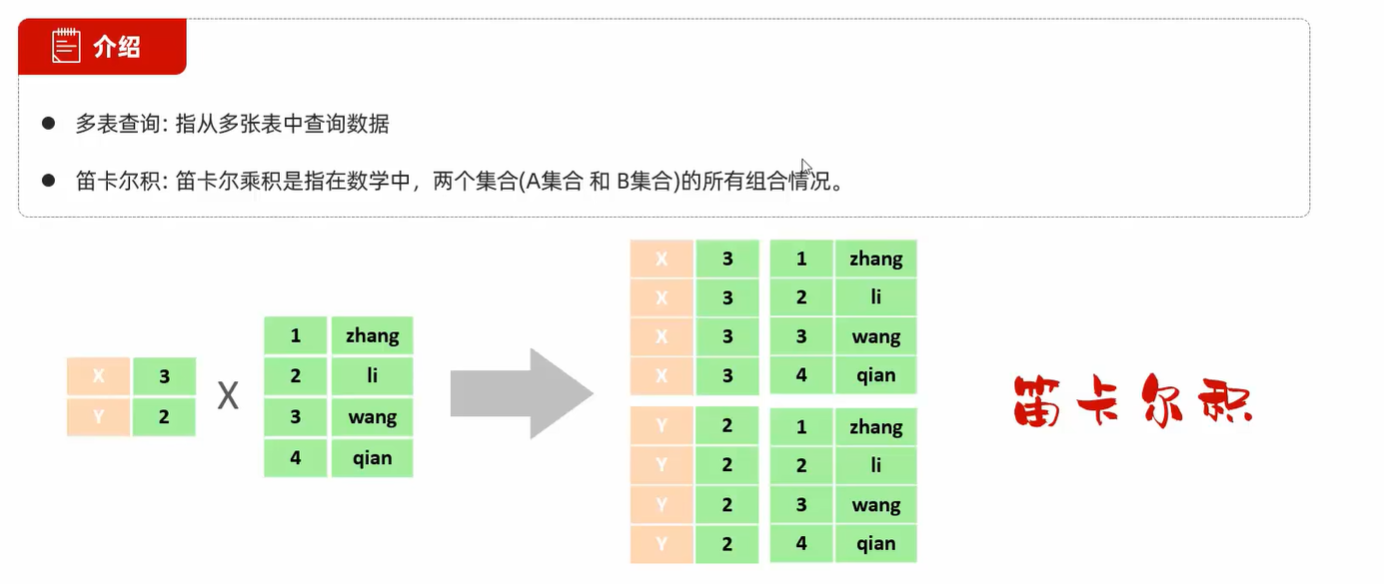

内连接
-- 隐式内连接
select 字段列表 from 表1,表2 where 条件...;
-- 显式内连接
select 字段列表 from 表1 [inner] join 表2 on 连接条件...;
-- A. 查询员工的姓名,及所属的部门名称(隐式内连接实现)
select tb_emp.name, tb_dept.name from tb_emp,tb_dept where tb_dept.id = tb_emp.dept_id;
-- B. 查询员工的姓名,及所属的部门名称(显式内连接实现)
select tb_emp.name, tb_dept.name from tb_emp inner join tb_dept on tb_dept.id = tb_emp.dept_id;
外连接
外连接是以其中一个表为标准
左外连接:
select 字段列表 from 表1 left [outer] join 表2 on 连接条件;
右外连接
select 字段列表 from 表1 right [outer] join 表2 on 连接条件;
-- A. 查询员工表 所有 员工的姓名, 和对应的部门名称 (左连接)
select e.name, d.name from tb_emp e left join tb_dept d on e.dept_id = d.id;
-- B. 查询部门表 所有 部门的名称, 和对应的员工名称 (右连接)
select e.name, d.name from tb_emp e right join tb_dept d on e.dept_id = d.id;
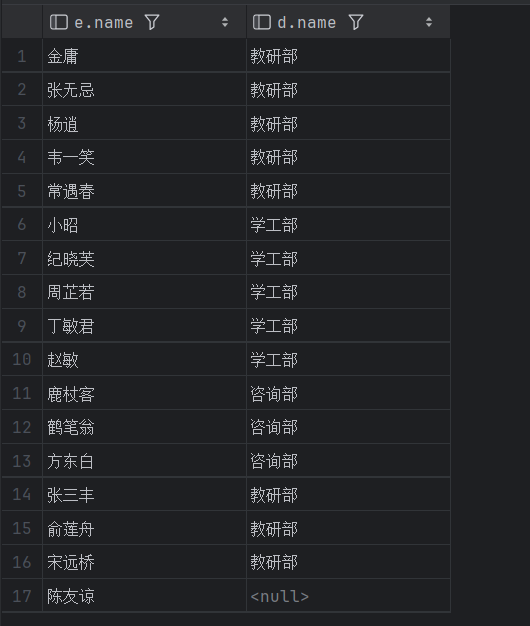
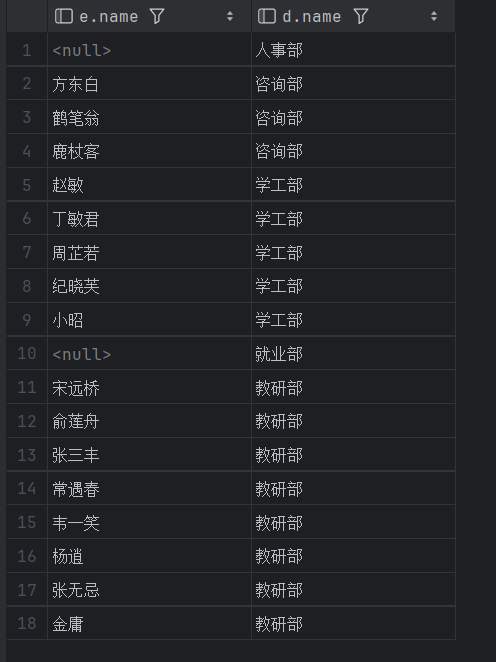
左外连接和右外连接可以相互转换,只需要把表的位置换一下即可。
子查询
SQL语句中嵌套select语句,成为嵌套查询,又称为子查询。
select * from t1 where column1 = (select column1 from t2 ...)


-- 标量子查询
-- A. 查询 “教研部” 的所有员工信息
select * from tb_emp where dept_id = (select id from tb_dept where name = '教研部');
-- B. 查询在 “方东白” 入职之后的员工信息
select * from tb_emp where entrydate > (select entrydate from tb_emp where name = '方东白');

-- 列子查询
-- A。查询 “教研部” 和 “咨询部” 的所有员工信息
select * from tb_emp where dept_id in (select id from tb_dept where name = '教研部' or name = '咨询部');

-- 行子查询
-- A. 查询和 “韦一笑” 的入职日期 及 职位都相同的 员工信息
select * from tb_emp where (entrydate, job) = (select entrydate, job from tb_emp where name = '韦一笑');

-- 表子查询
-- A. 查询入职日期是 “2006-01-01” 之后的员工信息,及其部门名称
select e.*, d.name
from (select * from tb_emp where entrydate > '2006-01-01') e, tb_dept d where e.dept_id = d.id;
事务
事务是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作妖魔同时成功,要么同时失败。
默认MYSQL的事务是自动提交的,也就是说,当执行一条DML语句,MYSQL会立即隐式地提交事务

-- 开启事务
start transaction;
-- 删除部门
delete
from tb_dept
where id = 3;
-- 删除部门下的员工
delete from tb_emp where dept_id == 3;
-- 提交事务
commit ;
-- 回滚事务
rollback ;

索引
简介
索引(index)是帮助数据库高效获取数据的数据结构

结构
MYSQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平常所说的索引,如果没有特别指明,都是指默认的B+Tree结构组织的索引。
B+Tree:多路平衡搜索树
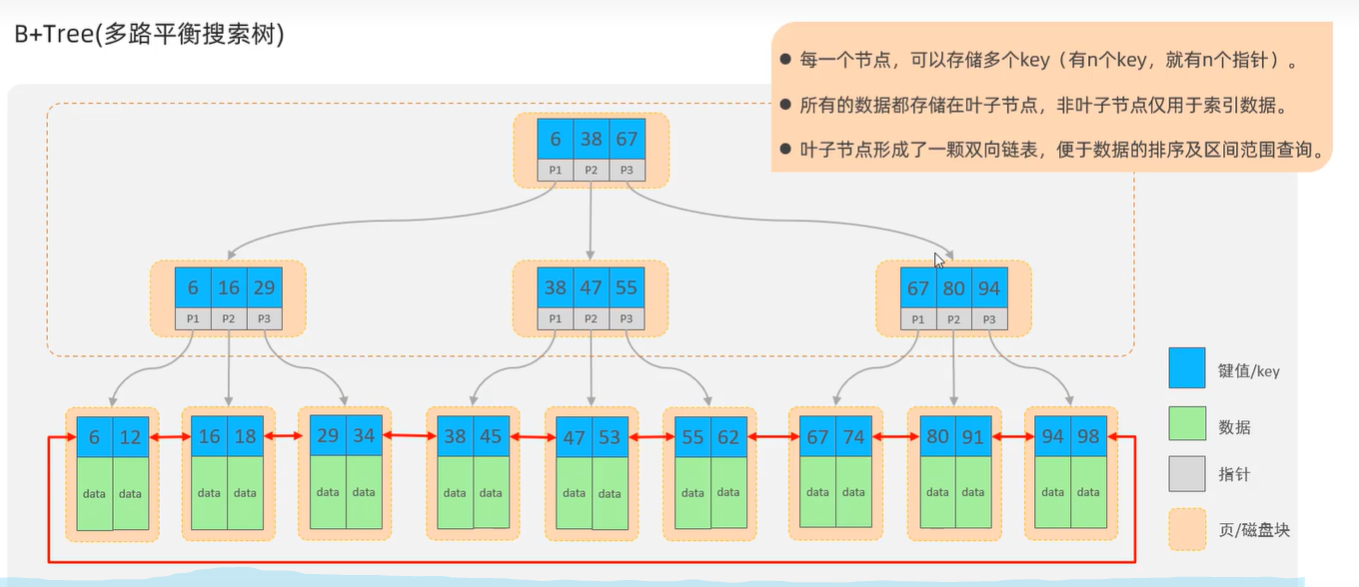
语法
创建索引
create [unique] index 索引名 on 表名(字段名,...);
查看索引
show index from 表名;
删除索引
drop index 索引名 on 表名;
-- 创建 : 为 tb_emp 表的name字段建立一个索引
create index idx_emp_name on tb_emp(name);
-- 查询 : 查询 tb_emp 表的索引信息
show index from tb_emp;
-- 删除 : 删除 tb_emp 表中name字段的索引
drop index idx_emp_name on tb_emp;
注意事项:
- 主键字段,在建表时,会自动创建主键索引。
- 添加唯一约束时,数据库实际上会添加唯一索引。
Summary
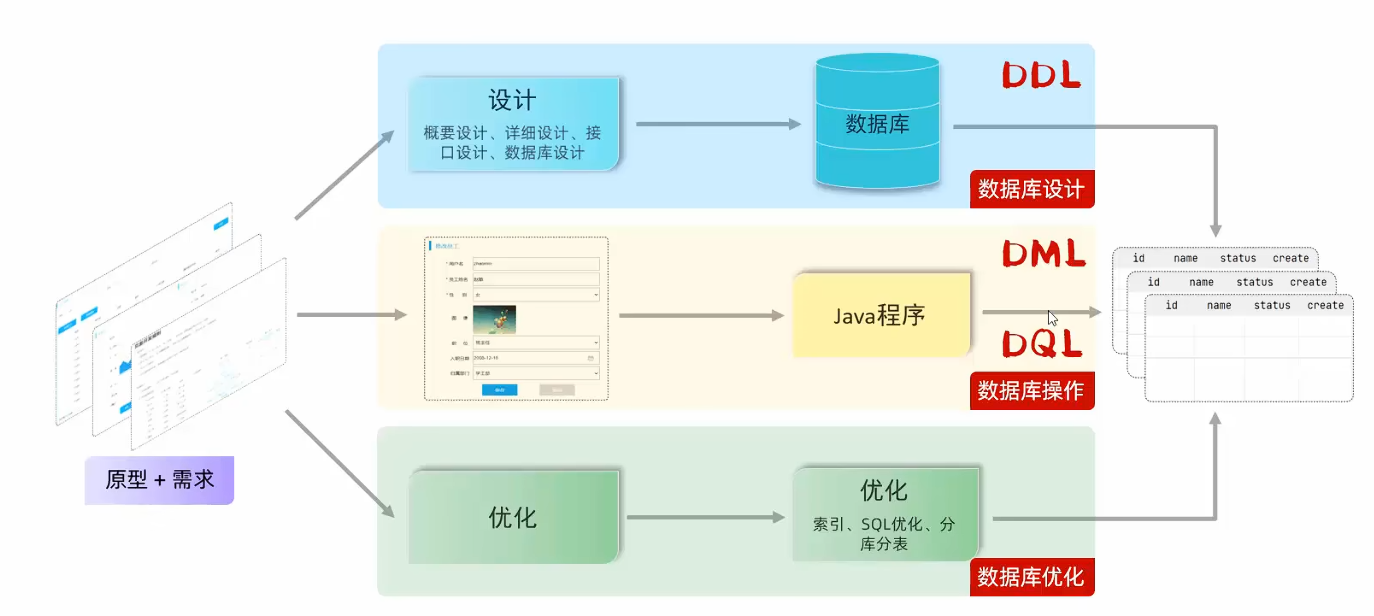

 浙公网安备 33010602011771号
浙公网安备 33010602011771号