DDD项目总结
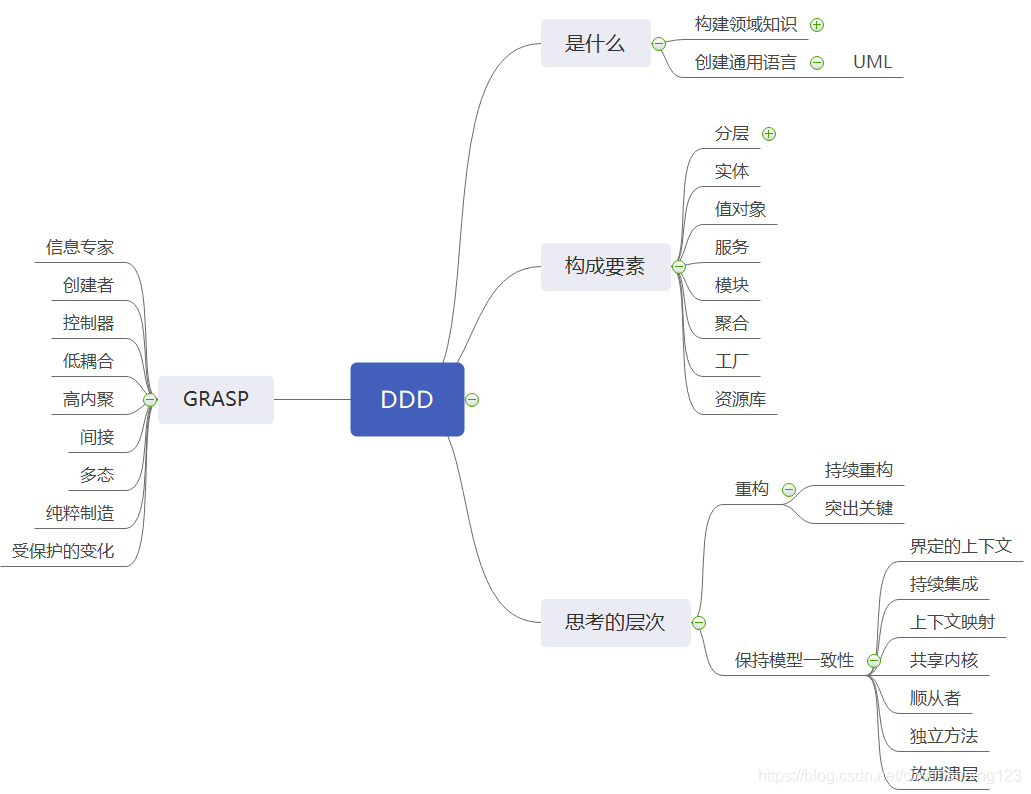
一、思维导图
DDD(Domain-Driven Design 领域驱动设计)
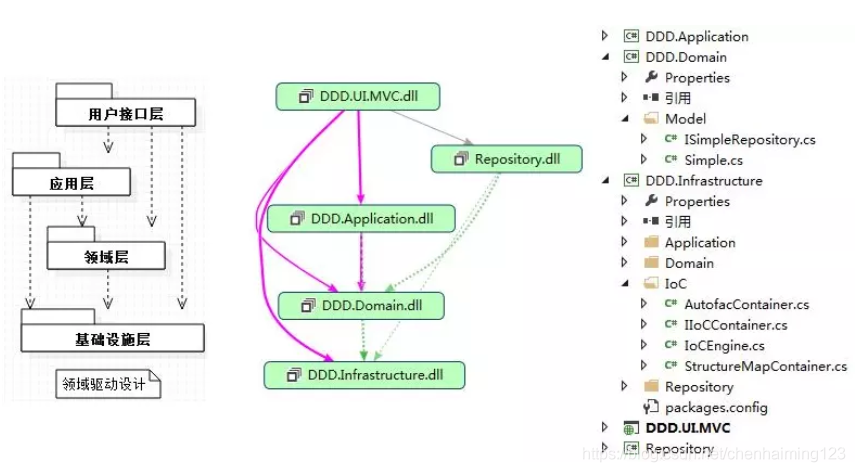
二、技术设计方案
三、基础要点
1.实体(entity):
根据eric evans的定义,”一个由它的标识定义的对象叫做实体”。通常实体具备唯一id,能够被持久化,具有业务逻辑,对应现实世界业务对象。
实体一般和主要的业务/领域对象有一个直接的关系。一个实体的基本概念是一个持续抽象的生命,可以变化不同的状态和情形,但总是有相同的标识。
需要注意的是:
一些开发人员将实体当成了orm意义上的实体,而不是业务所有和业务定义的领域对象。在一些实现中采用了transaction script风格的架构,使用贫血的领域模型。这种认识上的混乱,在领域驱动架构中,不愿意在领域对象中加入业务逻辑而导致贫血的领域模型,同时还可能使混乱的服务对象激增。
2.值对象(value object)
值对象的定义是:描述事物的对象;更准确的说,一个没有概念上标识符描述一个领域方面的对象。这些对象是用来表示临时的事物,或者可以认为值对象是实体的属性,这些属性没有特性标识但同时表达了领域中某类含义的概念。
通常值对象不具有唯一id,由对象的属性描述,可以用来传递参数或对实体进行补充描述。
作为实体属性的描述时,值对象也会被存储。在uml的类图上显现为一对多或一对一的关系。在orm映射关系上需要采用较复杂的一对多或一对一关系映射。
关于实体与值对象的一个例子:比如员工信息的属性,如住址,电话号码都可以改变;然而,同一个员工的实体的标识将保持不变。因此,一个实体的基本概念是一个持续抽象的生命,可以变化不同的状态和情形,但总是有相同的标识。
实体与值对象的区别
实体具有唯一标识,而值对象没有唯一标识,这是实体和值对象间的最大不同。
实体就是领域中需要唯一标识的领域概念。有两个实体,如果唯一标识不一样,那么即便实体的其他所有属性都一样,也认为是两个不同的实体;一个实体的基本概念是一个持续抽象的生命,可以变化不同的状态和情形,但总是有相同的标识。
不应该给实体定义太多的属性或行为,而应该寻找关联,发现其他一些实体或值对象,将属性或行为转移到其他关联的实体或值对象上。
如果两个对象的所有的属性的值都相同,我们会认为它们是同一个对象的话,那么我们就可以把这种对象设计为值对象。值对象在判断是否是同一个对象时是通过它们的所有属性是否相同,如果相同则认为是同一个值对象;而实体是否为同一个实体的区分,只是看实体的唯一标识是否相同,而不管实体的属性是否相同。
值对象另外一个明显的特征是不可变,即所有属性都是只读的。因为属性是只读的,所以可以被安全的共享;当共享值对象时,一般有复制和共享两种做法,具体采用哪种做法还要根据实际情况而定。
箴言:如果值对象时可共享的,它们应该是不可变的。(值对象应该保持尽量的简单)
值对象的设计应尽量简单,不要让它引用很多其他的对象,因为本质上讲值对象只是代表一个值。
3.聚合及聚合根(aggregate、aggregate root):
聚合是用来定义领域对象所有权和边界的领域模式。聚合的作用是帮助简化模型对象间的关系。聚合,它通过定义对象之间清晰的所属关系和边界来实现领域模型的内聚,并避免了错综复杂的难以维护的对象关系网的形成。聚合定义了一组具有内聚关系的相关对象的集合,我们把聚合看作是一个修改数据的单元。
划分aggregation是对领域模型的进一步深化,aggregation能阐释领域模型内部对象之间的深层关联.对aggregation的划分会直接映射到程序结构上.比如:ddd推荐按aggregation设计model的子包.每个aggregation配备一个repository.aggregation内部的非root对象是通过导航获得的.
一个聚合是一组相关的被视为整体的对象。每个聚合都有一个根对象(聚合根实体),从外部访问只能通过这个对象。根实体对象有组成聚合所有对象的引用,但是外部对象只能引用根对象实体。
只有聚合根才能使用仓储库直接查询,其它的只能通过相关的聚合访问。如果根实体被删除,聚合内部的其它对象也将被删除。
通常,我们把聚合组织到一个文件夹或一个包中。每一个聚集对应一个包,并且每个聚集成员包括实体、值对象,domain事件,仓储接口和其它工厂对象。
聚合有以下一些特点:
1. 每个聚合有一个根和一个边界,边界定义了一个聚合内部有哪些实体或值对象,根是聚合内的某个实体;
2. 聚合内部的对象之间可以相互引用,但是聚合外部如果要访问聚合内部的对象时,必须通过聚合根开始导航,绝对不能绕过聚合根直接访问聚合内的对象,也就是说聚合根是外部可以保持对它的引用的唯一元素;
3. 聚合内除根以外的其他实体的唯一标识都是本地标识,也就是只要在聚合内部保持唯一即可,因为它们总是从属于这个聚合的;
4. 聚合根负责与外部其他对象打交道并维护自己内部的业务规则;
5. 基于聚合的以上概念,我们可以推论出从数据库查询时的单元也是以聚合为一个单元,也就是说我们不能直接查询聚合内部的某个非根的对象;
6. 聚合内部的对象可以保持对其他聚合根的引用;
7. 删除一个聚合根时必须同时删除该聚合内的所有相关对象,因为他们都同属于一个聚合,是一个完整的概念。
如何识别聚合?
聚合中的对象关系是内聚的,即这些对象之间必须保持一个固定规则,固定规则是指在数据变化时必须保持不变的一致性规则。
当我们在修改一个聚合时,我们必须在事务级别确保整个聚合内的所有对象满足这个固定规则。
作为一条建议,聚合尽量不要太大,否则即便能够做到在事务级别保持聚合的业务规则完整性,也可能会带来一定的性能问题。
有分析报告显示,通常在大部分领域模型中,有70%的聚合通常只有一个实体,即聚合根,该实体内部没有包含其他实体,只包含一些值对象;另外30%的聚合中,基本上也只包含两到三个实体。这意味着大部分的聚合都只是一个实体,该实体同时也是聚合根。
如何识别聚合根?
如果一个聚合只有一个实体,那么这个实体就是聚合根;如果有多个实体,可以思考聚合内哪个对象有独立存在的意义并且可以和外部直接进行交互。
并不是所有的实体都是聚集根,但只有实体才能成为聚集根。
4.工厂(factories):
工厂用来封装创建一个复杂对象尤其是聚合时所需的知识,作用是将创建对象的细节隐藏起来。客户传递给工厂一些简单的参数,然后工厂可以在内部创建出一个复杂的领域对象然后返回给客户。当创建 实体和值对象复杂时建议使用工厂模式。
不意味着我们一定要使用工厂模式。如果创建对象很简单,使用构造器或者控制反转/依赖注入容器足够创建对象的依赖。此时,我们就不需要通用工厂模式来创建实体或值对象。
良好工厂的要求:
每个创建方法都是原子的。一个工厂应该只能生产透明状态的对象。对于实体,意味着创建整个聚合时满足所有的不变量。
一个单独的工厂通常生产整个聚合,传出一个根实体的引用,确保聚合的不变量都有。如果对象的内部聚合需要工厂,通常工厂方法的逻辑放在在聚合根上。这样对外部隐藏了聚合内聚的实现,同时赋予了根确保聚合完整的职责。如果聚合根不是子实体工厂的合适的家,那么继续创建一个单独的工厂。
5.仓储(repositories):
仓储是用来管理实体的集合。
仓储里面存放的对象一定是聚合,原因是domain是以聚合的概念来划分边界的;聚合作为一个整体概念,要么一起被取出来,要么一起被删除。外部访问不会单独对某个聚合内的子对象进行单独操作。因此,我们只对聚合设计仓储。
仓储还有一个重要的特征就是分为仓储定义部分和仓储实现部分,我们在领域模型中定义仓储的接口,而在基础设施层实现具体的仓储。也符合按照接口分离模式在领域层定义仓储库接口的原则。
注意:repositories本身是一种领域组件,但repositories的实现却不是领域层中的。
respositories和dao:
dao和repository在领域驱动设计中都很重要。dao是面向数据访问的,是关系型数据库和应用之间的契约。
repository:位于领域层,面向aggregation root。repository是一个独立的抽象,使用领域的通用语言,它与dao进行交互,并使用领域理解的语言提供对领域模型的数据访问服务的“业务接口”。
dao方法是细粒度的,更接近数据库,而repository方法的粒度粗一些,而且更接近领域。领域对象应该只依赖于repository接口。客户端应该始终调用领域对象,领域对象再调用dao将数据持久化到数据 存储中。
处理领域对象之间的依赖关系(比如实体及其repository之间的依赖关系)是开发人员经常遇到的典型问题。解决这个问题通 常的设计方案是让服务类或外观类直接调用repository,在调用repository的时候返回实体对象给客户端。
6.服务(services):
服务这个词在服务模式中是这么定义的:服务提供的操作是它提供给使用它的客户端,并突出领域对象的关系。
所有的service只负责协调并委派业务逻辑给领域对象进行处理,其本身并真正实现业务逻辑,绝大部分的业务逻辑都由领域对象承载和实现了。
service可与多种组件进行交互,这些组件包括:其他的service、领域对象和repository 或 dao。
通常,应用中一般包括:domain模型服务和应用层服务:
* domain services encapsulate domain concepts that just are not naturally modeled as things.
* application services constitute the application, or service, layer.
当一个领域操作被视为一个重要的领域概念,一般就应该作为领域服务。 服务应该是无状态的。
设计实现领域服务来协调业务逻辑,只在领域服务中实现领域逻辑的调用。
领域服务逻辑须以非常干净简洁的代码实现。因此,我们必须实现对领域低层组件的调用。通常应用的调用,例如仓储库的调用,创建事务等,不应该在这里实现。这些操作应该在应用层实现。
通常服务对象名称中都应包含一个动词。 service接口的传入传出参数也都应该是dto,可能包含的工作有领域对象和dto的互转换以及事务。
服务的3个特征:
a. 服务执行的操作涉及一个领域概念,这个领域概念通常不属于一个实体或者值对象
b. 被执行的操作涉及到领域中其它的对象
c. 操作时无状态的
推荐:最好显式声明服务,因为它创建了领域中一个清晰的特性,封装了一个概念领域层服务和基础设施层服务:均建立在领域实体和值对象的上层,以便直接为这些相关的对象提供所需的服务;
领域服务与domain对象的区别
一般的领域对象都是有状态和行为的,而领域服务没有状态只有行为。需要强调的是领域服务是无状态的,它存在的意义就是协调领域对象共同完成某个操作,所有的状态还是都保存在相应的领域对象中。
通常,对开发人员来说创建不应该存在的服务相当容易;要么在服务中包含了本应存在于领域对象中的领域逻辑,要么扮演了缺失的领域对象角色,而这些领域对象并没有作为模型的一部分去创建。
7.domain事件
domain event模式最初由udi dahan提出,发表在自己的博客上:http://www.udidahan.com/2009/06/14/domain-events-salvation/
企业级应用程序事件大致可以分为三类:系统事件、应用事件和领域事件。领域事件的触发点在领域模型(domain model)中。它的作用是将领域对象从对repository或service的依赖中解脱出来,避免让领域对象对这些设施产生直接依赖。它的做法就是当领域对象的业务方法需要依赖到这些对象时就发出一个事件,这个事件会被相应的对象监听到并做出处理。
通过使用领域事件,我们可以实现领域模型对象状态的异步更新、外部系统接口的委托调用,以及通过事件派发机制实现系统集成。另外,领域事件本身具有自描述性。它不仅能够表述系统发生了什么事情,而且还能够描述发生事件的动机。
domain事件也用表进行存储。
8.DTO
dto- datatransfer object(数据传输对象):dto在设计之初的主要考量是以粗粒度的数据结构减少网络通信并简化调用接口。user interface:
该层包含与其他系统/客户进行交互的接口与通信设施,在多数应用里,该层可能提供包括web services、rmi或rest等在内的一种或多种通信接口。该层主要由facade、dto和assembler三类组件构成,三类组件均是典型的j2ee模式。
dto的作用最初主要是以粗粒度的数据结构减少网络通信并简化调用接口。在领域驱动设计中,采用dto模型,可以起到隐藏领域细节,帮助实现独立封闭的领域模型的作用。
dto与领域对象之间的相互转换工作多由assembler承担,也有一些系统使用反射机制自动实现dto与领域对象之间的相互转换,如apache common beanutils。
facade的用意在于为远程客户端提供粗粒度的调用接口。facade本身不处理任何的业务逻辑,它的主要工作就是将一个用户请求委派给一个或多个service进行处理,同时借助assembler将service传入或传出的领域对象转化为dto进行传输。
application:
application层中主要组件就是service。这里需要注意的是,service的组织粒度和接口设计依据与传统transaction script风格的service是一致的,但是两者的实现却有质的区别。
transaction script(事务脚本)的核心是过程,通过过程的调用来组织业务逻辑,业务逻辑在服务(service)层进行处理。大部分业务应用都可以被看成一系列事务。
transaction script的特点是简单容易理解,面向过程设计。 如果应用相对简单,在应用的生命周期里不会有基础设施技术的改变,尤其是业务逻辑很少会变动,采用transaction script风格简单自然,性能良好,容易理解。
transaction script的缺点在于,对于复杂的业务逻辑难以保持良好的设计,事务之间的冗余代码不断增多。应用架构容易出现“胖服务层”和“贫血的领域模型”。同时,service层积聚越来越多的业务逻辑,导致可维护性和扩展性变差
领域模型属于面向对象设计,领域模型具备自己的属性行为和状态,领域对象元素之间通过聚合配合解决实际业务应用。可复用,可维护,易扩展,可以采用合适的设计模型进行详细设计。缺点是相对复杂,要求设计人员有良好的抽象能力。
transactionscript风格业务逻辑主要在service中实现,而在领域驱动设计的架构里,service只负责协调并委派业务逻辑给领域对象进行处理。因此,我们可以考察这一点来识别系统是transaction script架构还是domain model架构。在实践中,设计良好的领域设计架构在开发过程中也容易向transaction script架构演变。
domain:
domain层是整个系统的核心层,该层维护一个使用面向对象技术实现的领域模型,几乎全部的业务逻辑会在该层实现。domain层包含entity(实体)、valueobject(值对象)、domain event(领域事件)和repository(仓储)等多种重要的领域组件。
infrastructure:
infrastructure(基础设施层)为interfaces、application和domain三层提供支撑。所有与具体平台、框架相关的实现会在infrastructure中提供,避免三层特别是domain层掺杂进这些实现,从而“污染”领域模型。infrastructure中最常见的一类设施是对象持久化的具体实现。
设计领域模型的一般步骤:
1. 根据需求建立一个初步的领域模型,识别出一些明显的领域概念以及它们的关联,关联可以暂时没有方向但需要有(1:1,1:n,m:n)这些关系;可以用文字精确的没有歧义的描述出每个领域概念的涵义以及包含的主要信息;
2. 分析主要的软件应用程序功能,识别出主要的应用层的类;这样有助于及早发现哪些是应用层的职责,哪些是领域层的职责;
3. 进一步分析领域模型,识别出哪些是实体,哪些是值对象,哪些是领域服务;
4. 分析关联,通过对业务的更深入分析以及各种软件设计原则及性能方面的权衡,明确关联的方向或者去掉一些不需要的关联;
5. 找出聚合边界及聚合根,这是一件很有难度的事情;因为你在分析的过程中往往会碰到很多模棱两可的难以清晰判断的选择问题,所以,需要我们平时一些分析经验的积累才能找出正确的聚合根;
6. 为聚合根配备仓储,一般情况下是为一个聚合分配一个仓储,此时只要设计好仓储的接口即可;
7. 走查场景,确定我们设计的领域模型能够有效地解决业务需求;
8. 考虑如何创建领域实体或值对象,是通过工厂还是直接通过构造函数;
9. 停下来重构模型。寻找模型中觉得有些疑问或者是蹩脚的地方,比如思考一些对象应该通过关联导航得到还是应该从仓储获取?聚合设计的是否正确?考虑模型的性能怎样,等等;


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构