Java Stream 源码分析
Java Stream 源码分析
前言
Java 8 的 Stream 使得代码更加简洁易懂,本篇文章深入分析 Java Stream 的工作原理,并探讨 Steam 的性能问题。
Java 8 集合中的 Stream 相当于高级版的 Iterator,它可以通过 Lambda 表达式对集合进行各种非常便利、高效的聚合操作(Aggregate Operation),或者大批量数据操作 (Bulk Data Operation)。
Stream的聚合操作与数据库SQL的聚合操作sorted、filter、map等类似。我们在应用层就可以高效地实现类似数据库SQL的聚合操作了,而在数据操作方面,Stream不仅可以通过串行的方式实现数据操作,还可以通过并行的方式处理大批量数据,提高数据的处理效率。
操作分类
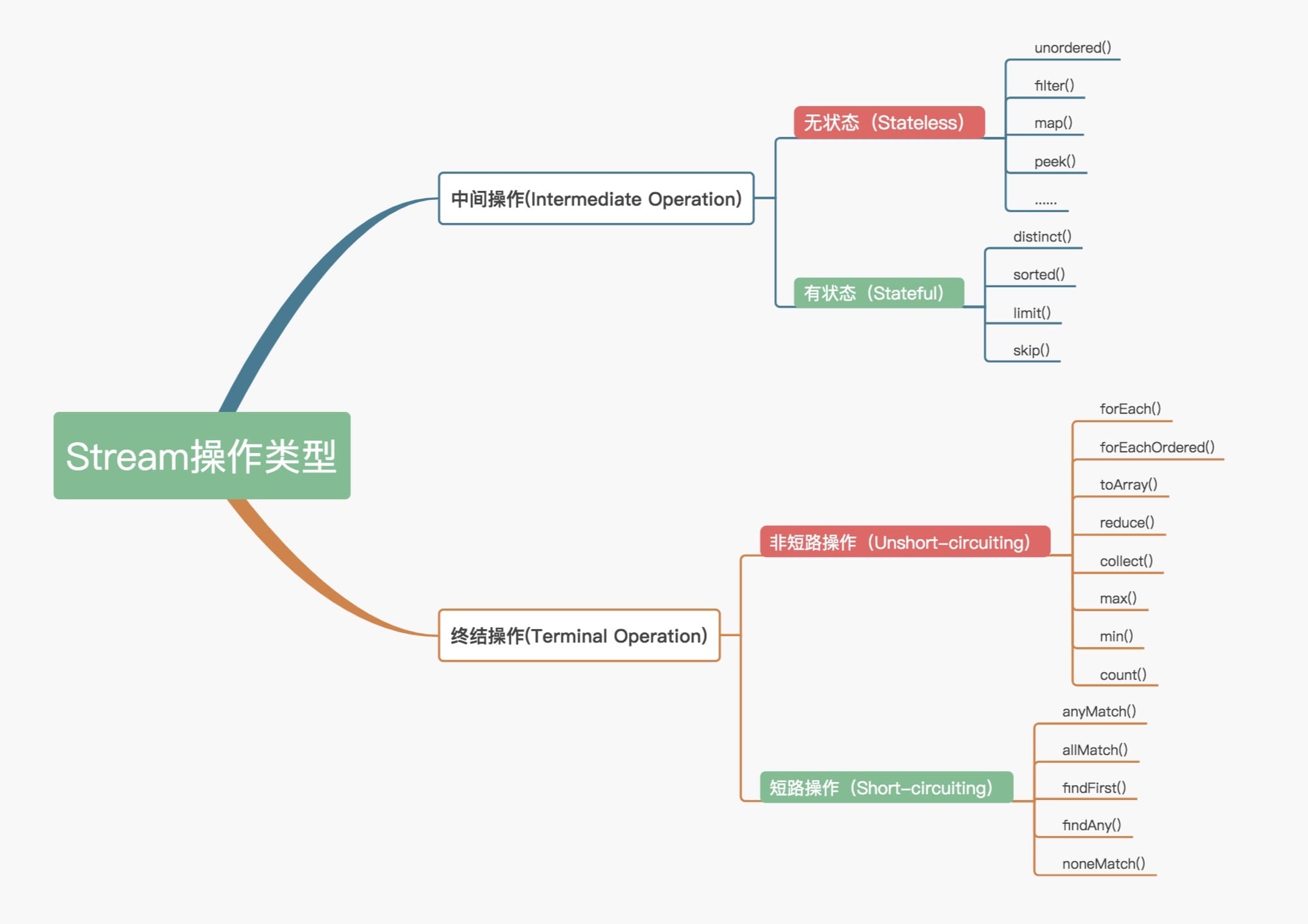
官方将 Stream 中的操作分为两大类:
中间操作(Intermediate operations),只对操作进行了记录,即只会返回一个流,不会进行计算操作。终结操作(Terminal operations),实现了计算操作。
中间操作又可以分为:
无状态(Stateless)操作,元素的处理不受之前元素的影响。有状态(Stateful)操作,指该操作只有拿到所有元素之后才能继续下去。
终结操作又可以分为:
短路(Short-circuiting)操作,指遇到某些符合条件的元素就可以得到最终结果非短路(Unshort-circuiting)操作,指必须处理完所有元素才能得到最终结果。
操作分类详情如下图所示:
源码结构
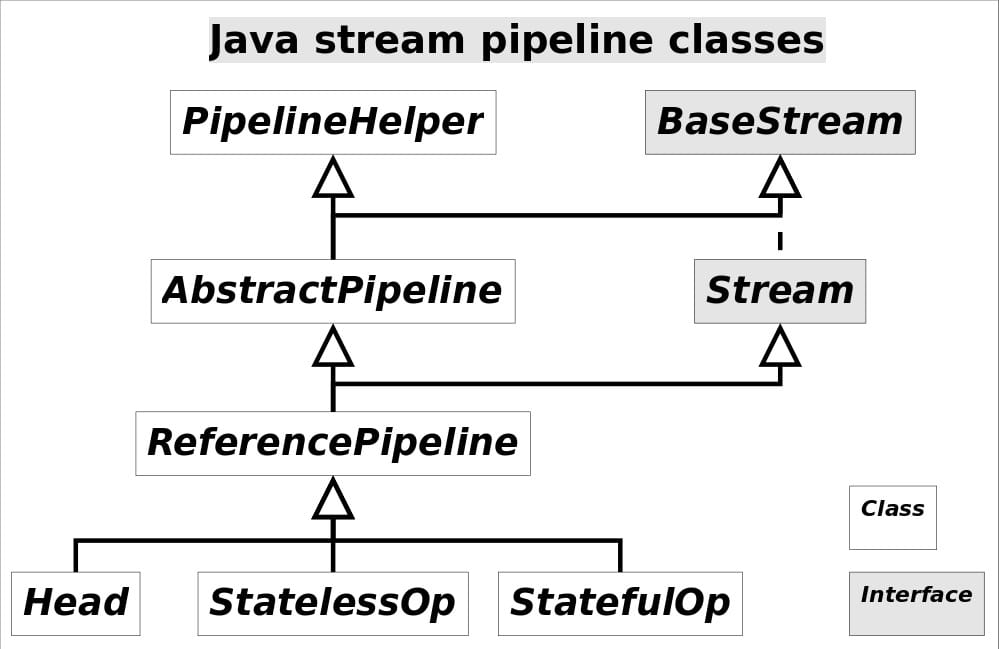
Stream 相关类和接口的继承关系如下图所示:
BaseStream
最顶端的接口类,定义了流的基本接口方法,最主要的方法为 spliterator、isParallel。

Stream
最顶端的接口类。定义了流的常用方法,例如 map、filter、sorted、limit、skip、collect 等。

ReferencePipeline
ReferencePipeline 是一个结构类,定义内部类组装了各种操作流,定义了Head、StatelessOp、StatefulOp三个内部类,实现了 BaseStream 与 Stream 的接口方法。

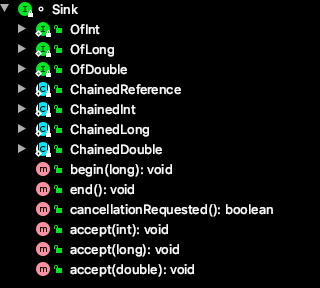
Sink
Sink 接口定义了 Stream 之间的操作行为,包含 begin()、end()、cancellationRequested()、accpt()四个方法。ReferencePipeline最终会将整个 Stream 流操作组装成一个调用链,而这条调用链上的各个 Stream 操作的上下关系就是通过 Sink 接口协议来定义实现的。
操作叠加
Stream 的基础用法就不再叙述了,这里从一段代码开始,分析 Stream 的工作原理。
@Test
public void testStream() {
List<String> names = Arrays.asList("kotlin", "java", "go");
int maxLength = names.stream().filter(name -> name.length() <= 4).map(String::length)
.max(Comparator.naturalOrder()).orElse(-1);
System.out.println(maxLength);
}
当使用 Stream 时,主要有 3 部分组成,下面一一讲解。
加载数据源
调用 names.stream() 方法,会初次加载 ReferencePipeline 的 Head 对象,此时为加载数据源操作。
java.util.Collection#stream
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
StreamSupport 类中的 stream 方法,初始化了一个 ReferencePipeline的 Head 内部类对象。
java.util.stream.StreamSupport#stream(java.util.Spliterator, boolean)
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
中间操作
接着为 filter(name -> name.length() <= 4).mapToInt(String::length),是中间操作,分为无状态中间操作 StatelessOp 对象和有状态操作 StatefulOp 对象,此时的 Stage 并没有执行,而是通过AbstractPipeline 生成了一个中间操作 Stage 链表。
java.util.stream.ReferencePipeline#filter
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
java.util.stream.ReferencePipeline#map
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
可以看到 filter 和 map 方法都返回了一个新的 StatelessOp 对象。new StatelessOp 将会调用父类 AbstractPipeline 的构造函数,这个构造函数将前后的 Stage 联系起来,生成一个 Stage 链表:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
终结操作
最后为 max(Comparator.naturalOrder()),是终结操作,会生成一个最终的 Stage,通过这个 Stage 触发之前的中间操作,从最后一个Stage开始,递归产生一个Sink链。
java.util.stream.ReferencePipeline#max
@Override
public final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) {
return reduce(BinaryOperator.maxBy(comparator));
}
最终调用到 java.util.stream.AbstractPipeline#wrapSink,这个方法会调用 opWrapSink 生成一个 Sink 链表,对应到本文的例子,就是 filter 和 map 操作。
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
在上面 opWrapSink 上断点调试,发现最终会调用到本例中的 filter 和 map 操作。
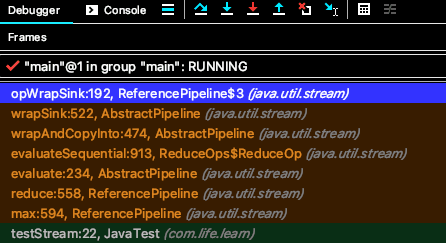
wrapAndCopyInto 生成 Sink 链表后,会通过 copyInfo 方法执行 Sink 链表的具体操作。
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
上面的核心代码是:
spliterator.forEachRemaining(wrappedSink);
java.util.Spliterators.ArraySpliterator#forEachRemaining
@Override
public void forEachRemaining(Consumer<? super T> action) {
Object[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
do { action.accept((T)a[i]); } while (++i < hi);
}
}
断点调试,可以发现首先进入了 filter 的 Sink,其中 accept 方法的入参是 list 中的第一个元素“kotlin”(代码中的 3 个元素是:"kotlin", "java", "go")。filter 的传入是一个 Lambda 表达式:
filter(name -> name.length() <= 4)
显然这个第一个元素“kotlin”的 predicate 是不会进入的。
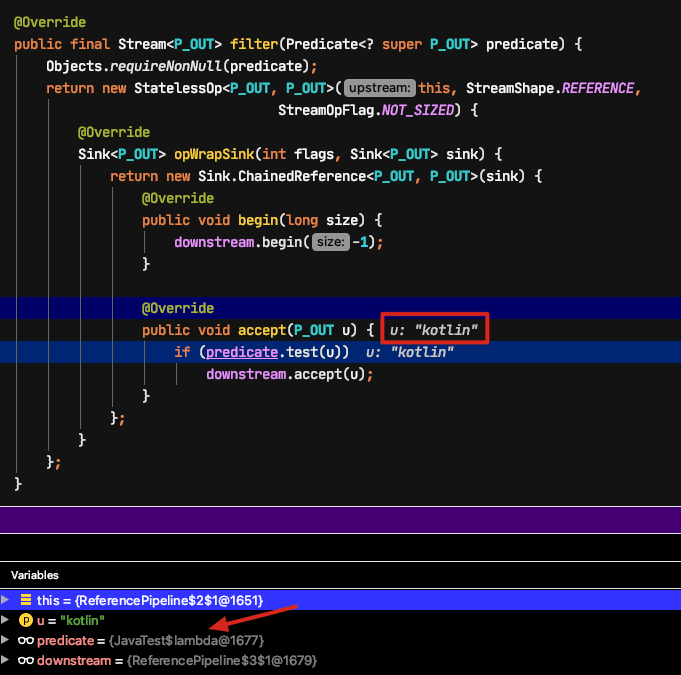
对于第二个元素“java”,predicate.test 会返回 true(字符串“java”的长度<=4),则会进入 map 的 accept 方法。
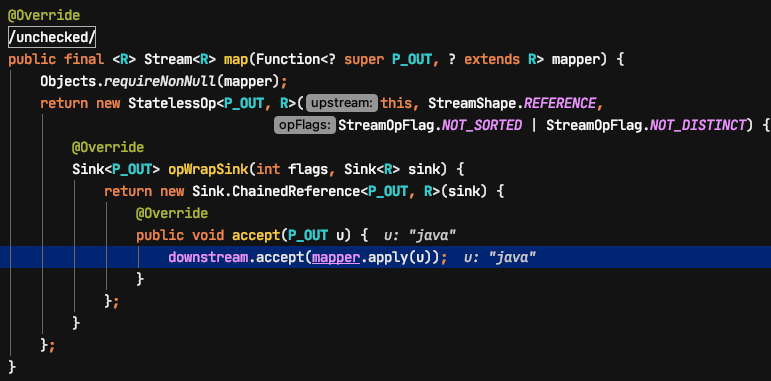
本次调用 accept 方法时,empty 为 false,会将 map 后的结果(int 类型的 4)赋值给 t。
public static <T> TerminalOp<T, Optional<T>>
makeRef(BinaryOperator<T> operator) {
Objects.requireNonNull(operator);
class ReducingSink
implements AccumulatingSink<T, Optional<T>, ReducingSink> {
private boolean empty;
private T state;
public void begin(long size) {
empty = true;
state = null;
}
@Override
public void accept(T t) {
if (empty) {
empty = false;
state = t;
} else {
state = operator.apply(state, t);
}
}
……
}
}
对于第三个元素“go”,也会进入 accept 方法,此时 empty 为 true, map 后的结果(int 类型的 2)会与上次的结果 4 通过自定义的比较器相比较,存入符合结果的值。
public static <T> BinaryOperator<T> maxBy(Comparator<? super T> comparator) {
Objects.requireNonNull(comparator);
return (a, b) -> comparator.compare(a, b) >= 0 ? a : b;
}
本文代码中的 max 传入的比较器为:
max(Comparator.naturalOrder())
至此会返回 int 类型的 4。
并行处理
上面的例子是串行处理的,如果要改成并行也很简单,只需要在 stream() 方法后加上 parallel() 就可以了,并行代码可以写成:
@Test
public void testStream() {
List<String> names = Arrays.asList("kotlin", "java", "go");
int maxLength = names.stream().parallel().filter(name -> name.length() <= 4)
.map(String::length).max(Comparator.naturalOrder()).orElse(-1);
System.out.println(maxLength);
}
Stream 的并行处理在执行终结操作之前,跟串行处理的实现是一样的。而在调用终结方法之后,实现的方式就有点不太一样,会调用 TerminalOp 的 evaluateParallel 方法进行并行处理。
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
核心是使用了 ForkJoin 框架,对 Stream 处理进行分片,最终会调用下面的代码,这里就不展开分析了。
java.util.stream.AbstractTask#compute
@Override
public void compute() {
Spliterator<P_IN> rs = spliterator, ls; // right, left spliterators
long sizeEstimate = rs.estimateSize();
long sizeThreshold = getTargetSize(sizeEstimate);
boolean forkRight = false;
@SuppressWarnings("unchecked") K task = (K) this;
while (sizeEstimate > sizeThreshold && (ls = rs.trySplit()) != null) {
K leftChild, rightChild, taskToFork;
task.leftChild = leftChild = task.makeChild(ls);
task.rightChild = rightChild = task.makeChild(rs);
task.setPendingCount(1);
if (forkRight) {
forkRight = false;
rs = ls;
task = leftChild;
taskToFork = rightChild;
}
else {
forkRight = true;
task = rightChild;
taskToFork = leftChild;
}
taskToFork.fork();
sizeEstimate = rs.estimateSize();
}
task.setLocalResult(task.doLeaf());
task.tryComplete();
}
并行错误的使用方法
@Test
public void testParallelWrong() {
List<Integer> parallelList = new ArrayList<>();
IntStream.range(0, 1000).boxed().parallel().filter(i -> i % 2 == 1)
.forEach(parallelList::add);
System.out.println(parallelList.size());
}
上面的输出结果会经常小于500,这是因为 parallelList 的类型是 ArrayList,并不是线程安全的,在执行 add 操作时,可能正好赶上扩容或者线程被占用,会覆盖其他线程的赋好的值。
并行正确的使用方法
@Test
public void testParallelRight() {
List<Integer> parallelList = IntStream.range(0, 1000).boxed().parallel()
.filter(i -> i % 2 == 1).collect(Collectors.toList());
System.out.println(parallelList.size());
}
性能
下面的文章参考自:JavaLambdaInternals/8-Stream Performance.md,侵删。
为保证测试结果真实可信,我们将JVM运行在-server模式下,测试数据在GB量级,测试机器采用常见的商用服务器,配置如下:
| OS | CentOS 6.7 x86_64 |
| CPU | Intel Xeon X5675, 12M Cache 3.06 GHz, 6 Cores 12 Threads |
| 内存 | 96GB |
| JDK | java version 1.8.0_91, Java HotSpot(TM) 64-Bit Server VM |
测试方法和测试数据
性能测试并不是容易的事,Java性能测试更费劲,因为虚拟机对性能的影响很大,JVM对性能的影响有两方面:
- GC的影响。GC的行为是Java中很不好控制的一块,为增加确定性,我们手动指定使用CMS收集器,并使用10GB固定大小的堆内存。具体到JVM参数就是
-XX:+UseConcMarkSweepGC -Xms10G -Xmx10G - JIT(Just-In-Time)即时编译技术。即时编译技术会将热点代码在JVM运行的过程中编译成本地代码,测试时我们会先对程序预热,触发对测试函数的即时编译。相关的JVM参数是
-XX:CompileThreshold=10000。
Stream并行执行时用到ForkJoinPool.commonPool()得到的线程池,为控制并行度我们使用Linux的taskset命令指定JVM可用的核数。
测试数据由程序随机生成。为防止一次测试带来的抖动,测试4次求出平均时间作为运行时间。
实验一 基本类型迭代
测试内容:找出整型数组中的最小值。对比for循环外部迭代和Stream API内部迭代性能。
测试程序IntTest,测试结果如下图:

图中展示的是for循环外部迭代耗时为基准的时间比值。分析如下:
- 对于基本类型Stream串行迭代的性能开销明显高于外部迭代开销(两倍);
- Stream并行迭代的性能比串行迭代和外部迭代都好。
并行迭代性能跟可利用的核数有关,上图中的并行迭代使用了全部12个核,为考察使用核数对性能的影响,我们专门测试了不同核数下的Stream并行迭代效果:
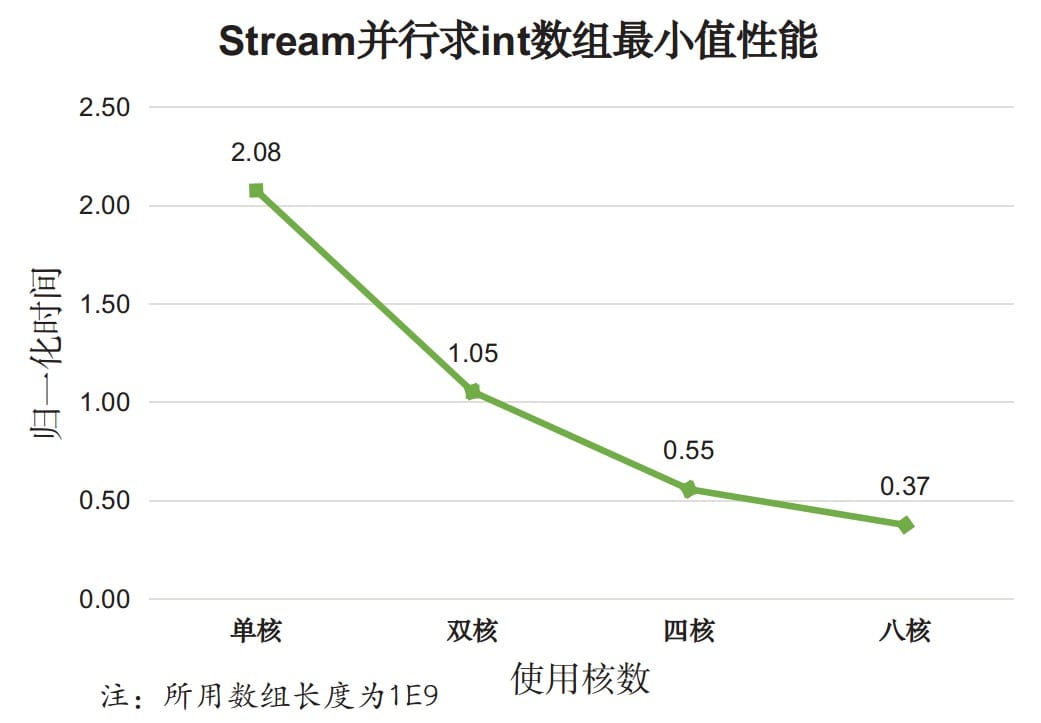
分析,对于基本类型:
- 使用Stream并行API在单核情况下性能很差,比Stream串行API的性能还差;
- 随着使用核数的增加,Stream并行效果逐渐变好,比使用for循环外部迭代的性能还好。
以上两个测试说明,对于基本类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好。
实验二 对象迭代
再来看对象的迭代效果。
测试内容:找出字符串列表中最小的元素(自然顺序),对比for循环外部迭代和Stream API内部迭代性能。
测试程序StringTest,测试结果如下图:
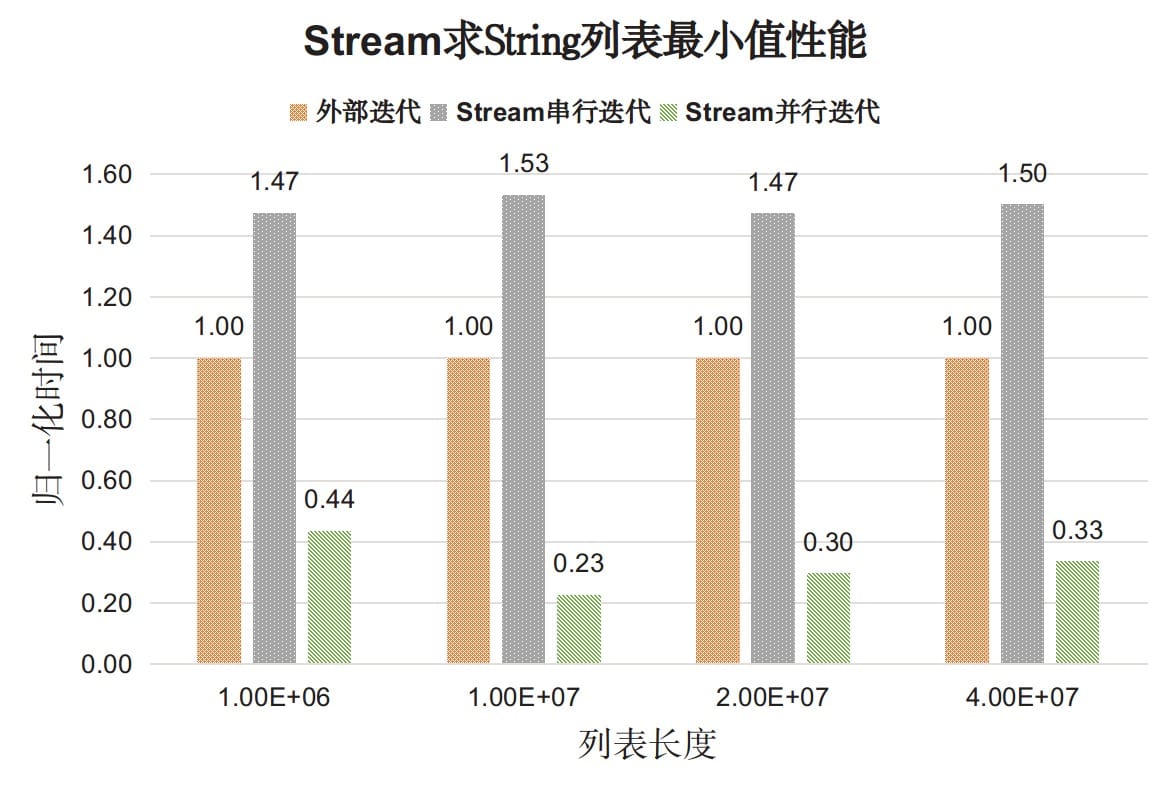
结果分析如下:
- 对于对象类型Stream串行迭代的性能开销仍然高于外部迭代开销(1.5倍),但差距没有基本类型那么大。
- Stream并行迭代的性能比串行迭代和外部迭代都好。
再来单独考察Stream并行迭代效果:

分析,对于对象类型:
- 使用Stream并行API在单核情况下性能比for循环外部迭代差;
- 随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。
以上两个测试说明,对于对象类型的简单迭代,Stream串行迭代性能更差,但多核情况下Stream迭代时性能较好。
实验三 复杂对象归约
从实验一、二的结果来看,Stream串行执行的效果都比外部迭代差(很多),是不是说明Stream真的不行了?先别下结论,我们再来考察一下更复杂的操作。
测试内容:给定订单列表,统计每个用户的总交易额。对比使用外部迭代手动实现和Stream API之间的性能。
我们将订单简化为<userName, price, timeStamp>构成的元组,并用Order对象来表示。测试程序ReductionTest,测试结果如下图:

分析,对于复杂的归约操作:
- Stream API的性能普遍好于外部手动迭代,并行Stream效果更佳;
再来考察并行度对并行效果的影响,测试结果如下:
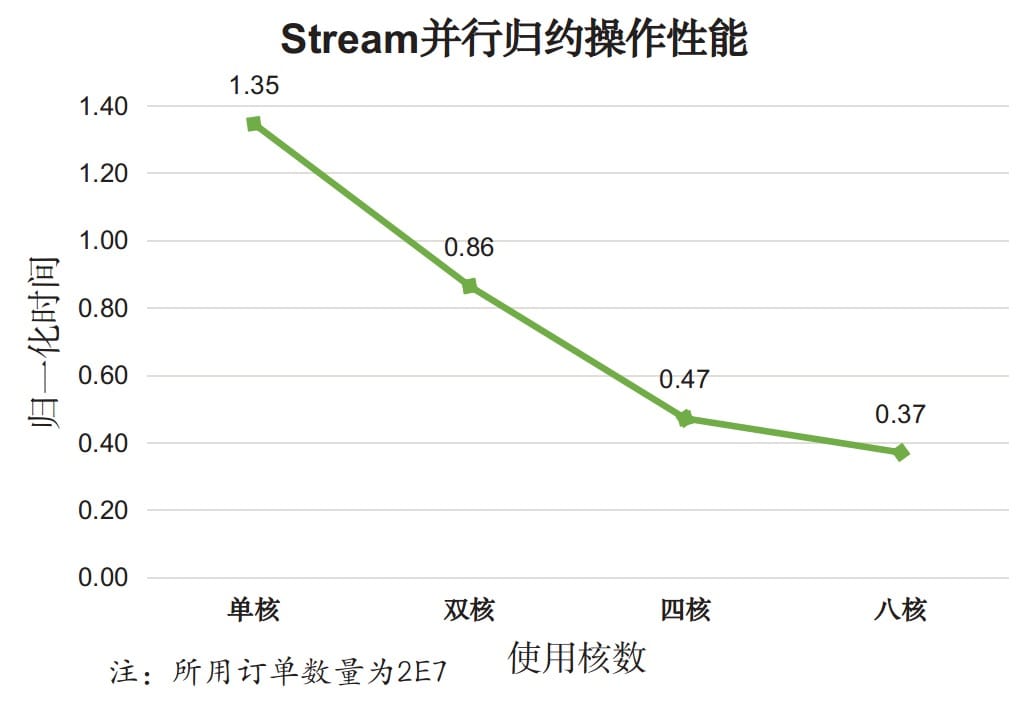
分析,对于复杂的归约操作:
- 使用Stream并行归约在单核情况下性能比串行归约以及手动归约都要差,简单说就是最差的;
- 随着使用核数的增加,Stream并行效果逐渐变好,多核带来的效果明显。
以上两个实验说明,对于复杂的归约操作,Stream串行归约效果好于手动归约,在多核情况下,并行归约效果更佳。我们有理由相信,对于其他复杂的操作,Stream API也能表现出相似的性能表现。
结论
上述三个实验的结果可以总结如下:
- 对于简单操作,比如最简单的遍历,Stream串行API性能明显差于显示迭代,但并行的Stream API能够发挥多核特性。
- 对于复杂操作,Stream串行API性能可以和手动实现的效果匹敌,在并行执行时Stream API效果远超手动实现。
所以,如果出于性能考虑,1. 对于简单操作推荐使用外部迭代手动实现,2. 对于复杂操作,推荐使用Stream API, 3. 在多核情况下,推荐使用并行Stream API来发挥多核优势,4.单核情况下不建议使用并行Stream API。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号