一张优惠券引发的血案(redis并发安全问题)






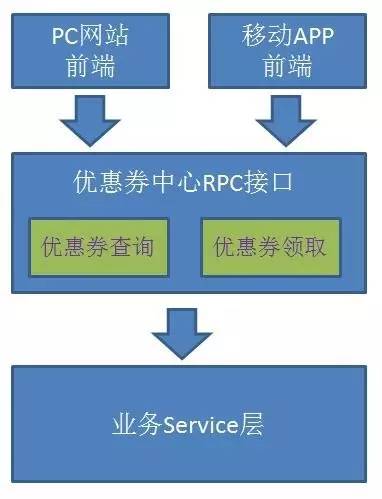
整个优惠券中心分为前端和后端,小灰所负责的是后端RPC接口的开发。接口中包含“查券”和“领券”两个方法,项目大体结构如下图:
两周后——

小灰:看,这是优惠券查询功能的效果!
小灰:看,这是优惠券领取功能的效果!

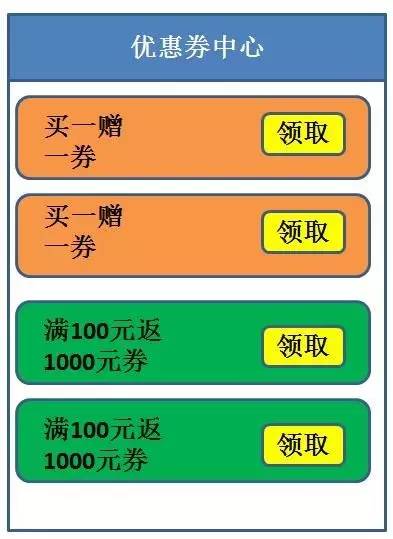
三天后——





小灰原本的优惠券查询接口是这样实现的:

优惠券列表在Redis中以List的形式存储,查询时的逻辑很简单:
1.查询缓存,如果缓存存在,返回结果
2.缓存不存在,查询数据库
3.把查询数据库的结果循环放入缓存
然而,当某个时间点缓存不存在,请求量又很大的时候,会出现缓存并发的问题。也就是多个线程会重复去查询DB,又重复去更新缓存。(注意,这并不是缓存击穿,很多人在这两个概念上混淆。)
这其中重复查询DB是次要问题,而重复更新缓存则是主要问题。假如有两个线程同时进入上述的第三个阶段,各自进行rpush操作,那么最终会在优惠券列表的缓存中插入两组同样的数据。
怎么解决呢?用Java的锁机制?显然不行,因为线上环境通常都是多个服务器组成的集群。于是小灰想到了利用分布式锁。

所谓分布式锁有很多种,可以利用ZooKeeper、MemCache、Redis来实现。其中Redis的方式比较简单,无非是利用一个服务器之间共享的Key,以及Setnx指令。
当第一个线程执行Setnx,会存储对应的键值,相当于成功获得锁。当后续再有线程对同于的Key执行Setnx指令,则会返回空,相当于抢锁失败。同时,为了防止一个线程因意外情况而长久把持着锁,程序对Key设置了1秒的过期时间。
归纳一下修改后的逻辑:
1.查询缓存,如果缓存存在,返回结果
2.缓存不存在,查询数据库
3.争夺分布式锁
4.成功获得锁,把查询数据库的结果循环放入缓存
5.释放分布式锁





诡异的bug又重现了,因为小灰上次的改动仍然存在一个致命的漏洞。在这里我们假定缓存不存在,刚好有两个线程A和B一后一先进入到代码块。
第一阶段,线程A刚开始查询优惠券缓存,线程B正尝试获取分布式锁:

第二阶段,由于缓存不存在,线程A开始查询数据库,线程B成功获得锁,开始更新缓存:

第三阶段,线程A尝试获得分布式锁,而线程B已经释放分布式锁:

第四阶段,线程A获得了锁,又一次更新缓存,而线程B已经成功返回:

就这样,缓存被重复更新了两次,所以再次出现数据重复的bug。
这种局面如何破解呢?其实不难,只需在线程成功得到锁以后,再次判断优惠券缓存的存在:

归纳一下修改后的逻辑:
1.查询缓存,如果缓存存在,返回结果
2.缓存不存在,查询数据库
3.争夺分布式锁
4.成功获得锁,再次判断缓存的存在
5.如果缓存仍旧不存在,把查询数据库的结果循环放入缓存
6.释放分布式锁
这种二次判断存在性的机制有一个专门的名字,叫做双重检测。该方法在线程安全的单例模式中也常常被用到。


小灰的回忆告一段落——



几点补充:
1.文中所使用的分布式锁,其实并不是“正宗”的分布式锁,当线程争夺锁失败的时候,会直接返回查询DB的结果,而不会依靠自旋机制来等锁。
2.为什么优惠券列表的信息要使用List类型来存入缓存,而不是把整个列表存为一个很长的Json字符串?这是由于业务需要,使用List在某些情况下更方便对单个优惠券信息进行修改(LSET指令)。
3.为什么优惠券列表的信息不使用Redis的Set或者Hash数据类型来存储,实现自动去重呢?对于Set类型,去重前需要对比整个字符串是否完全相同,而每一张优惠券是一个较长的Json字符串,对比的效率会比较低。使用Hash倒是可以实现高效的去重,但并未在根本上解决重复更新的问题。
转载自:程序员小灰

 浙公网安备 33010602011771号
浙公网安备 33010602011771号