主从复制、读写分离水平拆分及库表散列
web项目最原始的情况是一台服务器只能连接一个mysql服务器(c3p0只能配置一个mysql),但随着项目的增大,这种方案明显已经不能满足需求了。
Mysql主从复制,读写分离:
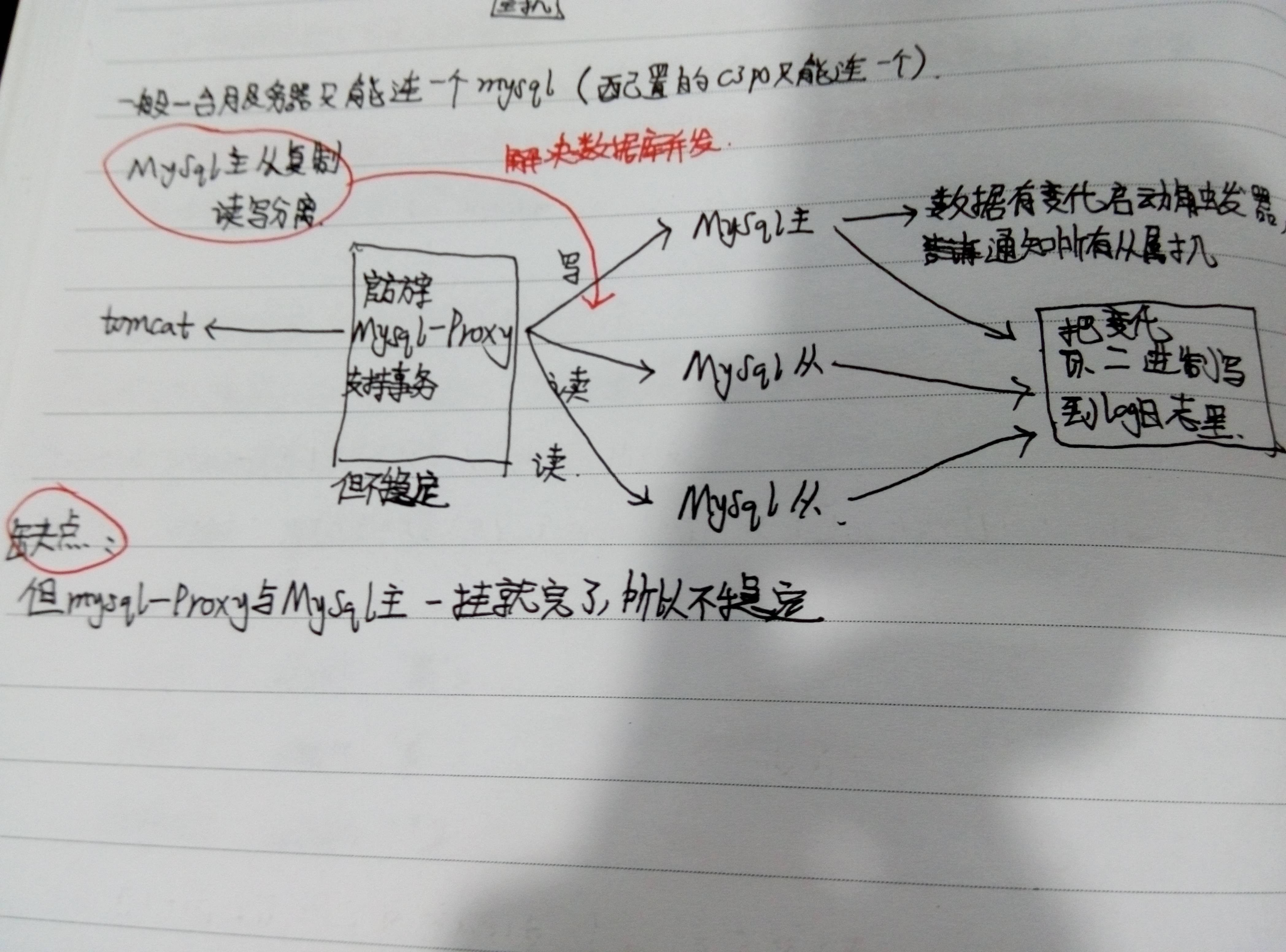
上面的方案使用mysql-Proxy代理,分发读写请求,写操作转发到Mysql主服务器,读操作转发到Mysql从服务器(多个),Mysql主服务器数据有变动时,会把变化以二进制的形式写入到log日志里,然后Mysql从服务器再从log日志中读取变化数据,以完成数据同步。
缺点:因为Mysql分发代理和Mysql主服务器都只有一台,一旦宕机就不行了,即很不稳定。
改进方案:
1,把tomcat和mysql代理放一台服务器上,比如一个项目有10台App服务器,每台服务器上都有tomat和Mysql-Proxy,进行数据库操作时,tomcat先连接本机上的myql代理,代理帮忙转发到各个mysql
2,同时,为了使mysql主机可靠,mysql主机也要配置多台,为了实现这种功能,要在多台myql主机之前配置负载均衡服务器,同时为了保证负载均衡服务器的可靠性,还要配置负载均衡—备机。虽然mysql主机有多台,但要保证只有一台会把数据变化写入到log日志里。
缺点:
1,会有数据延迟,比如mysql主机被写入修改了数据,但mysql从机还需要时间进行同步
2,比如运行一年之后,mysql主机上已经有了1千万条数据,并且这些数据都会被同步到所有从属mysql上,因为mysql对千万级别数据查询会变慢,导致mysql集群性能都会大大降低。
进一步改进方案,即数据库水平拆分及库表散列:
水平拆分一种方案:
比如有3个分片数据库服务器,每一个都有一个备机,每一组主机和备机数据都会同步。(至少一半的服务器效率浪费了)
(当资源有限时,可以把A分片数据库和B分片数据库的备机放在同一个服务器上,B数据库和C数据库的备机放到同一个服务器上....这样稳定性虽然降低了,服务器使用效率提高了)
然后一个用户表,因为id经常是数据库自动生成的,所以在新增用户数据的时候id是未知,不能根据id进行水平拆分。
可以根据用户用字段username.hashCode()返回一个int型数据,然后Math.abs()取绝对值,然后再% 1024取余数,这样获得的结果result就是0~1023
然后当0 <= result && result < 333时,把数据存放到第一个数据库,当333 <= result && result < 666时,把数据存放到第二个数据库,当666 <= result && result < 1024时,把数据存放到第三个数据库。
具体一些的代码:
①首先在spring配置文件application-context.xml中配置6个数据源:
- <!-- 数据源1 -->
- <bean id="dataSource1" class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <property name="driverClass" value="${jdbc.driverClassName}" />
- <property name="jdbcUrl" value="${jdbc1.url}" />
- <property name="user" value="${jdbc1.username}" />
- <property name="password" value="${jdbc1.password}" />
- <property name="autoCommitOnClose" value="true"/>
- <property name="initialPoolSize" value="${cpool.minPoolSize}"/>
- <property name="minPoolSize" value="${cpool.minPoolSize}"/>
- <property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
- <property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
- <property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
- <property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
- </bean>
- <!-- 数据源2 -->
- <bean id="dataSource2" class="com.mchange.v2.c3p0.ComboPooledDataSource">
- <property name="driverClass" value="${jdbc.driverClassName}" />
- <property name="jdbcUrl" value="${jdbc2.url}" />
- <property name="user" value="${jdbc2.username}" />
- <property name="password" value="${jdbc2.password}" />
- <property name="autoCommitOnClose" value="true"/>
- <property name="initialPoolSize" value="${cpool.minPoolSize}"/>
- <property name="minPoolSize" value="${cpool.minPoolSize}"/>
- <property name="maxPoolSize" value="${cpool.maxPoolSize}"/>
- <property name="maxIdleTime" value="${cpool.maxIdleTime}"/>
- <property name="acquireIncrement" value="${cpool.acquireIncrement}"/>
- <property name="maxIdleTimeExcessConnections" value="${cpool.maxIdleTimeExcessConnections}"/>
- </bean>
- 一共类似6个
②引入配置的6个数据源(3组,每组一个主数据库一个备数据库):
- <!-- 配置数据源开始 -->
- <bean id="dataSources" class="com.caland.sun.client.datasources.DefaultDataSourceService">
- <property name="dataSourceDescriptors">
- <set>
- <bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
- <property name="identity" value="partition1"/>
- <!-- 指定数据源1 -->
- <property name="targetDataSource" ref="dataSource1"/>
- <!-- 对数据源1进行心跳检测 -->
- <property name="targetDetectorDataSource" ref="dataSource1"/>
- <!-- 指定备机数据源4 -->
- <property name="standbyDataSource" ref="dataSource4"/>
- <!-- 对备机进行心跳检测 -->
- <property name="standbyDetectorDataSource" ref="dataSource4"/>
- </bean>
- <bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
- <property name="identity" value="partition2"/>
- <property name="targetDataSource" ref="dataSource2"/>
- <property name="targetDetectorDataSource" ref="dataSource2"/>
- <property name="standbyDataSource" ref="dataSource5"/>
- <property name="standbyDetectorDataSource" ref="dataSource5"/>
- </bean>
- <bean class="com.caland.sun.client.datasources.DataSourceDescriptor">
- <property name="identity" value="partition3"/>
- <property name="targetDataSource" ref="dataSource3"/>
- <property name="targetDetectorDataSource" ref="dataSource3"/>
- <property name="standbyDataSource" ref="dataSource6"/>
- <property name="standbyDetectorDataSource" ref="dataSource6"/>
- </bean>
- </set>
- </property>
- <!-- HA配置,对数据库发送SQL语句:update caland set timeflag=CURRENT_TIMESTAMP()进行数据库状态检测 -->
- <property name="haDataSourceCreator">
- <bean class="com.caland.sun.client.datasources.ha.FailoverHotSwapDataSourceCreator">
- <property name="detectingSql" value="update caland set timeflag=CURRENT_TIMESTAMP()"/>
- </bean>
- </property>
- </bean>
③继续在application-context.xml中配置路由规则
- <!-- 配置路由规则开始 -->
- <!-- hash算法实现类 -->
- <bean id="hashFunction" class="com.caland.core.dao.router.HashFunction"/>
- <bean id="internalRouter"
- class="com.caland.sun.client.router.config.InteralRouterXmlFactoryBean">
- <!-- functionsMap是在使用自定义路由规则函数的时候使用 -->
- <property name="functionsMap">
- <map>
- <entry key="hash" value-ref="hashFunction"></entry>
- </map>
- </property>
- <property name="configLocations">
- <list>
- <!-- 路由规则文件 -->
- <value>classpath:/dbRule/sharding-rules-on-namespace.xml</value>
- </list>
- </property>
- </bean>
其中,sharding-rules-on-namespace.xml:
- <rules>
- <rule>
- <namespace>User</namespace>
- <!--
- 对用户名username调用自定义路由规则,如果返回的结果为1,则进入分片数据库1,以此类推1,2,3
- 表达式如果不使用自定义路由规则函数,而是直接使用 taobaoId%2==0这种的话就不用在文件
- 中配置<property name="functionsMap">中了
- -->
- <shardingExpression>hash.applyUser(username) == 1</shardingExpression>
- <shards>partition1</shards>
- </rule>
- <rule>
- <namespace>User</namespace>
- <shardingExpression>hash.applyUser(username) == 2</shardingExpression>
- <shards>partition2</shards>
- </rule>
- <rule>
- <namespace>User</namespace>
- <shardingExpression>hash.applyUser(username) == 3</shardingExpression>
- <shards>partition3</shards>
- </rule>
- </rules>
HashFunction.java:
- public class HashFunction{
- /**
- * 对三个数据库进行散列分布
- * 1、返回其他值,没有在配置文件中配置的,如负数等,在默认数据库中查找
- * 2、比如现在配置文件中配置有三个结果进行散列,如果返回为0,那么apply方法只调用一次,如果返回为2,
- * 那么apply方法就会被调用三次,也就是每次是按照配置文件的顺序依次的调用方法进行判断结果,而不会缓存方法返回值进行判断
- * @param id
- * @return
- */
- public int applyUser(String username) {
- //先从缓存获取 没有则查询数据库
- //input 可能是id,拿id到缓存里去查用户的DB坐标信息。然后把库的编号输出
- int result = Math.abs(username.hashCode() % 1024);//0---1023
- System.out.println("hash:" + result);//333
- if(0 <= result && result < 256){
- result = 1;
- System.out.println("在第1个数据库中");
- }
- if(256 <= result && result < 512){
- result = 2;
- System.out.println("在第2个数据库中");
- }
- if(512 <= result && result < 1024){
- result = 3;
- System.out.println("在第3个数据库中");
- }
- return result;
- }
- }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号