使用 MySQL 管理层次结构的数据
概述
我们知道,关系数据库的表更适合扁平的列表,而不是像 XML 那样可以直管的保存具有父子关系的层次结构数据。
首先定义一下我们讨论的层次结构,是这样的一组数据,每个条目只能有一个父条目,可以有零个或多个子条目(唯一的例外是根条目,它没有父条目)。许多依赖数据库的应用都会遇到层次结构的数据,例如论坛或邮件列表的线索、企业的组织结构图、内容管理系统或商城的分类目录等等。我们如下数据作为示例:
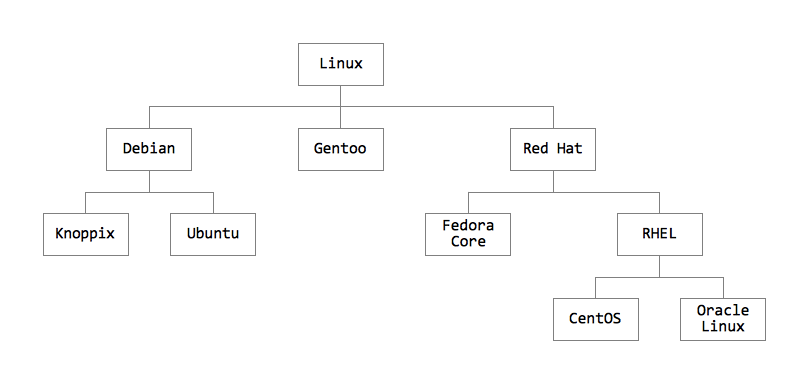
数据来源于维基百科的这个页面,为什么挑了这几个条目,以及是否准确合理在这里就不深究了。
Mike Hillyer 考虑了两种不同的模型——邻接表(Adjacency List)和嵌套集(Nested Set)来实现这个层次结构。
邻接表(Adjacency List)模型
我们可以很直观的使用下面的方式来保存如图所示的结构。
创建名为 distributions 的表:
CREATE TABLE distributions (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL,
parent INT NULL DEFAULT NULL,
PRIMARY KEY (id)
)
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8;插入数据:
INSERT INTO distributions VALUES
(1, 'Linux', NULL),
(2, 'Debian', 1),
(3, 'Knoppix', 2),
(4, 'Ubuntu', 2),
(5, 'Gentoo', 1),
(6, 'Red Hat', 1),
(7, 'Fedora Core', 6),
(8, 'RHEL', 6),
(9, 'CentOS', 8),
(10, 'Oracle Linux', 8);执行:
SELECT * FROM distributions;可以看到表中的数据形如:
+----+--------------+--------+
| id | name | parent |
+----+--------------+--------+
| 1 | Linux | NULL |
| 2 | Debian | 1 |
| 3 | Knoppix | 2 |
| 4 | Ubuntu | 2 |
| 5 | Gentoo | 1 |
| 6 | Red Hat | 1 |
| 7 | Fedora Core | 6 |
| 8 | RHEL | 6 |
| 9 | CentOS | 8 |
| 10 | Oracle Linux | 8 |
+----+--------------+--------+使用链接表模型,表中的每一条记录都包含一个指向其上层记录的指针。顶层记录(这个例子中是 Linux)的这个字段的值为 NULL。邻接表的优势是相当直观和简单,我们一眼就能看出 CentOS 衍生自 RHEL,后者又是从 Red Hat 发展而来的。虽然客户端程序可能处理起来相当简单,但是使用纯 SQL 处理邻接表则会遇到一些麻烦。
获取整棵树以及单个节点的完整路径
第一个处理层次结构常见的任务是显示整个层次结构,通常包含一定的缩进。使用纯 SQL 处理时通常需要借助所谓的 self-join 技巧:
SELECT
t1.name AS level1,
t2.name as level2,
t3.name as level3,
t4.name as level4
FROM
distributions AS t1
LEFT JOIN distributions AS t2
ON t2.parent = t1.id
LEFT JOIN distributions AS t3
ON t3.parent = t2.id
LEFT JOIN distributions AS t4
ON t4.parent = t3.id
WHERE t1.name = 'Linux';结果如下:
+--------+---------+-------------+--------------+
| level1 | level2 | level3 | level4 |
+--------+---------+-------------+--------------+
| Linux | Red Hat | RHEL | CentOS |
| Linux | Red Hat | RHEL | Oracle Linux |
| Linux | Debian | Knoppix | NULL |
| Linux | Debian | Ubuntu | NULL |
| Linux | Red Hat | Fedora Core | NULL |
| Linux | Gentoo | NULL | NULL |
+--------+---------+-------------+--------------+可以看到,实际上客户端代码拿到这个结果也不容易处理。对比原文,我们发现返回结果的顺序也是不确定的。在实践中没有什么参考意义。不过可以通过增加一个 WHERE 条件,获取一个节点的完整路径:
SELECT
t1.name AS level1,
t2.name as level2,
t3.name as level3,
t4.name as level4
FROM
distributions AS t1
LEFT JOIN distributions AS t2
ON t2.parent = t1.id
LEFT JOIN distributions AS t3
ON t3.parent = t2.id
LEFT JOIN distributions AS t4
ON t4.parent = t3.id
WHERE
t1.name = 'Linux'
AND t4.name = 'CentOS';结果如下:
+--------+---------+--------+--------+
| level1 | level2 | level3 | level4 |
+--------+---------+--------+--------+
| Linux | Red Hat | RHEL | CentOS |
+--------+---------+--------+--------+找出所有的叶节点
使用 LEFT JOIN 我们可以找出所有的叶节点:
SELECT
distributions.id, distributions.name
FROM
distributions
LEFT JOIN distributions as child
ON distributions.id = child.parent
WHERE child.id IS NULL;结果如下:
+----+--------------+
| id | name |
+----+--------------+
| 3 | Knoppix |
| 4 | Ubuntu |
| 5 | Gentoo |
| 7 | Fedora Core |
| 9 | CentOS |
| 10 | Oracle Linux |
+----+--------------+邻接表模型的限制
使用纯 SQL 处理邻接表模型即便在最好的情况下也是困难的。要获得一个分类的完整路径之前我们需要知道它的层次有多深。除此之外,当我们删除一个节点时我们需要格外的谨慎,因为这可能潜在的在处理过程中整个子树成为孤儿(例如删除『便携式小家电』则所有其子分类都成为孤儿了)。其中一些限制可以在客户端代码或存储过程中定位并处理。例如在存储过程中我们可以自下而上的遍历这个结构以便返回整棵树或一个路径。我们也可以使用存储过程来删除节点,通过提升其一个子节点的层次并重新设置所有其它子节点的父节点为这个节点,来避免整棵子树成为孤儿。
嵌套集(Nested Set)模型
由于使用纯 SQL 处理邻接表模型存在种种不便,因此 Mike Hillyer 郑重的介绍了嵌套集(Nested Set)模型。当使用这种模型时,我们把层次结构的节点和路径从脑海中抹去,把它们想象为一个个容器:
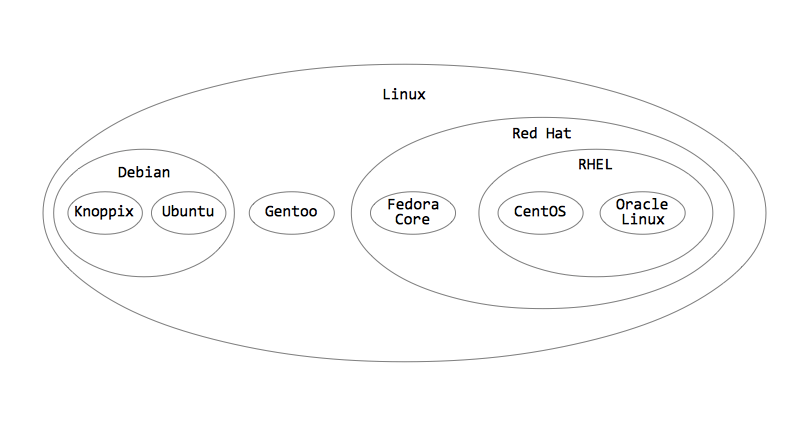
可以看到层次关系没有改变,大的容器包含子容器。我们使用容器的左值和右值来建立数据表:
CREATE TABLE nested (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(32) NOT NULL,
`left` INT NOT NULL,
`right` INT NOT NULL,
PRIMARY KEY (id)
)
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8;需要注意 left 和 right 是 MySQL 的保留字,因此使用标识分隔符来标记它们。
插入数据:
INSERT INTO nested VALUES
(1, 'Linux', 1, 20),
(2, 'Debian', 2, 7),
(3, 'Knoppix', 3, 4),
(4, 'Ubuntu', 5, 6),
(5, 'Gentoo', 8, 9),
(6, 'Red Hat', 10, 19),
(7, 'Fedora Core', 11, 12),
(8, 'RHEL', 13, 18),
(9, 'CentOS', 14, 15),
(10, 'Oracle Linux', 16, 17);查看内容:
SELECT * FROM nested ORDER BY id;可以看到:
+----+--------------+------+-------+
| id | name | left | right |
+----+--------------+------+-------+
| 1 | Linux | 1 | 20 |
| 2 | Debian | 2 | 7 |
| 3 | Knoppix | 3 | 4 |
| 4 | Ubuntu | 5 | 6 |
| 5 | Gentoo | 8 | 9 |
| 6 | Red Hat | 10 | 19 |
| 7 | Fedora Core | 11 | 12 |
| 8 | RHEL | 13 | 18 |
| 9 | CentOS | 14 | 15 |
| 10 | Oracle Linux | 16 | 17 |
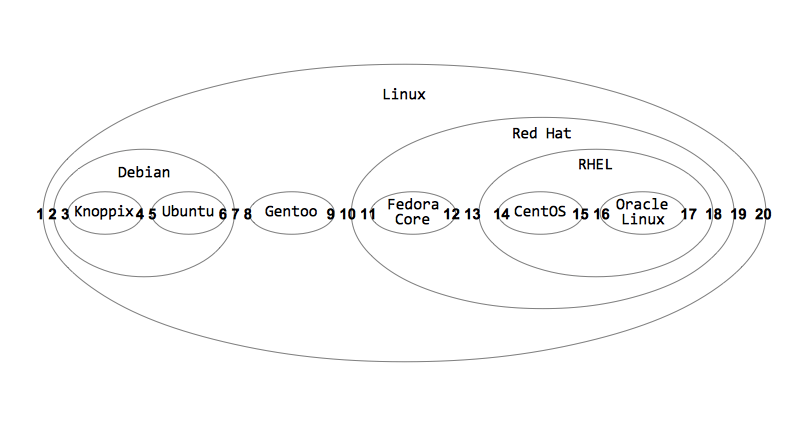
+----+--------------+------+-------+我们是如何确定左编号和右编号的呢,通过下图我们可以直观的发现只要会数数即可完成:
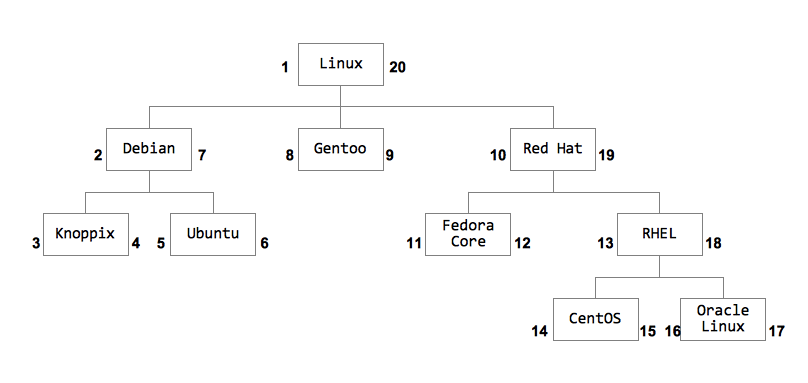
回到树形模型该怎么处理,通过下图,对数据结构稍有概念的人都会知道,稍加改动的先序遍历算法即可完成这项编号的工作:
获取整棵树
一个节点的左编号总是介于其父节点的左右编号之间,利用这个特性使用 self-join 链接到父节点,可以获取整棵树:
SELECT node.name
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND parent.name = 'Linux'
ORDER BY node.`left`;结果如下:
+--------------+
| name |
+--------------+
| Linux |
| Debian |
| Knoppix |
| Ubuntu |
| Gentoo |
| Red Hat |
| Fedora Core |
| RHEL |
| CentOS |
| Oracle Linux |
+--------------+但是这样我们丢失了层次的信息。怎么办呢?使用 COUNT() 函数和 GROUP BY 子句,可以实现这个目的:
SELECT
node.name, (COUNT(parent.name) - 1) AS depth
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
GROUP BY node.name
ORDER BY ANY_VALUE(node.`left`);需要注意 MySQL 5.7.5 开始默认启用了 only_full_group_by 模式,让 GROUP BY 的行为与 SQL92 标准一致,因此直接使用 ORDER BY node.`left` 会产生错误:
ERROR 1055 (42000): Expression #1 of ORDER BY clause is not in GROUP BY clause and contains nonaggregated column'test.node.left' which is not functionally dependent on columns in GROUP BY clause; this is incompatible withsql_mode=only_full_group_by使用 ANY_VALUE() 是避免这个问题的一种的途径。
结果如下:
+--------------+-------+
| name | depth |
+--------------+-------+
| Linux | 0 |
| Debian | 1 |
| Knoppix | 2 |
| Ubuntu | 2 |
| Gentoo | 1 |
| Red Hat | 1 |
| Fedora Core | 2 |
| RHEL | 2 |
| CentOS | 3 |
| Oracle Linux | 3 |
+--------------+-------+稍作调整就可以直接显示层次:
SELECT
CONCAT(REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
GROUP BY node.name
ORDER BY ANY_VALUE(node.`left`);结果相当漂亮:
+-----------------+
| name |
+-----------------+
| Linux |
| Debian |
| Knoppix |
| Ubuntu |
| Gentoo |
| Red Hat |
| Fedora Core |
| RHEL |
| CentOS |
| Oracle Linux |
+-----------------+当然客户端代码可能会更倾向于使用 depth 值,对返回的结果集进行循环,Web 开发人员可以根据其增大或减小使用 <li>/</li>或 <ul>/</ul> 等。
获取节点在子树中的深度
要获取节点在子树中的深度,我们需要第三个 self-join 以及子查询来将结果限制在特定的子树中以及进行必要的计算:
SELECT
node.name, (COUNT(parent.name) - ANY_VALUE(sub_tree.depth) - 1) AS depth
FROM
nested AS node,
nested AS parent,
nested AS sub_parent,
(
SELECT
node.name, (COUNT(parent.name) - 1) AS depth
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND node.name = 'Red Hat'
GROUP BY node.name, node.`left`
ORDER BY node.`left`
) AS sub_tree
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND node.`left` BETWEEN sub_parent.`left` AND sub_parent.`right`
AND sub_parent.name = sub_tree.name
GROUP BY node.name
ORDER BY ANY_VALUE(node.`left`);结果是:
+--------------+-------+
| name | depth |
+--------------+-------+
| Red Hat | 0 |
| Fedora Core | 1 |
| RHEL | 1 |
| CentOS | 2 |
| Oracle Linux | 2 |
+--------------+-------+寻找一个节点的直接子节点
使用邻接表模型时这相当简单。使用嵌套集时,我们可以在上面获取子树各节点深度的基础上增加一个 HAVING 子句来实现:
SELECT
node.name, (COUNT(parent.name) - ANY_VALUE(sub_tree.depth) - 1) AS depth
FROM
nested AS node,
nested AS parent,
nested AS sub_parent,
(
SELECT
node.name, (COUNT(parent.name) - 1) AS depth
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND node.name = 'Red Hat'
GROUP BY node.name, node.`left`
ORDER BY node.`left`
) AS sub_tree
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND node.`left` BETWEEN sub_parent.`left` AND sub_parent.`right`
AND sub_parent.name = sub_tree.name
GROUP BY node.name
HAVING depth = 1
ORDER BY ANY_VALUE(node.`left`);结果:
+-------------+-------+
| name | depth |
+-------------+-------+
| Fedora Core | 1 |
| RHEL | 1 |
+-------------+-------+获取所有叶节点
观察带编号的嵌套模型,叶节点的判断相当简单,右编号恰好比左编号多 1 的节点就是叶节点:
SELECT id, name FROM nested WHERE `right` = `left` + 1;结果如下:
+----+--------------+
| id | name |
+----+--------------+
| 3 | Knoppix |
| 4 | Ubuntu |
| 5 | Gentoo |
| 7 | Fedora Core |
| 9 | CentOS |
| 10 | Oracle Linux |
+----+--------------+获取单个节点的完整路径
仍然是使用 self-join 技巧,不过现在无需顾虑节点的深度了:
SELECT parent.name
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND node.name = 'CentOS'
ORDER BY parent.`left`;结果如下:
+---------+
| name |
+---------+
| Linux |
| Red Hat |
| RHEL |
| CentOS |
+---------+聚集操作
我们添加一张 releases 表,来展示一下在嵌套集模型下的聚集(aggregate)操作:
CREATE TABLE releases (
id INT NOT NULL AUTO_INCREMENT,
distribution_id INT NULL,
name VARCHAR(32) NOT NULL,
PRIMARY KEY (id),
INDEX distribution_id_idx (distribution_id ASC),
CONSTRAINT distribution_id
FOREIGN KEY (distribution_id)
REFERENCES nested (id)
ON DELETE CASCADE
ON UPDATE CASCADE
)
ENGINE = InnoDB
DEFAULT CHARACTER SET = utf8;加入一些数据,假设这些数据是指某个软件支持的发行版:
INSERT INTO releases (distribution_id, name) VALUES
(2, '7'), (2, '8'),
(4, '14.04 LTS'), (4, '15.10'),
(7, '22'), (7, '23'),
(9, '5'), (9, '6'), (9, '7');那么,下面的查询可以知道每个节点下涉及的发布版数量,如果这是一个软件支持的发布版清单,或许测试人员想要知道他们得准备多少种虚拟机吧:
SELECT
parent.name, COUNT(releases.name)
FROM
nested AS node ,
nested AS parent,
releases
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
AND node.id = releases.distribution_id
GROUP BY parent.name
ORDER BY ANY_VALUE(parent.`left`);结果如下:
+-------------+----------------------+
| name | COUNT(releases.name) |
+-------------+----------------------+
| Linux | 9 |
| Debian | 4 |
| Ubuntu | 2 |
| Red Hat | 5 |
| Fedora Core | 2 |
| CentOS | 3 |
+-------------+----------------------+如果层次结构是一个分类目录,这个技巧可以用于查询各个类别下有多少关联的商品。
添加节点
再次回顾这张图:
如果我们要在 Gentoo 之后增加一个 Slackware,这个新节点的左右编号分别是 10 和 11,而原来从 10 开始的所有编号都需要加 2。我们可以:
LOCK TABLE nested WRITE;
SELECT @baseIndex := `right` FROM nested WHERE name = 'Gentoo';
UPDATE nested SET `right` = `right` + 2 WHERE `right` > @baseIndex;
UPDATE nested SET `left` = `left` + 2 WHERE `left` > @baseIndex;
INSERT INTO nested (name, `left`, `right`) VALUES
('Slackware', @baseIndex + 1, @baseIndex + 2);
UNLOCK TABLES;使用之前掌握的技巧看一下现在的情况:
SELECT
CONCAT(REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
GROUP BY node.name
ORDER BY ANY_VALUE(node.`left`);结果为:
+-----------------+
| name |
+-----------------+
| Linux |
| Debian |
| Knoppix |
| Ubuntu |
| Gentoo |
| Slackware |
| Red Hat |
| Fedora Core |
| RHEL |
| CentOS |
| Oracle Linux |
+-----------------+如果新增的节点的父节点原来是叶节点,我们需要稍微调整一下之前的代码。例如,我们要新增 Slax 作为 Slackware 的子节点:
LOCK TABLE nested WRITE;
SELECT @baseIndex := `left` FROM nested WHERE name = 'Slackware';
UPDATE nested SET `right` = `right` + 2 WHERE `right` > @baseIndex;
UPDATE nested SET `left` = `left` + 2 WHERE `left` > @baseIndex;
INSERT INTO nested(name, `left`, `right`) VALUES ('Slax', @baseIndex + 1, @baseIndex + 2);
UNLOCK TABLES;现在,数据形如:
+-----------------+
| name |
+-----------------+
| Linux |
| Debian |
| Knoppix |
| Ubuntu |
| Gentoo |
| Slackware |
| Slax |
| Red Hat |
| Fedora Core |
| RHEL |
| CentOS |
| Oracle Linux |
+-----------------+删除节点
删除节点的操作与添加操作相对,当要删除一个叶节点时,移除该节点并将所有比该节点右编码大的编码减 2。这个思路可以扩展到删除一个节点及其所有子节点的情况,删除左编码介于节点左右编号之间的所有节点,将右侧的节点编号全部左移该节点原编号宽度即可:
LOCK TABLE nested WRITE;
SELECT
@nodeLeft := `left`,
@nodeRight := `right`,
@nodeWidth := `right` - `left` + 1
FROM nested
WHERE name = 'Slackware';
DELETE FROM nested WHERE `left` BETWEEN @nodeLeft AND @nodeRight;
UPDATE nested SET `right` = `right` - @nodeWidth WHERE `right` > @nodeRight;
UPDATE nested SET `left` = `left` - @nodeWidth WHERE `left` > @nodeRight;
UNLOCK TABLES;可以看到 Slackware 子树被删除了:
+-----------------+
| name |
+-----------------+
| Linux |
| Debian |
| Knoppix |
| Ubuntu |
| Gentoo |
| Red Hat |
| Fedora Core |
| RHEL |
| CentOS |
| Oracle Linux |
+-----------------+稍加调整,如果对介于要删除节点左右编号直接的节点对应编号左移 1,右侧节点对应编号左移 2,则可以实现删除一个节点,其子节点提升一层的效果,例如我们尝试删除 RHEL 但保留它的子节点:
LOCK TABLE nested WRITE;
SELECT
@nodeLeft := `left`,
@nodeRight := `right`
FROM nested
WHERE name = 'RHEL';
DELETE FROM nested WHERE `left` = @nodeLeft;
UPDATE nested SET `right` = `right` - 1, `left` = `left` - 1 WHERE `left` BETWEEN @nodeLeft AND @nodeRight;
UPDATE nested SET `right` = `right` - 2 WHERE `right` > @nodeRight;
UPDATE nested SET `left` = `left` - 2 WHERE `left` > @nodeRight;
UNLOCK TABLES;结果为:
SELECT
CONCAT(REPEAT(' ', COUNT(parent.name) - 1), node.name) AS name
FROM
nested AS node,
nested AS parent
WHERE
node.`left` BETWEEN parent.`left` AND parent.`right`
GROUP BY node.name
ORDER BY ANY_VALUE(node.`left`);+----------------+
| name |
+----------------+
| Linux |
| Debian |
| Knoppix |
| Ubuntu |
| Gentoo |
| Red Hat |
| Fedora Core |
| CentOS |
| Oracle Linux |
+----------------+
 浙公网安备 33010602011771号
浙公网安备 33010602011771号