

聊聊分库分表后非Sharding Key查询的三种方案~(建议收藏)
对于toC的业务来说,需要选择用户属性如 user_id 作为分片键。
那问题来了,对于订单表来说,选择了user_id作为分片键以后如何查看订单详情呢?比如下面这样一条SQL:
SELECT * FROM T_ORDER WHERE order_id = 801462878019256325
由于查询条件中的order_id不是分片键,所以需要查询所有分片才能得到最终的结果。如果下面有 1000 个分片,那么就需要执行 1000 次这样的 SQL,这时性能就比较差了。
可以通过ShardingSphere-JDBC生成的SQL得知,根据order_id查询会对所有分片进行查询然后通过UNION ALL进行合并。

但是,我们知道 order_id 是主键,应该只有一条返回记录,也就是说,order_id 只存在于一个分片中。这时,可以有以下三种设计:
- 冗余数据法
- 索引表法
- 基因分片法
当然,这三种设计的本质都是通过冗余实现空间换时间的效果,否则就需要扫描所有的分片,当分片数据非常多,效率就会变得极差。
下面我们逐一分析。
设计一:冗余法
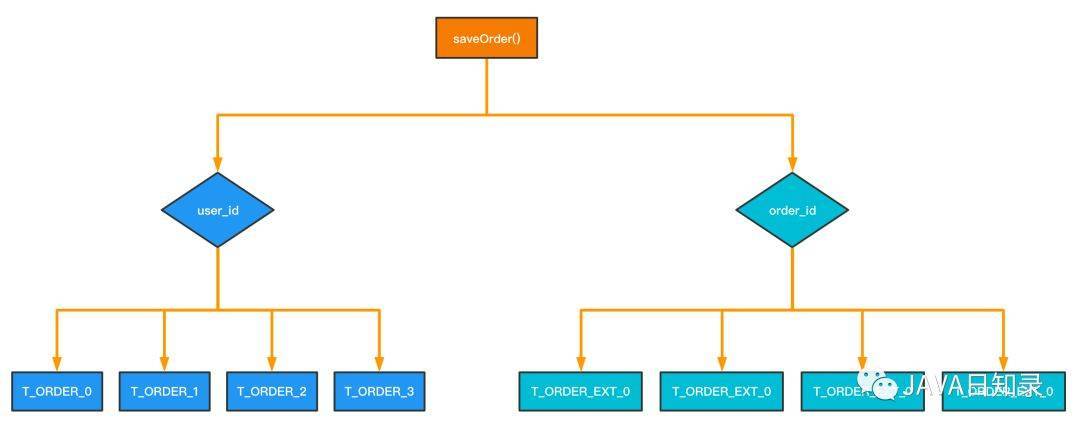
这种做法很容易理解,同一份订单数据在插入时保存两份,根据user_id 和 order_id分别做两个分库分表的实现。
通过对表进行冗余,对于 order_id 的查询,只需要在 order_id = 801462878019256325 的分片中直接查询就行,效率最高。但是这个方案设计的缺点又很明显:冗余数据量太大。
方法二:索引表法
索引表法是对第一种冗余法的改进,由于第一种方案冗余的数据量太大,所以索引表方案中只创建一个包含user_id和order_id的索引表,在插入订单时再插入一条数据到索引表中。
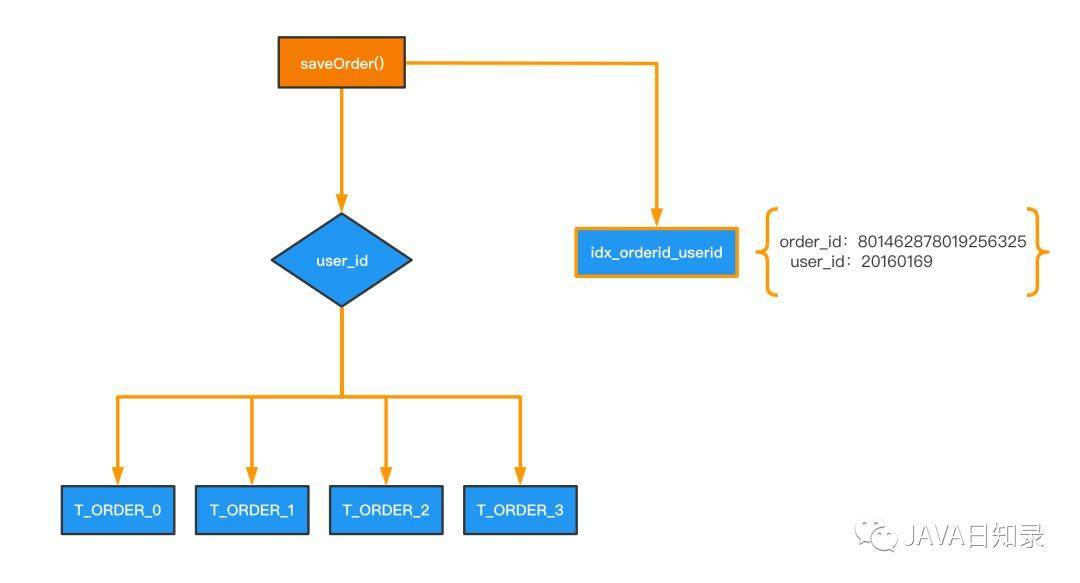
表结构如下
CREATE TABLE idx_orderid_userid (
order_id bigint
user_id bigint,
PRIMARY KEY (order_id)
)
在实现时可以将idx_orderid_userid表通过Redis缓存来代替,如果此表数据量很大也可以将其分库分表,但是它的分片键必须是 order_id。
如果这时再根据字段 order_id 进行查询,可以进行类似二级索引的回表实现:先通过查询索引表得到记录 order_id = 801462878019256325 对应的分片键 user_id 的值,接着再根据 user_id 进行查询,最终定位到想要的数据,如:
原始SQL:
SELECT * FROM T_ORDER WHERE order_id = 801462878019256325
拆分后的SQL:
# step 1
SELECT user_id FROM idx_orderid_userid
WHERE order_id = 801462890610556951
# step 2
SELECT * FROM T_ORDER
WHERE user_id = ? AND order_id = 801462890610556951
这个例子是将一条 SQL 语句拆分成 2 条 SQL 语句,但是拆分后的 2 条 SQL 都可以通过分片键进行查询,这样能保证只需要在单个分片中完成查询操作。
不论有多少个分片,也只需要查询 2个分片的信息,这样 SQL 的查询性能可以得到极大的提升。
方法三:基因法
通过索引表的方式,虽然存储上较冗余全表容量小了很多,但是要根据另一个分片键进行数据的存储,还是显得不够优雅。
因此,最优的设计,不是创建一个索引表,而是将分片键的信息保存在想要查询的列中,这样通过查询的列就能直接知道所在的分片信息,这种方法也叫叫做基因法。
基因法的原理出自一个理论:对一个数取余2的n次方,那么余数就是这个数的二进制的最后n位数。
假如我们现在根据user_id进行分片,采用 (user_id % 16) 的方式来进行数据库路由,这里的 user_id%16,其本质是user_id的最后4个bit位log(16,2) = 4 决定这行数据落在哪个分片上,这4个bit就是分片基因。
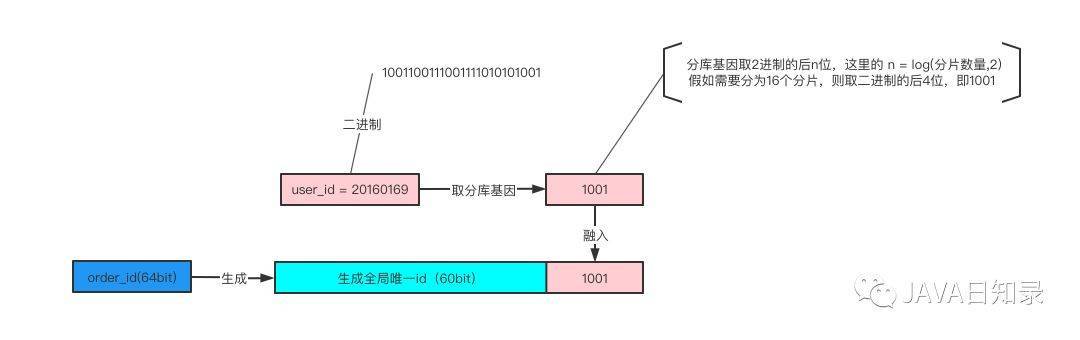
如上图所示,user_id=20160169的用户创建了一个订单(20160169的二进制表示为:1001100111001111010101001)
- 使用user_id%16分片,决定这行数据要插入到哪个分片中
- 分库基因是user_id的最后4个bit,log(16,2) = 4,即1001
- 在生成order_id时,先使用一种分布式ID生成算法生成前60bit(上图中绿色部分)
- 将分库基因加入到order_id的最后4个bit(上图中粉色部分)
- 拼装成最终的64bit订单order_id(上图中蓝色部分)
这样保证了同一个用户创建的所有订单都落到了同一个分片上,order_id的最后4个bit都相同,于是:
- 通过user_id %16 能够定位到分片
- 通过order_id % 16也能定位到分片
不好理解的话,可以看下面这段代码:
@Test
public void modIdTest()<{p> long userID = 20160169L;
//分片数量
int shardNum = 16;
String gen = getGen(userID, shardNum);
log.info("userID:{}的基因为:{}",userID,gen);
long snowId = IdWorker.getId(Order.class);
log.info("雪花算法生成的订单ID为{}",snowId);
Long orderId = buildGenId(snowId,gen);
log.info("基因转换后的订单ID为{}",orderId);
Assert.assertEquals(orderId % shardNum , userID % shardNum);
}
运行结果如下:

原始订单ID为1595662702879973377,通过基因转换后ID变成了1595662702879973385,对于用户id 和 新生成的订单id对其取模结果一样。
上面那种做法是基因替换,替换掉订单id的分片基因。下面这种做法就更显直接。
将订单表 orders 的主键设计为一个字符串,这个字符串中最后一部分包含分片键的信息,如:
order_id = string(order_id + user_id)
那么这时如果根据 order_id 进行查询:
SELECT * FROM T_ORDER
WHERE order_id = '1595662702879973377-20160169';
由于字段 order_id 的设计中直接包含了分片键信息,所以我们可以直接通过分片键部分直接定位到分片上。
同样地,在插入时,由于可以知道插入时 user_id 对应的值,所以只要在业务层做一次字符的拼接,然后再插入数据库就行了。
这样的实现方式较冗余表和索引表的设计来说,效率更高,查询时可以直接定位到数据对应的分片信息,只需 1 次查询就能获取想要的结果。
这样实现的缺点是,主键值会变大一些,存储也会相应变大。但是只要主键值是有序的,插入的性能就不会变差。而通过在主键值中保存分片信息,却可以大大提升后续的查询效率,这样空间换时间的设计,总体上看是非常值得的。
实际上淘宝的订单号也是这样构建的
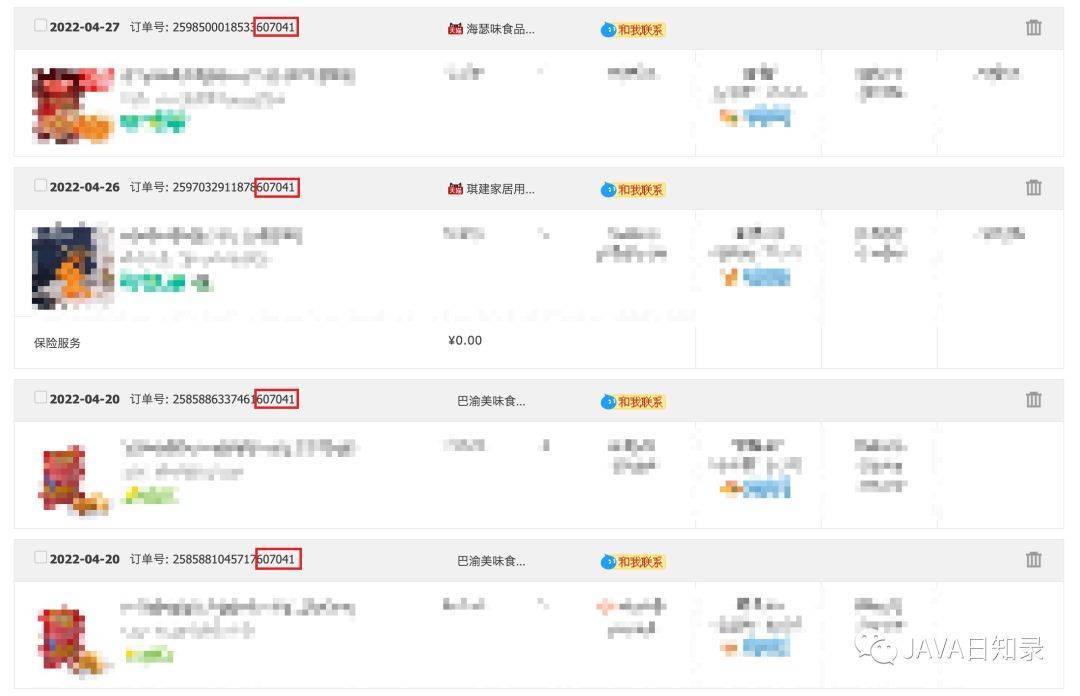
上图是我的淘宝订单信息,可以看到,订单号的最后 6 位都是 607041,所以可以大概率推测出:
- 淘宝订单表的分片键是用户 ID;
- 淘宝订单表,订单表的主键包含用户 ID,也就是分片信息。这样通过订单号进行查询,可以获得分片信息,从而查询 1 个分片就能得到最终的结果。
小结
分库分表后需要遵循一个基本原则:所有的查询尽量带上sharding key,有时候业务需要根据技术限制进行妥协,那种既要...又要...就是在耍流氓。
当然有些业务场景确实没办法避免,对于非sharding key的查询可以参考上面三种方案实现,不过实际上只能算两种。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 【杭电多校比赛记录】2025“钉耙编程”中国大学生算法设计春季联赛(1)
2016-03-05 jquery_dialog实现效果