MySQL 自增主键为啥不是连续递增
1、前言
一般,我们在建表都会设一个自增主键,因为自增主键可以让主键索引尽量地保持递增顺序插入,避免了页分裂,使得索引树更加紧凑。
自增主键保持着递增顺序插入,但如果依赖于自增主键的连续性,是会有问题的,因为自增主键并不能保证连续递增。
2、主键自增值
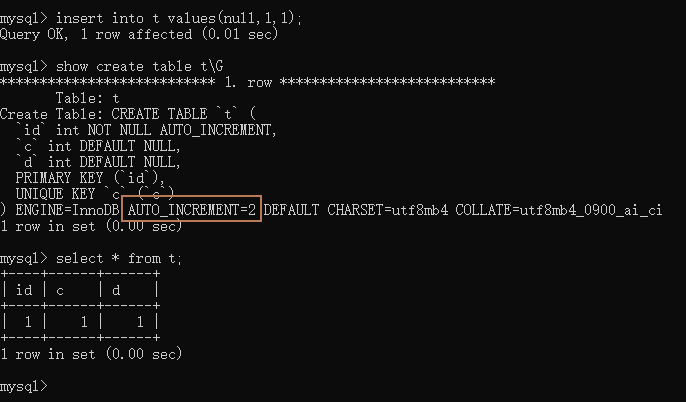
创建一个测试表,然后插入一行数据,那么下一次插入数据的时候,自增主键的值就会是2;
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into values(null,1,1); show create table t\G
3、自增值修改机制
在MySQL中,如果字段id被定义为AUTO_INCREMENT时,在插入一行数据的时候:
- 如果插入数据的id为0、null或者未指定值,那么就把这个表当前的AUTO_INCREMENT值填到自增字段;
- 如果插入数据的id指定了具体的值,就直接使用语句里指定的值。根据插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同,如果插入的值X < 当前自增的值Y,那么表的自增值不变;否则表的自增值修改为新的自增值。
自增值生成算法:从auto_increment_offset 开始,以auto_increment_increment 为步长,持续叠加,直到找到第一个大于X的值,作为新的自增值。auto_increment_offset 和auto_increment_increment 两个参数的默认值都是1。
自增值的修改流程:
假设表t中已有了(1,1,1)这条记录,那么再执行一条插入数据命令时:
insert into values(null,1,1);
-
执行器调用InnoDB引擎接口写入一行数据,传入的数据为(0,1,1);
-
InnoDB 发现没有指定自增id的值,获取表t当前的自增值 AUTO_INCREMENT = 2;
-
将传入的数据修改为(2,1,1);
-
将表的自增值修改为 AUTO_INCREMENT = 3;
-
执行插入操作,如果操作成功,则返回ok;如果出现唯一索引报错,则报Duplicate key error,语句返回。
唯一键冲突之前,即语句真正执行插入操作之前,就已经把 AUTO_INCREMENT 修改为3了,这是id = 2 这一行并没有插入成功,但也没有将 AUTO_INCREMENT 改回去,之所以不改回了,是为了在事务并发执行时,能确保拿到最准确的自增值,同时,也是为了性能考虑。
4、自增值为什么不能回退
假设有两个并行执行的事务,在申请自增值的时候,为了避免两个事务申请到相同的id,肯定要加锁,然后顺序申请。
-
假设事务A申请了id=2,事务B申请了id=3,那么这时候表t的自增值是4,继续执行
-
事务B先提交了,并且正确,但事务A出现了唯一键冲突。
-
如果允许事务A把自增id回退,那么表t当前的自增值将被改为2,就会出现表里面已经有id=3的行,而当前自增id值是2
-
接下来其他请求会陆续申请到id=2,id=3的情况,在执行插入语句时就会报“主键冲突”。
为了解决这个主键冲突,有两种方法:
-
每次申请自增值的时候,先去表中判断是否已经存在这个id,如果存在则跳过。本来申请id自增值是一个很快的操作,现在得去主键索引树上判断id是否存在,性能大打折扣。
-
把自增id的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增id,这个方法的问题是锁的粒度太大,系统并发能力大大下降。
这两个方法都会导致性能问题,是在假设允许”自增值回退“的前提下导致的。为了性能考虑InnoDB放弃了这个设计,使用最简单的方式获取自增值,即使语句执行失败也不回退自增id,因此自增id是递增的,但不保证是连续递增。
5、自增锁的优化
自增id锁并不是一个事务锁,而是每次申请完就马上释放,以便允许别的事务再申请。其实,在MySQL5.1版本之前,并不是这样的。
在MySQL 5.0版本的时候,自增锁的范围是语句级别。也就是说,如果一个语句申请了一个表自增锁,这个锁会等
语句执行结束以后才释放。显然,这样设计会影响并发度。
MySQL 5.1.22版本引入了一个新策略,新增参数innodb_autoinc_lock_mode,默认值是1.
-
这个参数的值被设置为0时,表示才用之前MySQL5.0版本的策略
-
这个参数的值被设置为1时:
-
普通insert语句,自增锁在申请之后就马上释放
-
类似 insert...select 这样的批量插入语句,自增锁还是要等语句结束后才释放
-
-
这个参数的值被设置为2时,所有的申请自增主键的动作都是申请后就释放锁。
疑问:为什么默认设置下,insert...select 要使用语句锁?为什么这个参数的默认值不是2?
答案是为了数据一致性。
解疑场景:

如果sessionB是申请了自增值以后马上就释放自增锁,那么就可能出现这样的情况:
-
sessionB先插入了两个记录,(1,1,1)、(2,2,2)
-
然后 sessionA来申请自增id得到id=3,插入了(3,5,5)
-
之后 sessionB继续执行,插入两条记录(4,3,3)、(5,4,4)
从数据逻辑上看,并没有问题,因为语义本身并没有要求t2的所有行的数据都跟sessionA相同。但是,如果我们现在的binlog_format=statement,binlog会怎么记录?
由于两个session是同时执行插入数据命令的,所有binlog对表t2的更新日志只有两种情况:要么先记sessionA,要么先记sessionB。但不论是哪一种情况,这个binlog拿去从库执行,或者用来恢复临时实例,备库和临时实例里面,sessionB这个语句执行出来,生成的结果里,id都是连续的,这时,这个库就发生了数据不一致。
要解决这个问题,有两种思路:
-
让原库的批量插入数据语句,固定生成连续的id值。所以,自增锁直到语句执行结束才释放,就是为了达到这个目的。
-
另一种是在binlog里面把插入数据的操作都如实记录进来,到备库执行的时候,就不再依赖自增主键去生成。这种情况,其实就是innodb_autoinc_lock_mode 设置为2,同时binlog_format设置为row。
因此,在生产上,尤其是有insert...select 这种批量插入数据的场景时,从并发插入数据性能的角度考虑,建议这样设置:innodb_autoinc_lock_mode = 2,并且binlog_format = row,这样做,既能提升并发性,又不会出现数据一致性问题。
批量插入数据,包含的语句类型是 insert...select、replace...select 和 load data 语句。
但是,在普通的insert语句里面包含多个value值的情况下,即时innodb_autoinc_lock_mode设置为1,也不会等语句执行完成才释放锁,因为这类语句在申请自增id的时候,是可以精确计算出需要多少个id的,然后一次性申请完,申请完就可以释放锁了。而批量插入数据的语句,之所以需要这么设置,是因为不知道预先要申请多少个自增id。
对于批量插入数据的语句,假设insert...select 有10万行数据,如果按照需要1个id就申请1次,那么就需要申请10万次,显然在大批量插入数据的情况下,不但速度慢,还会影响并发插入的性能。
MySQL有一个批量申请自增id的策略:
-
语句执行过程中,第一次申请自增id,会分配1个;
-
1个用完以后,这个语句第二次申请自增id,会分配2个;
-
2个用完以后,还是这个语句,第三次申请自增id,会分配4个;
-
依次类推,同一个语句去申请自增id,每次会申请到的自增id个数都是上一次的两倍。
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t; insert into t2(c,d) select c,d from t; insert into t2 values(null, 5,5);
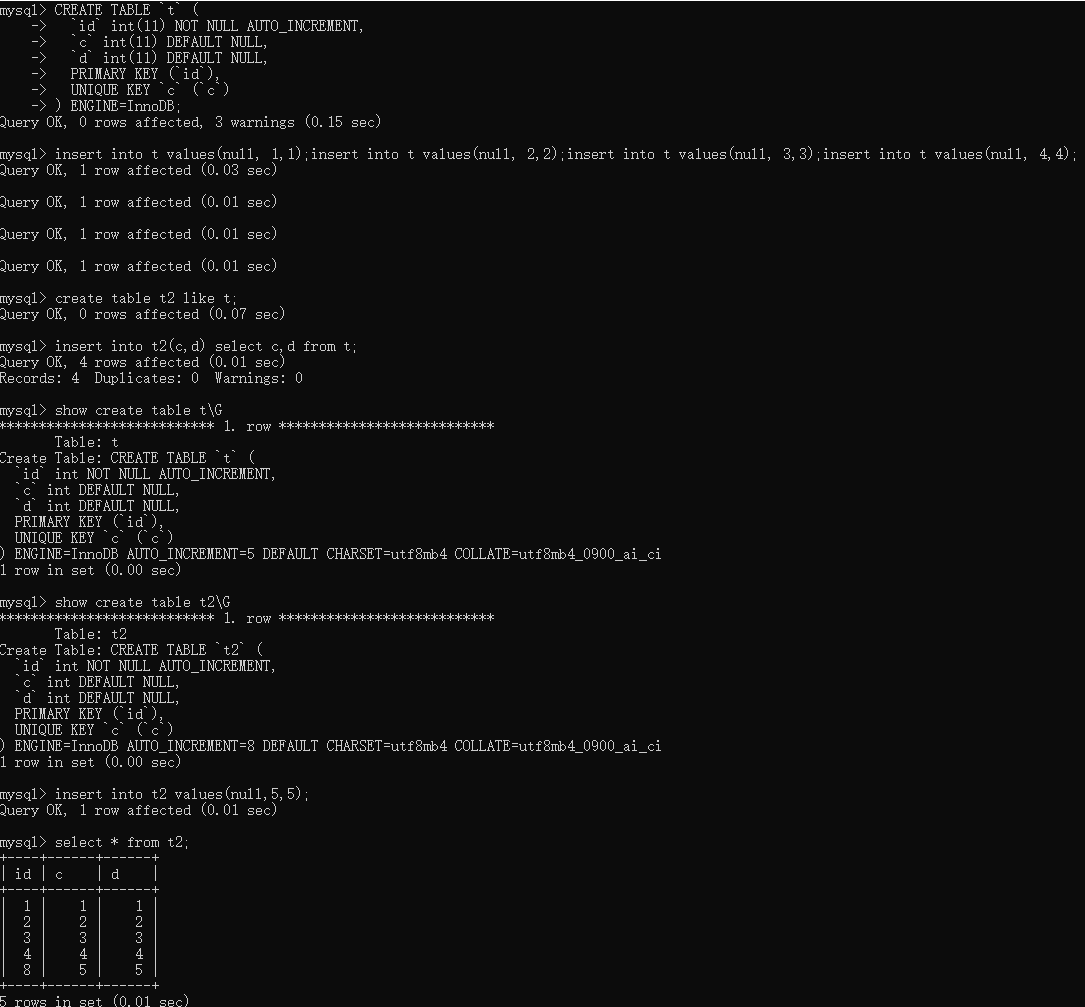
由于这种规则,t2表的批量插入就只用到了 id=1 到 id=4,id=8,而id=5 到id=7就被浪费掉了,因此自增主键的批量申请也会导致自增主键出现不连续的情况。
6、总结
自增主键不能保持连续性
-
唯一键冲突
-
事务回滚
-
自增主键的批量申请
深层次的原因是:不判断自增主键是否已存在和减少加锁的时间范围和粒度,以追求更高的性能,因此自增主键不允许回退,所以自增主键不连续。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号