python 文字识别 之 pytesseract
pytesseract资源
链接:https://pan.baidu.com/s/1eTsqhsY 密码:j0yo
安装时前面一直next就可以了,直到这一步,勾选Math和Chinese,支持计算和中文
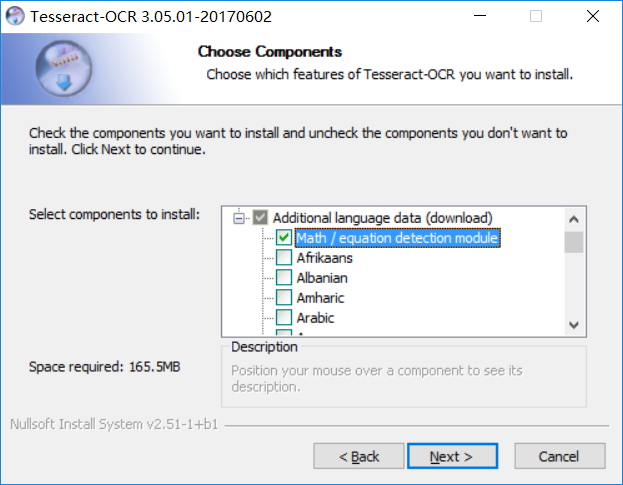

要记住安装的目录
我的是 F:\Program Files (x86)\Tesseract-OCR
然后,
在系统变量中添加一个TESSDATA_PREFIX,变量值还是文件路径
我的是F:\Program Files (x86)\Tesseract-OCR
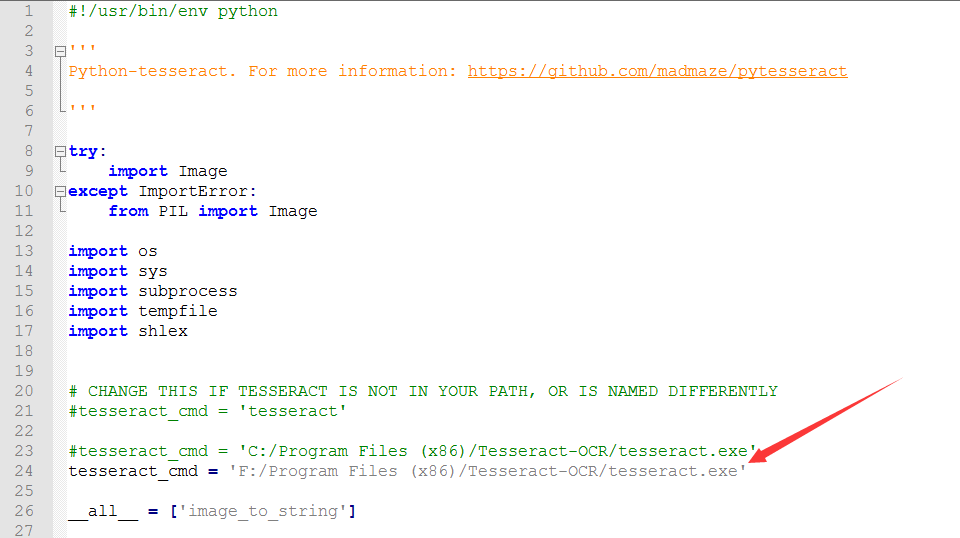
打开Python安装路径:\Python36\Lib\site-packages\pytesseract\pytesseract.py,把路径改为自己的安装路径
运行下面代码
from PIL import Image
import pytesseract
img = Image.open('aaa.png')
text = pytesseract.image_to_string(img,lang='chi_sim')
print (text)
图片:1.png

运行结果

结果会有一点出入,需要对现有模型进行训练才能提高匹配度
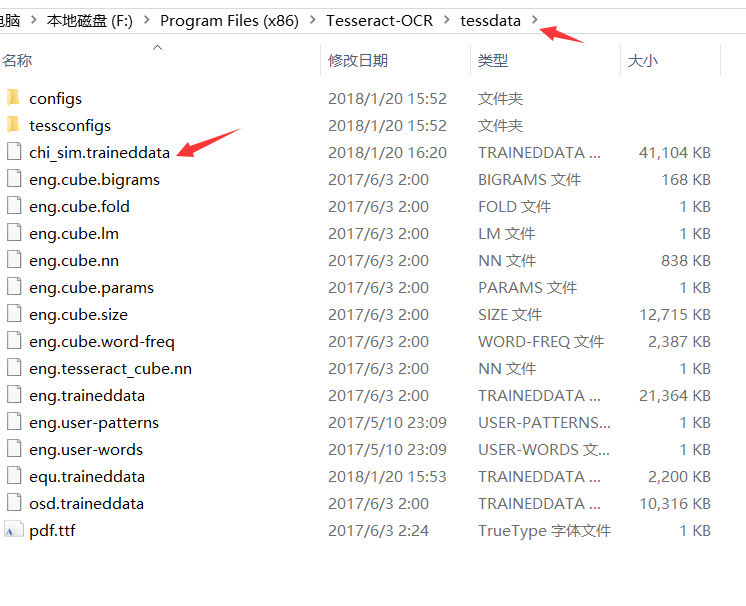
chi_sim.traineddata是中文对应的模型,后面会学习对模型的训练,提供匹配度
关于安装pytesseract的一些链接:
http://blog.csdn.net/cjvs9k/article/details/79044548
http://blog.csdn.net/qiushi_1990/article/details/78041375
http://blog.csdn.net/ztzy520/article/details/53946327
https://www.cnblogs.com/chenbjin/p/4147564.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号