Elasticsearch手记
1. illegal_argument_exception 报错
当我们向elasticsearch中,添加一条数据时(此时,如果索引存在则直接新增或者更新文档,不存在则先创建索引),首先检查该amount字段的映射类型。如上示例中,我们添加第一篇文档时(z1索引不存在),elasticsearch会自动的创建索引,然后为age字段创建映射关系(es就猜此时amount字段的值是什么类型,如果发现是text类型,那么存储该字段的映射类型就是text),此时amount字段的值是text类型,所以,第二条插入数据,amount的值也是text类型,而不是我们看到的long类型。我们可以查看一下该索引的mappings信息:
GET idx_202012/_mapping
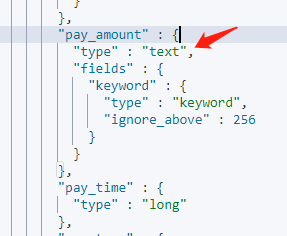
推荐处理方式:
1. 查看原来的mapping
GET idx_202012/_mapping
2. 创建新index
PUT idx_202012_v2
3. 预先定义类型
POST youi_idx_202101_v2/_mapping?pretty
{
"properties": {
"amount": {
"type": "long",
"store": "true"
}
}
}
4.数据同步
POST _reindex
{
"source": {
"index": "idx_202101"
},
"dest": {
"index": "idx_202101_v2"
}
}
5. 删除旧索引
DELETE idx_202101
6.设置别名
POST /_aliases
{
"actions": [
{"add": {"index": "idx_202101", "alias": "idx_202101_v2"}}
]
}
我用的: https://www.cnblogs.com/blogabc/p/12664274.html
https://www.cnblogs.com/royfans/p/11436395.html
其他处理方式:
5.x后对排序,聚合这些操作用单独的数据结构(fielddata)缓存到内存里了,需要单独开启,官方解释在此fielddata
简单来说就是在聚合前执行如下操作
PUT idx_202012/_mapping/
{
"amount": {
"interests": {
"type": "text",
"fielddata": true
}
}
}
参考: https://blog.csdn.net/u011403655/article/details/71107415
Elasticsearch - 常见错误:https://www.cnblogs.com/Neeo/articles/10771885.html#illegal_argument_exception
1. read_only_allow_delete" : "true"
2. illegal_argument_exception
3. Result window is too large
elasticsearch-mapping字段类型:https://blog.csdn.net/gongpulin/article/details/78570246

 浙公网安备 33010602011771号
浙公网安备 33010602011771号