

数据采集 第二次大作业
#第二次大作业
1.作业1
1.1内容
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
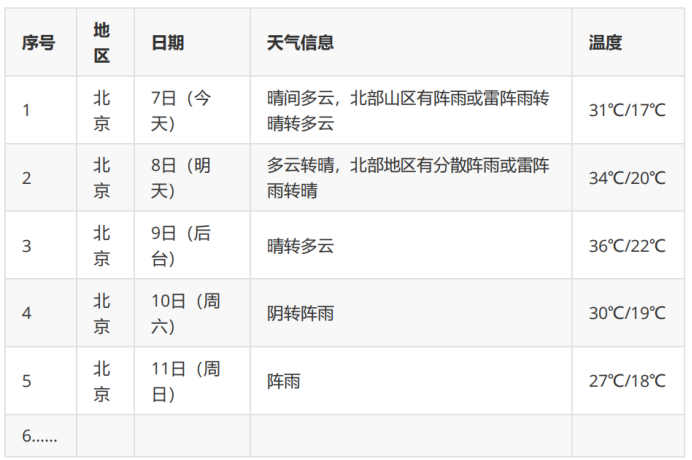
1.2代码&结果
- 关于不同城市的转换:通过更改url中的城市代码。
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml" # 获得相应城市的链接 - 通过“检查”,并分析html信息,发现天气信息都在li标签下,因此使用BeautifulSoup容易查找。
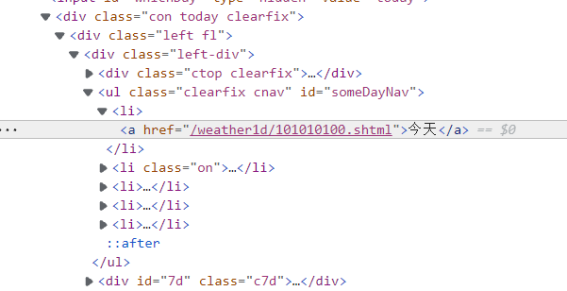
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li") # 找到li元素
for li in lis:
try:
date = li.select('h1')[0].text # 日期
weather = li.select('p[class="wea"]')[0].text # 天气
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text # 温度
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
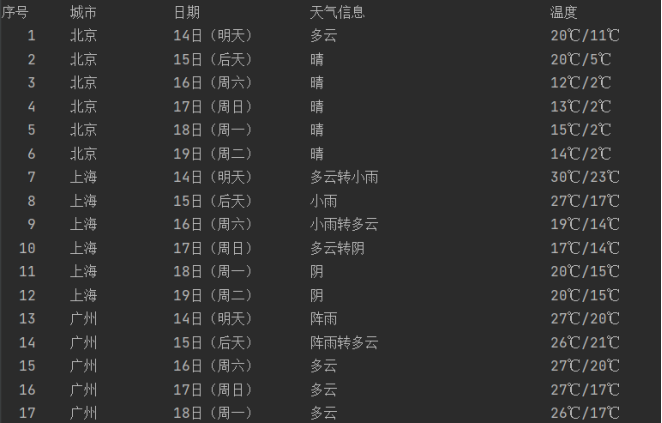
- 存入数据库
self.db.insert(city, date, weather, temp) - 打印数据库内容
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
i=1
print("{:4}\t{:10}\t{:14}\t{:24}\t{:16}".format("序号","城市", "日期", "天气信息", "温度")) # 指定格式输出
for row in rows:
print("{:4}\t{:10}\t{:10}\t{:24}\t{:16}".format(i,row[0], row[1], row[2], row[3]))
i+=1
1.3心得
- 学习了sqlite3中,数据库里创建表,插入表,读取表内容的操作,语言比较简单易学。
2.作业2
2.1内容
用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。
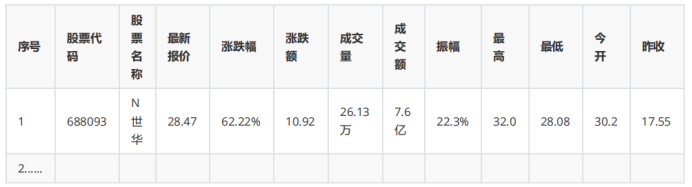
2.2代码&结果
- F12进行抓包,在preview中可以预览内容。

- 在headers查看Request URL,可以分析出翻页规律,即pn值的改变,以此获得url。


url = "http://29.push2.eastmoney.com/api/qt/clist/get?cb=jQuery1124014848135834337683_1634087839998&pn=" \
+ str(pn) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23" \
"&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152"
- re匹配获得股票信息。
def getStock(data, count):
m = re.findall(r'"data":{(.*)}', data, re.S) # 匹配得到data部分列表
data = m[0][21:-2] # 去除头尾不需要的信息
data = data.split("},") # 按每股分割,得到分割后列表
for item in data:
stock = item[1:].split(",") # 每支股票按涨跌额等信息分割
# 加入到数据库中
stocks.append([count, stock[11][7:-1], stock[13][7:-1], stock[1][5:], stock[2][5:]+"%", stock[3][5:],
stock[4][5:], stock[5][5:], stock[6][5:]+"%", stock[14][6:], stock[15][6:], stock[16][6:], stock[17][6:]])
count += 1
return count
- 最后,通过输出数据库内容查看结果。
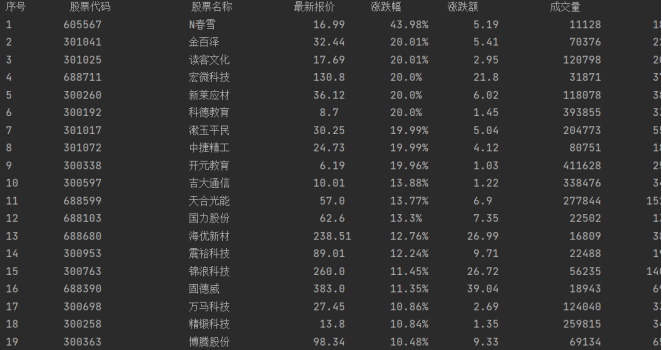
2.3心得
- 学习了通过F12抓包进行返回值的分析,以此来探寻翻页等规律十分方便,同时也可以根据情况进行参数的删减,如此次url中最后一部分“&_=1634087839999”即可删除。
- 通过抓包得到的数据十分有规律性,但以上代码通过re匹配后再利用字符串的处理没有发挥这个优势,可以探索新的提取信息的方法。
3.作业3
3.1内容
爬取中国大学2021主榜( https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。

3.2代码&结果
- 通过F12调试分析,发现数据十分有规律性。
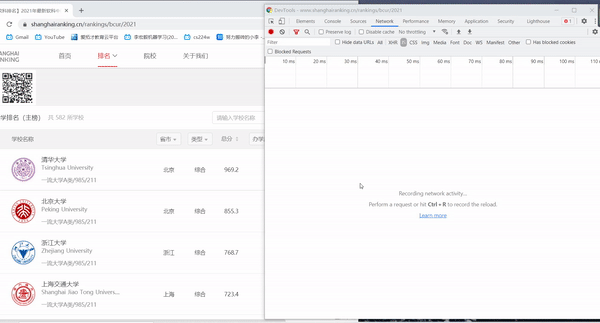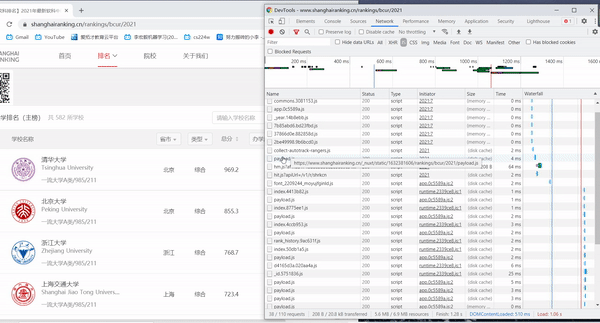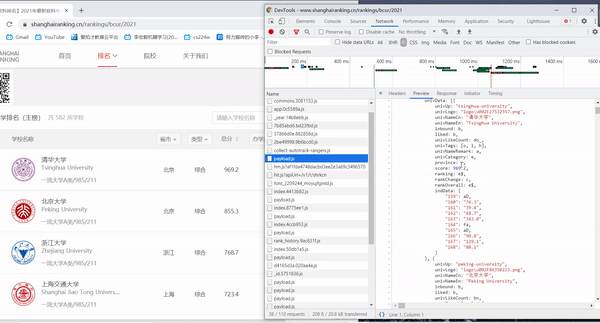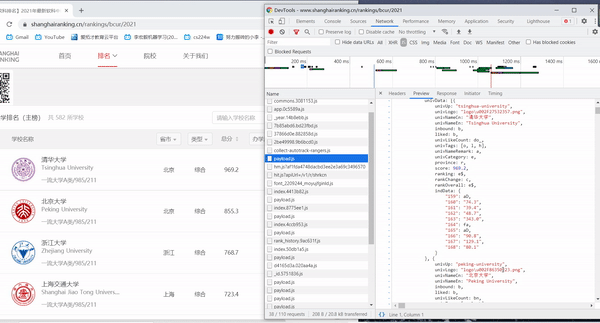
- 需要注意的是,获取到的score可能不能表示数值,需要进行处理,将这些地方的socre置为null。
def isNum(s): # 判断是否为数字
try:
float(s)
return True
except ValueError:
pass
return False
def fillUlist(data, db):
try:
name = re.findall(r'univNameCn:"(.*?)"', data, re.S) # 得到各个学校的名称
score = re.findall(r'score:(.*?),', data, re.S) # 得到各校得分信息
for i in range(len(score)):
if isNum(score[i])==False: # 将得到的非数字得分填充为Null
score[i] = "null"
for i in range(len(name)):
db.insert(str(i+1), name[i], score[i])
except Exception as err:
print(err)
- 最后,通过输出数据库信息查看结果。
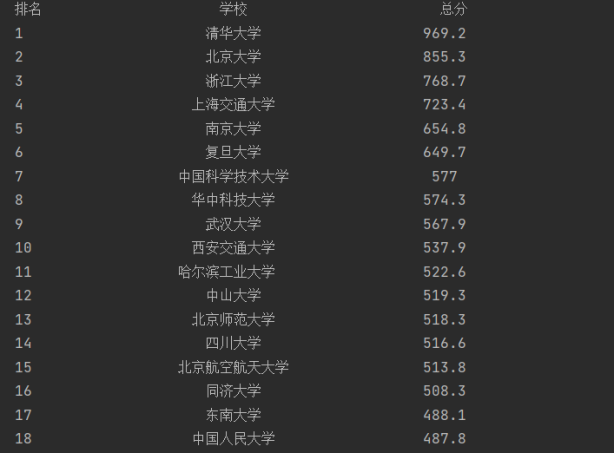

3.3心得
- 本题匹配方法利用了抓包数据的规律性,比上一题写法更简单、有效。
- 本题要求爬取所有信息,根据抓包方法,不需要翻页、不需要再探索翻页规律,十分简便。
第二次大作业代码https://gitee.com/cxqi/crawl_project/tree/master/%E5%AE%9E%E9%AA%8C2
