

数据采集第一次作业
第一次作业
1.作业1
1.1内容
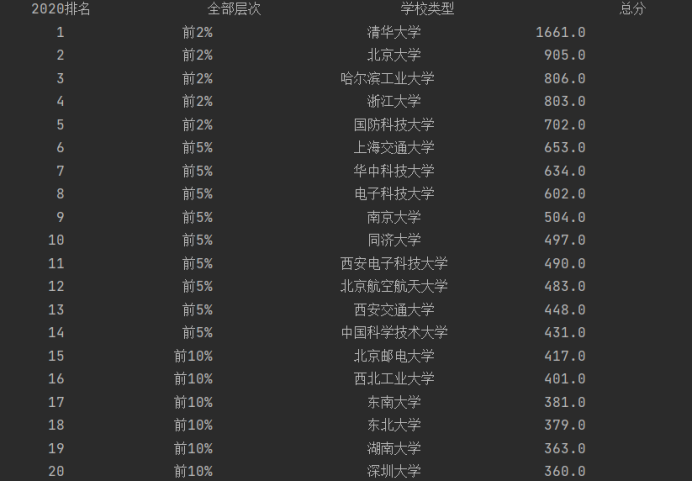
–用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。输出信息:

1.2代码&结果
在分析爬取到的html数据之后,找到所需信息的标签,根据正则表达式匹配即可得到结果:
import urllib.request
import re
url = 'https://www.shanghairanking.cn/rankings/bcsr/2020/0812'
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}
req = urllib.request.Request(url, headers=headers) # 实例化Request得到Request对象,用来包装HTTP请求
data = urllib.request.urlopen(req) # 获取页面
data = data.read().decode() # 获得解码后的页面信息,使用re正则表达式必须为str类型
tplt = "{0:^15}\t{1:^15}\t{2:{4}^15}\t{3:^15}" # tplt用以控制输出字符串的格式
print(tplt.format("2020排名", "全部层次", "学校类型", "总分", chr(12288)))
rank = re.findall(r'<div class="ranking" data-v-68e330ae>(.*?)</div>', data, re.S) # 得到的各校排名的列表
names = re.findall(r'<div class="link-container" data-v-b80b4d60>(.*?)</div>', data, re.M | re.S) # 得到各个学校的名称
school = re.findall(r'<td data-v-68e330ae.*?>(.*?)</td>', data, re.M | re.S) # 得到各校层次信息与得分信息
name = [] # 用来保存最终的学校名称
layer = [] #用来保存最终的学校层次
score = [] # 用来保存最终的学校分数
# 对获取到的各个列表内的信息做处理,去除一些不必要的字符串,将其添加到上面的列表
for i in range(0, len(rank)):
rank[i] = rank[i].strip()
for i in names:
i = re.findall(r'>(.*?)</a>', i)
name.append(i[0])
for index in range(0, len(school)):
if(index % 3 == 1):
Layer = school[index].replace('<!---->', '').strip()
layer.append(Layer)
elif(index % 3 == 2):
Score = school[index].strip()
score.append(Score)
for j in range(0, len(rank)):
print(tplt.format(rank[j], layer[j], name[j], score[j], chr(12288))) # 按格式输出爬取到的学校排名信息等
except Exception as err:
print(err)
1.3心得
- 此网站网页信息格式较为复杂,需要仔细分析,上述某些匹配写法得到的不一定是一个信息的列表,可能是多个信息混合在一起,还需要进一步区分。
- 使用re.findall()时,注意添加re.S,它表示“.”的作用扩展到整个字符串,包括“\n”,否则匹配到的列表值为空。
- 需要对输出进行格式化约束,特别是输出中文字符时,在长度富余的地方用中文空格进行填充,否则会出现不对齐问题。
2.作业2
2.1内容
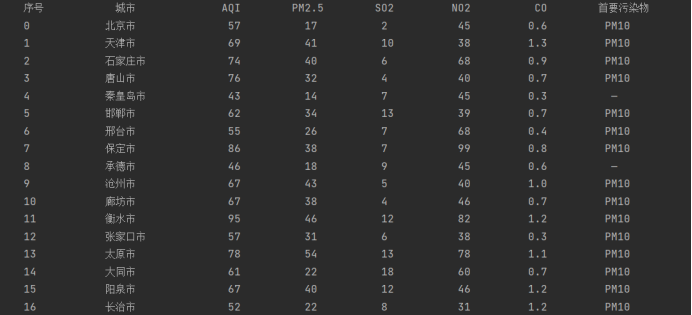
用requests和Beautiful Soup库方法设计爬取 https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。输出信息:

2.2代码&结果
可以观察到一个城市对应一个'tr'标签,一个'tr'标签下的每个'td'标签对应所需的信息,根据观察结果编写代码:
import requests
from bs4 import BeautifulSoup
def getHTMLText(url): # 获得html内容
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
return r.text
except:
return ""
def fillUnivList(wlist, html):
soup = BeautifulSoup(html, "html.parser") # 解析html内容
try:
cities = soup.select("tr") # 一个城市对应一个'tr'标签,cities为得到的各城市信息列表
for city in cities:
l = city.select("td") # 每个指标值对应一个'td'标签
name = l[0].text # 城市名
Aqi = l[1].text # AQI值
Pm2_5 = l[2].text # PM2.5值
So2 = l[4].text # SO2值
No2 = l[5].text # NO2值
Co = l[6].text # CO值
prime = l[8].text.strip() # 首要污染物
wlist.append([name, Aqi, Pm2_5, So2, No2, Co, prime])
except Exception as err:
print(err)
def printUnivList(wlist):
tplt = "{0:^10}\t{1:{8}^10}\t{2:^10}\t{3:^10}\t{4:^10}\t{5:^10}\t{6:^10}\t{7:^10}" # 控制字符串输出格式
print(tplt.format("序号", "城市", "AQI", "PM2.5", "SO2", "NO2", "CO", "首要污染物", chr(12288)))
for i in range(0, len(wlist)):
w = wlist[i]
print(tplt.format(str(i), w[0], w[1], w[2], w[3], w[4], w[5], w[6], chr(12288))) # 用相应格式控制信息输出
wifo = [] # 保存每个城市的相关空气质量信息
url = 'https://datacenter.mee.gov.cn/aqiweb2/'
html = getHTMLText(url) # 获得url相应网页的html内容
fillUnivList(wifo, html) # 将城市相关信息填入wifo列表
printUnivList(wifo) # 输出信息
2.3心得
- 此网站标签格式简单,易于分析,在完成作业过程中由于报错,让我特别注意到在使用正则表达式也需进行异常处理。
3.作业3
3.1内容
要求:使用urllib和requests和re爬取一个给定网页(https://news.fzu.edu.cn/) 爬取该网站下的所有图片。输出信息:将自选网页内的所有jpg文件保存在一个文件夹中。
3.2代码&结果
检查网页,发现所有的图片链接都在img标签下,因此写起正则匹配较为方便:
- 使用urllib库
import urllib
import re
url = 'http://news.fzu.edu.cn/'
count = 1
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read().decode() # 获得网页信息
photos = re.findall(r'<img(.*?)>', data, re.S | re.M) # 获得图片链接所在的字符串
for i in range(0, len(photos)):
photos[i] = str(re.findall(r'src="/(.*?)"', photos[i])[0]) # 在字符串中匹配获得图片的链接
photo_url = url + photos[i] # 将图片链接与当前网页链接拼接,得到可访问的图片网页链接
try:
req = urllib.request.Request(photo_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read() # 进行图片数据读取
# 将图片写入文件夹下
with open('E:/数据采集与融合/py/new_fzu_photo/%d.jpg' % count, 'wb') as f:
f.write(data)
count += 1
except Exception as err:
print(err)
except Exception as err:
print(err)
- 使用requests库
import requests
import re
def getText(url): # 获取html信息,返回为str类型
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def getPhoto(url): # 读取图片时,返回为bytes类型,便于后续写入文件
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
return r.content
except:
return ""
def loadPhoto(url, data):
try:
count = 1
photos = re.findall(r'<img(.*?)>', data, re.S | re.M) # 匹配得到图片链接所在字符串
for i in range(0, len(photos)):
photos[i] = str(re.findall(r'src="/(.*?)"', photos[i])[0]) # 在字符串中匹配获得图片的链接
photo_url = url + photos[i] # 将图片链接与当前网页链接拼接,得到可访问的图片网页链接
try:
data = getPhoto(photo_url) # 读取图片数据
# 将图片写入文件夹
with open('E:/数据采集与融合/py/new_fzu_photo/%d.jpg' % count, 'wb') as f:
f.write(data)
count += 1
except Exception as err:
print(err)
except Exception as err:
print(err)
url = 'http://news.fzu.edu.cn/'
data = getText(url)
loadPhoto(url, data)

3.3心得
- urllib和requests在正则匹配上完全相同,此处只是在访问网页和读取数据上有所不同。
- re.findall()返回的是列表,在获取单张图片链接时要特别注意将其取出,如str(re.findall(r'src="/(.*?)"', photos[i])[0])。
- urllib.request.urlopen(req).read()返回bytes类型值,在正则匹配时需要decode,写图片时正好合适;而requests方法读取数据时,可以用返回r.text进行正则匹配,返回r.content进行图片读写,也十分方便。
