

Pytorch-Bert预训练模型的使用(调用transformers)
transformers(以前称为pytorch-transformers和pytorch-pretrained-bert)提供用于自然语言理解(NLU)和自然语言生成(NLG)的BERT家族通用结构(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet等),包含超过32种、涵盖100多种语言的预训练模型。
首先下载transformers包,pip install transformers
其次手动下载模型(直接from transformers import BertModel会从官方的s3数据库下载模型配置、参数等信息,在国内并不可用),下载bert-base-chinese的config.josn,vocab.txt,pytorch_model.bin三个文件后,放在bert-base-chinese文件夹下,此例中该文件夹放在E:\transformer_file\下。
提前导包:

1 import numpy as np 2 import torch 3 from transformers import BertTokenizer, BertConfig, BertForMaskedLM, BertForNextSentencePrediction 4 from transformers import BertModel 5 6 model_name = 'bert-base-chinese' 7 MODEL_PATH = 'E:/transformer_file/bert-base-chinese/' 8 9 # a.通过词典导入分词器 10 tokenizer = BertTokenizer.from_pretrained(model_name) 11 # b. 导入配置文件 12 model_config = BertConfig.from_pretrained(model_name) 13 # 修改配置 14 model_config.output_hidden_states = True 15 model_config.output_attentions = True 16 # 通过配置和路径导入模型 17 bert_model = BertModel.from_pretrained(MODEL_PATH, config = model_config)
利用分词器进行编码:
- encode仅返回input_ids
- encode_plus返回所有编码信息
- ‘input_ids’:是单词在词典中的编码
- ‘token_type_ids’:区分两个句子的编码(上句全为0,下句全为1)
- ‘attention_mask’:指定对哪些词进行self-Attention操作
1 print(tokenizer.encode('我不喜欢你')) #[101, 2769, 679, 1599, 3614, 872, 102] 2 sen_code = tokenizer.encode_plus('我不喜欢这世界','我只喜欢你') 3 print(sen_code) 4 # {'input_ids': [101, 2769, 679, 1599, 3614, 6821, 686, 4518, 102, 2769, 1372, 1599, 3614, 872, 102], 5 # 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1], 6 # 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
将input_ids转化回token:
1 print(tokenizer.convert_ids_to_tokens(sen_code['input_ids'])) 2 #['[CLS]', '我', '不', '喜', '欢', '这', '世', '界', '[SEP]', '我', '只', '喜', '欢', '你', '[SEP]']
将分词输入模型,得到编码:
1 #对编码进行转换,以便输入Tensor 2 tokens_tensor = torch.tensor([sen_code['input_ids']]) # 添加batch维度并转化为tensor 3 segments_tensors = torch.tensor([sen_code['token_type_ids']]) 4 5 bert_model.eval() 6 7 #进行编码 8 with torch.no_grad(): 9 10 outputs = bert_model(tokens_tensor, token_type_ids=segments_tensors) 11 encoded_layers = outputs #outputs类型为tuples
Bert最终输出的结果维度为:sequence_output, pooled_output, (hidden_states), (attentions)
以输入序列为14为例:
- sequence_output:torch.Size([1, 14, 768]) 输出序列
- pooled_output:torch.Size([1, 768]) 对输出序列进行pool操作的结果
- (hidden_states):tuple, 13*torch.Size([1, 14, 768]) 隐藏层状态(包括Embedding层),取决于model_config中的output_hidden_states
- (attentions):tuple, 12*torch.Size([1, 12, 14, 14]) 注意力层,取决于model_config中的output_attentions
1.遮蔽语言模型
BERT以训练遮蔽语言模型(Masked Language Model)作为预训练目标,具体来说就是把输入的语句中的字词随机用 [MASK] 标签覆盖,然后训练模型结合被覆盖的词的左侧和右侧上下文进行预测。可以看出,BERT 的做法与从左向右语言模型只通过左侧语句预测下一个词的做法相比,遮蔽语言模型能够生成同时融合了左、右上下文的语言表示。这种做法能够使 BERT 学到字词更完整的语义表示。
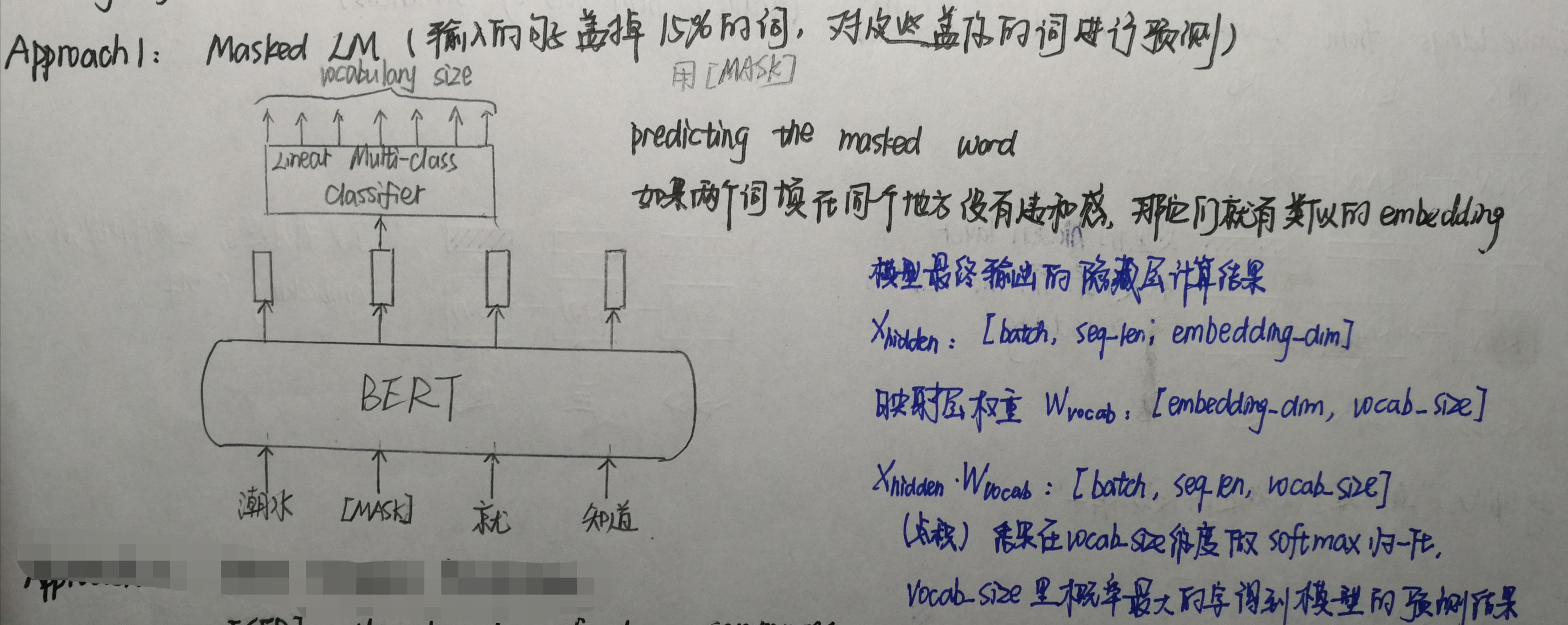
1 model_name = 'bert-base-chinese' #指定需下载的预训练模型参数 2 3 #任务一:遮蔽语言模型 4 # BERT 在预训练中引入了 [CLS] 和 [SEP] 标记句子的开头和结尾 5 samples = ['[CLS] 中国的首都是哪里? [SEP] 北京是 [MASK] 国的首都。 [SEP]'] # 准备输入模型的语句 6 7 tokenizer = BertTokenizer.from_pretrained(model_name) 8 tokenized_text = [tokenizer.tokenize(i) for i in samples] #将句子分割成一个个token,即一个个汉字和分隔符 9 input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text] #把每个token转换成对应的索引 10 input_ids = torch.LongTensor(input_ids) 11 12 # 读取预训练模型 13 model = BertForMaskedLM.from_pretrained(model_name, cache_dir="E:/transformer_file/") 14 model.eval() 15 16 outputs = model(input_ids) 17 prediction_scores = outputs[0] #prediction_scores.shape=torch.Size([1, 21, 21128]) 18 sample = prediction_scores[0].detach().numpy() #sample.shape = (21, 21128) 19 20 pred = np.argmax(sample, axis=1) #21为序列长度,pred代表每个位置最大概率的字符索引 21 print(tokenizer.convert_ids_to_tokens(pred)[14]) #被标记的[MASK]是第14个位置
中
2.句子预测任务
预训练 BERT 时除了 MLM 预训练策略,还要进行预测下一个句子的任务。句子预测任务基于理解两个句子间的关系,这种关系无法直接被 Masked Language Model 捕捉到。

1 sen_code1 = tokenizer.encode_plus('今天天气怎么样','今天天气很好') 2 sen_code2 = tokenizer.encode_plus('小明今年几岁了','我不喜欢学习') 3 4 tokens_tensor = torch.tensor([sen_code1['input_ids'], sen_code2['input_ids']]) 5 6 #读取预训练模型 7 model = BertForNextSentencePrediction.from_pretrained(model_name, cache_dir="E:/transformer_file/") 8 model.eval() 9 10 outputs = model(tokens_tensor) 11 seq_relationship_scores = outputs[0] #seq_relationship_scores.shape= torch.Size([2, 2]) 12 sample = seq_relationship_scores.detach().numpy() #sample.shape = (2, 2) 13 14 pred = np.argmax(sample, axis=1) 15 print(pred)
[0 0] 0表示是上下句,1表示不是上下句(第二句明明不是前后句关系,不知道为什么会输出0。)
前面三行代码等价于:
1 samples = ["[CLS]今天天气怎么样[SEP]今天天气很好[SEP]", "[CLS]小明今年几岁了[SEP]我不喜欢学习[SEP]"] 2 tokenizer = BertTokenizer.from_pretrained(model_name) 3 tokenized_text = [tokenizer.tokenize(i) for i in samples] 4 input_ids = [tokenizer.convert_tokens_to_ids(i) for i in tokenized_text] 5 tokens_tensor = torch.LongTensor(input_ids)
3.问答任务

任务输入:问题句“里昂是谁”,答案所在文章“里昂是一个杀手”
任务输出:一对整数,表示答案在文本中的开头和结束位置
1 model_name = 'bert-base-chinese' 2 3 # 通过词典导入分词器 4 tokenizer = BertTokenizer.from_pretrained(model_name) 5 # 导入配置文件 6 model_config = BertConfig.from_pretrained(model_name) 7 # 最终有两个输出,初始位置和结束位置 8 model_config.num_labels = 2 9 10 # 根据bert的model_config新建BertForQuestionAnswering 11 model = BertForQuestionAnswering(model_config) 12 model.eval() 13 14 question, text = "里昂是谁", "里昂是一个杀手" 15 16 sen_code = tokenizer.encode_plus(question,text) 17 18 tokens_tensor = torch.tensor([sen_code['input_ids']]) 19 segments_tensor = torch.tensor([sen_code['token_type_ids']]) 20 21 start_pos, end_pos = model(tokens_tensor, segments_tensor) 22 # 进行逆编码,得到原始的token 23 all_tokens = tokenizer.convert_ids_to_tokens(sen_code['input_ids']) 24 print(all_tokens) #['[CLS]', '里', '昂', '是', '谁', '[SEP]', '里', '昂', '是', '一', '个', '杀', '手', '[SEP]'] 25 26 # 对输出的答案进行解码的过程 27 answer = ' '.join(all_tokens[torch.argmax(start_pos) : torch.argmax(end_pos)+1]) 28 29 # 每次执行的结果不一致,这里因为没有经过微调,所以效果不是很好,输出结果不佳,下面的输出是其中的一种。 30 print(answer) #一 个 杀 手 [SEP]


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
2017-08-26 jQuery学习(八)——使用JQ插件validation进行表单校验