Pytorch-textCNN(不调用torchtext与调用torchtext)
语料链接:https://pan.baidu.com/s/1rIv4eWPkornhZj92A8r6oQ
提取码:haor
语料中分为pos.txt和neg.txt,每一行是一个完整的句子,句子之间用空格分开,句子平均长度为20(提前代码计算,设定超参数)。
提前导包:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from collections import Counter 4 import tqdm 5 import random 6 import torch 7 from torch import nn, optim 8 9 10 random.seed(53113) 11 np.random.seed(53113) 12 torch.manual_seed(53113) 13 14 # 设定一些超参数 15 SENTENCE_LIMIT_SIZE = 20 # 句子平均长度 16 BATCH_SIZE = 128 # the batch size 每轮迭代1个batch的数量 17 LEARNING_RATE = 1e-3 # the initial learning rate 学习率 18 EMBEDDING_SIZE = 200 #词向量维度
1.加载数据
1 def read(filename): 2 with open(filename, encoding='mac_roman') as f: 3 text = f.read().lower() 4 return text 5 6 pos_text, neg_text = read("corpurs/pos.txt"), read("corpurs/neg.txt") 7 total_text = pos_text +'\n'+ neg_text #合并文本
2.构造词典和映射
构造词典的步骤一般就是对文本进行分词再进行去重。当我们对文本的单词进行统计后,会发现有很多出现频次仅为1次的单词,这类单词会增加词典容量并且会给文本处理带来一定的噪声。因此在构造词典过程中仅保留在语料中出现频次大于1的单词。其中<pad>和<unk>是两个初始化的token,<pad>用来做句子填补,<unk>用来替代语料中未出现过的单词。
1 text = total_text.split() 2 vocab = [w for w, f in Counter(text).most_common() if f>1] 3 vocab = ['<pad>', '<unk>'] + vocab 4 5 token_to_word = {i:word for i, word in enumerate(vocab)} #编码到单词 6 word_to_token = {word:i for i, word in token_to_word.items()} #单词到编码 7 8 VOCAB_SIZE = len(token_to_word) #词汇表单词数10382
3.转换文本
根据映射表将原始文本转换为机器可识别的编码。另外为了保证句子有相同的长度,需要对句子长度进行处理,这里设置20作为句子的标准长度:
- 对于超过20个单词的句子进行截断;
- 对于不足20个单词的句子进行PAD补全;
1 def convert_text_to_token(sentence, word_to_token_map=word_to_token, limit_size=SENTENCE_LIMIT_SIZE): 2 """ 3 根据单词-编码映射表将单个句子转化为token 4 5 @param sentence: 句子,str类型 6 @param word_to_token_map: 单词到编码的映射 7 @param limit_size: 句子最大长度。超过该长度的句子进行截断,不足的句子进行pad补全 8 9 return: 句子转换为token后的列表 10 """ 11 # 获取unknown单词和pad的token 12 unk_id = word_to_token_map["<unk>"] 13 pad_id = word_to_token_map["<pad>"] 14 15 # 对句子进行token转换,对于未在词典中出现过的词用unk的token填充 16 tokens = [word_to_token_map.get(word, unk_id) for word in sentence.lower().split()] 17 18 if len(tokens) < limit_size: #补齐 19 tokens.extend([0] * (limit_size - len(tokens))) 20 else: #截断 21 tokens = tokens[:limit_size] 22 23 return tokens
接下来对pos文本和neg文本进行转换:
1 pos_tokens = [convert_text_to_token(sentence) for sentence in pos_text.split('\n')] 2 neg_tokens = [convert_text_to_token(sentence) for sentence in neg_text.split('\n')] 3 4 #为了方便处理数据,转化成numpy格式 5 pos_tokens = np.array(pos_tokens) 6 neg_tokens = np.array(neg_tokens) 7 total_tokens = np.concatenate((pos_tokens, neg_tokens), axis=0) #(10662, 20) 8 9 pos_targets = np.ones((pos_tokens.shape[0])) 10 neg_targets = np.zeros((neg_tokens.shape[0])) 11 total_targets = np.concatenate((pos_targets, neg_targets), axis=0).reshape(-1, 1) #(10662, 1)
4.加载预训练的词向量
4.1法一:gensim加载Glove向量
1 def load_embedding_model(): 2 """ Load GloVe Vectors 3 Return: 4 wv_from_bin: All 400000 embeddings, each lengh 200 5 """ 6 import gensim.downloader as api 7 wv_from_bin = api.load("glove-wiki-gigaword-200") 8 print("Loaded vocab size %i" % len(wv_from_bin.vocab.keys())) 9 return wv_from_bin 10 11 model = load_embedding_model()
4.2法二:gensim加载Word2Vec向量
1 from gensim.test.utils import datapath, get_tmpfile 2 from gensim.models import KeyedVectors 3 from gensim.scripts.glove2word2vec import glove2word2vec 4 5 6 glove_file = datapath('F:/python_DemoCode/PytorchEx/.vector_cache/glove.6B.100d.txt') #输入文件 7 word2vec_glove_file = get_tmpfile("F:/python_DemoCode/PytorchEx/.vector_cache/glove.6B.100d.word2vec.txt") #输出文件 8 glove2word2vec(glove_file, word2vec_glove_file) #转换 9 10 model = KeyedVectors.load_word2vec_format(word2vec_glove_file) #加载转化后的文件
基于上面某一种预训练方法来构建自己的word embeddings
1 static_embeddings = np.zeros([VOCAB_SIZE, EMBEDDING_SIZE]) 2 for word, token in tqdm.tqdm(word_to_token.items()): 3 #用词向量填充 4 if word in model.vocab.keys(): 5 static_embeddings[token, :] = model[word] 6 elif word == '<pad>': #如果是空白,用零向量填充 7 static_embeddings[token, :] = np.zeros(EMBEDDING_SIZE) 8 else: #如果没有对应的词向量,则用随机数填充 9 static_embeddings[token, :] = 0.2 * np.random.random(EMBEDDING_SIZE) - 0.1 10 11 print(static_embeddings.shape) #(10382, 200) 即(vocab_size,embedding_dim)
4.划分数据集
1 from sklearn.model_selection import train_test_split 2 X_train,X_test,y_train,y_test=train_test_split(total_tokens, total_targets, test_size=0.2) #会打乱顺序的 3 print(X_train.shape, y_train.shape) #(8529, 20) (8529, 1)
5.生成batch
1 def get_batch(x, y, batch_size=BATCH_SIZE, shuffle=True): 2 assert x.shape[0] == y.shape[0], print("error shape!") 3 4 if shuffle: 5 shuffled_index = np.random.permutation(range(x.shape[0])) 6 x = x[shuffled_index] 7 y = y[shuffled_index] 8 9 n_batches = int(x.shape[0] / batch_size) #统计共几个完整的batch 10 11 for i in range(n_batches - 1): 12 x_batch = x[i*batch_size: (i+1)*batch_size] 13 y_batch = y[i*batch_size: (i+1)*batch_size] 14 15 yield x_batch, y_batch
6.CNN模型
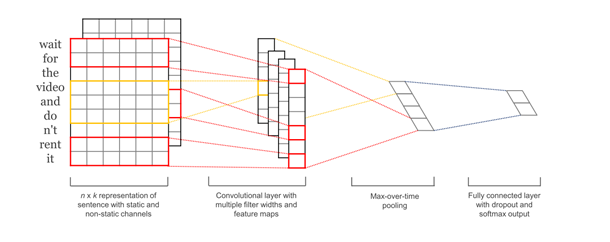
输入句子序列后,经过embedding,获得每个单词的词向量(此例中词向量维度为200,而图中为6),那我们就得到一个seq_len* embedding_dim的矩阵(此例中seq_len是指句子平均长度20)。在这里我们可以将它看做是channel=1,height=seq_len,width=embedding_dim的一张图片,然后就可以用filter去做卷积操作。
由于我们采用了多种filter(filter size=3, 4, 5),因此对于卷积池化操作要分filter处理。对于每个filter,先经过卷积操作得到conv(卷积操作的目的是在height方向滑动来捕捉词与词之间的局部关系,得到多个列向量),再经过relu函数激活后进行池化,得到max_pooling(max-pooling操作来提取每个列向量中的最重要的信息)。由于我们每个filter有100个,因此最终经过flatten后我们可以得到100*3=300维向量,用于连接全连接层。
Tip:关于nn.ModuleList
在构造函数__init__中用到list、tuple、dict等对象时,考虑用ModuleList,它被设计用来存储任意数量的nn. module。
1 class TextCNN(nn.Module): #output_size为输出类别(2个类别,0和1),三种kernel,size分别是3,4,5,每种kernel有100个 2 def __init__(self, vocab_size, embedding_dim, output_size, filter_num=100, kernel_lst=(3,4,5), dropout=0.5): 3 super(TextCNN, self).__init__() 4 5 self.embedding = nn.Embedding(vocab_size, embedding_dim) 6 self.convs = nn.ModuleList([ 7 nn.Sequential(nn.Conv2d(1, filter_num, (kernel, embedding_dim)), #1表示channel_num,filter_num即输出数据通道数,卷积核大小为(kernel, embedding_dim) 8 nn.ReLU(), 9 nn.MaxPool2d((SENTENCE_LIMIT_SIZE - kernel + 1, 1))) 10 for kernel in kernel_lst]) 11 self.fc = nn.Linear(filter_num * len(kernel_lst), output_size) 12 self.dropout = nn.Dropout(dropout) 13 14 def forward(self, x): 15 x = self.embedding(x) #[128, 20, 200](batch, seq_len, embedding_dim) 16 x = x.unsqueeze(1) #[128, 1, 20, 200] 即(batch, channel_num, seq_len, embedding_dim) 17 out = [conv(x) for conv in self.convs] 18 19 out = torch.cat(out, dim=1) #[128, 300, 1, 1] 20 out = out.view(x.size(0), -1) #[128, 300] 21 out = self.dropout(out) 22 logit = self.fc(out) #[128, 2] 23 return logit
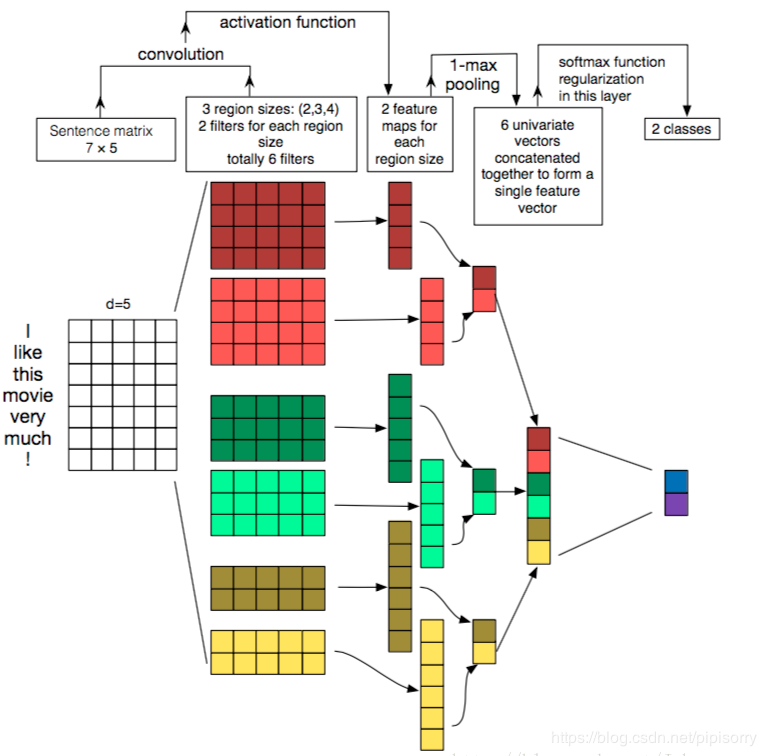
这张图有助于理解整体过程:
调用CNN模型,使用预训练过的embedding来替换随机初始化:
1 cnn = TextCNN(VOCAB_SIZE, 200, 2) 2 cnn.embedding.weight.data.copy_(torch.FloatTensor(static_embeddings))
查看模型:
1 print(cnn)
TextCNN( (embedding): Embedding(10382, 200) (convs): ModuleList( (0): Sequential( (0): Conv2d(1, 100, kernel_size=(3, 200), stride=(1, 1)) (1): ReLU() (2): MaxPool2d(kernel_size=(18, 1), stride=(18, 1), padding=0, dilation=1, ceil_mode=False) ) (1): Sequential( (0): Conv2d(1, 100, kernel_size=(4, 200), stride=(1, 1)) (1): ReLU() (2): MaxPool2d(kernel_size=(17, 1), stride=(17, 1), padding=0, dilation=1, ceil_mode=False) ) (2): Sequential( (0): Conv2d(1, 100, kernel_size=(5, 200), stride=(1, 1)) (1): ReLU() (2): MaxPool2d(kernel_size=(16, 1), stride=(16, 1), padding=0, dilation=1, ceil_mode=False) ) ) (fc): Linear(in_features=300, out_features=2, bias=True) (dropout): Dropout(p=0.5, inplace=False) )
定义优化器和交叉熵损失:
1 optimizer = optim.Adam(cnn.parameters(), lr=LEARNING_RATE) 2 criteon = nn.CrossEntropyLoss()
7.训练函数
首先定义计算准确率的函数
1 def binary_acc(preds, y): 2 correct = torch.eq(preds, y).float() 3 acc = correct.sum() / len(correct) 4 return acc
训练函数
1 def train(cnn, optimizer, criteon): 2 3 avg_loss = [] 4 avg_acc = [] 5 cnn.train() #表示进入训练模式 6 7 8 for x_batch, y_batch in get_batch(X_train, y_train): #遍历每一个batch,x_batch.shape=(128, 20) y_batch.shape=(128, 1) 9 x_batch = torch.LongTensor(x_batch) #要先转成Tensor类型,否则计算交叉熵时会报错 10 y_batch = torch.LongTensor(y_batch) 11 12 y_batch = y_batch.squeeze() #torch.Size([128]) 13 pred = cnn(x_batch) #torch.Size([128, 2]) 14 15 #torch.max(pred, dim=1)[1]得到每一行概率值较大的索引 16 acc = binary_acc(torch.max(pred, dim=1)[1], y_batch) #计算每个batch的准确率 17 avg_acc.append(acc) 18 19 loss = criteon(pred, y_batch) 20 21 optimizer.zero_grad() 22 loss.backward() 23 optimizer.step() 24 25 avg_acc = np.array(avg_acc).mean() 26 return avg_acc
8.评估函数
和训练函数类似,但没有反向传播过程。
1 def evaluate(cnn, criteon): 2 avg_acc = [] 3 cnn.eval() #表示进入测试模式 4 5 with torch.no_grad(): 6 for x_batch, y_batch in get_batch(X_test, y_test): 7 x_batch = torch.LongTensor(x_batch) 8 y_batch = torch.LongTensor(y_batch) 9 10 y_batch = y_batch.squeeze() #torch.Size([128]) 11 pred = cnn(x_batch) #torch.Size([128, 2]) 12 13 acc = binary_acc(torch.max(pred, dim=1)[1], y_batch) 14 avg_acc.append(acc) 15 16 avg_acc = np.array(avg_acc).mean() 17 return avg_acc
迭代训练:
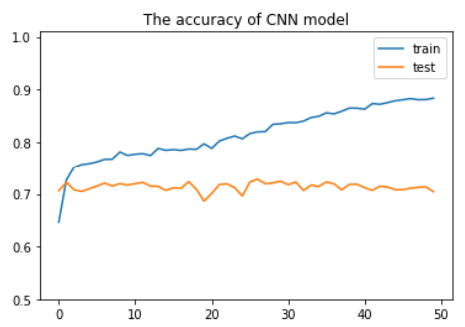
1 cnn_train_acc, cnn_test_acc = [], [] 2 3 for epoch in range(50): 4 5 train_acc = train(cnn, optimizer, criteon) 6 print('epoch={},训练准确率={}'.format(epoch, train_acc)) 7 test_acc = evaluate(cnn, criteon) 8 print("epoch={},测试准确率={}".format(epoch, test_acc)) 9 cnn_train_acc.append(train_acc) 10 cnn_test_acc.append(test_acc) 11 12 plt.plot(cnn_train_acc) 13 plt.plot(cnn_test_acc) 14 plt.ylim(ymin=0.5, ymax=1.01) 15 plt.title("The accuracy of CNN model") 16 plt.legend(["train", "test"])
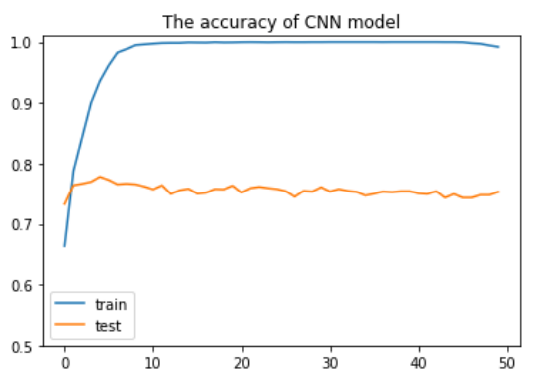
由于没有正则化,出现了过拟合的现象。
为了解决上述问题,可以在定义优化器时加上weight_decay参数。
1 optimizer = optim.Adam(cnn.parameters(), lr=LEARNING_RATE, weight_decay = 0.01)
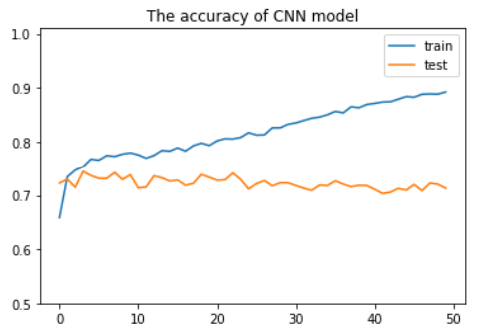
参考链接(这是用TensorFlow实现的):https://zhuanlan.zhihu.com/p/37978321
9.调用torchtext的版本
torchtext基本知识https://blog.csdn.net/qq_40334856/article/details/104208296
1 import numpy as np 2 import torch 3 from torch import nn, optim 4 from torchtext import data 5 import matplotlib.pyplot as plt 6 7 import random 8 9 SEED = 123 10 BATCH_SIZE = 128 11 LEARNING_RATE = 1e-3 #学习率 12 EMBEDDING_SIZE = 200 #词向量维度 13 SENTENCE_LIMIT_SIZE = 20 #句子平均长度 14 15 torch.manual_seed(SEED) 16 17 TEXT = data.Field(tokenize='spacy', lower=True, fix_length=20, batch_first=True) #以空格分开,小写,fix_length指定了每条文本的长度,截断补长 18 LABEL = data.LabelField(dtype=torch.float) 19 20 #get_dataset构造并返回Dataset所需的examples和fields 21 def get_dataset(corpur_path, text_field, label_field, datatype): 22 fields = [('text', text_field), ('label', label_field)] #torchtext文件配对关系 23 examples = [] 24 25 with open(corpur_path, encoding='mac_roman') as f: 26 27 content = f.readline().replace('\n', '') 28 while content: 29 if datatype == 'pos': 30 label = 1 31 else: 32 label = 0 33 examples.append(data.Example.fromlist([content[:-2], label], fields)) 34 content = f.readline().replace('\n', '') 35 36 return examples, fields 37 38 39 #得到构建Dataset所需的examples和fields 40 pos_examples, pos_fields = get_dataset("corpurs//pos.txt", TEXT, LABEL, 'pos') 41 neg_examples, neg_fields = get_dataset("corpurs//neg.txt", TEXT, LABEL, 'neg') 42 all_examples, all_fields = pos_examples+neg_examples, pos_fields+neg_fields 43 44 45 #构建Dataset数据集 46 total_data = data.Dataset(all_examples, all_fields) 47 48 #分割训练集和测试集 49 train_data, test_data = total_data.split(random_state=random.seed(SEED), split_ratio=0.8) 50 51 print('len of train data:', len(train_data)) #8530 52 print('len of test data:', len(test_data)) #2132 53 54 print(train_data.examples[15].text) 55 print(train_data.examples[15].label) 56 #['if', 'you', 'go', 'into', 'the', 'theater', 'expecting', 'a', 'scary', ',', 'action-packed', 'chiller', ',', 'you', 'might', 'soon', 'be', 'looking', 'for', 'a', 'sign', '.', 'an', 'exit', 'sign', ',', 'that', 'is'] 57 #0 58 59 60 #创建vocabulary,把每个单词一一映射到一个数字 61 TEXT.build_vocab(train_data, max_size=10000, vectors='glove.6B.200d') 62 LABEL.build_vocab(train_data) 63 print(len(TEXT.vocab)) #10002 64 print(TEXT.vocab.itos[:12]) #['<unk>', '<pad>', 'the', ',', 'a', 'and', 'of', 'to', '.', 'is', 'in', 'that'] 65 print(TEXT.vocab.stoi['like']) #32 66 print(LABEL.vocab.stoi) #defaultdict(None, {0: 0, 1: 1}) 67 68 #创建iterator 69 train_iterator, test_iterator = data.BucketIterator.splits( 70 (train_data, test_data), 71 batch_size=BATCH_SIZE, 72 sort = False) 73 74 print(next(iter(train_iterator)).text.shape) #torch.Size([128, 20])如果第17行不加batch_first=True,默认False,这边会显示[20, 128] 75 print(next(iter(train_iterator)).label.shape) #torch.Size([128]) 76 77 78 79 class TextCNN(nn.Module): #output_size为输出类别(2个类别,0和1),三种kernel,size分别是3,4,5,每种kernel有100个 80 def __init__(self, vocab_size, embedding_dim, output_size, filter_num=100, kernel_lst=(3,4,5), dropout=0.5): 81 super(TextCNN, self).__init__() 82 83 self.embedding = nn.Embedding(vocab_size, embedding_dim) 84 self.convs = nn.ModuleList([ 85 nn.Sequential(nn.Conv2d(1, filter_num, (kernel, embedding_dim)), 86 nn.ReLU(), 87 nn.MaxPool2d((SENTENCE_LIMIT_SIZE - kernel + 1, 1))) 88 for kernel in kernel_lst]) 89 self.fc = nn.Linear(filter_num * len(kernel_lst), output_size) 90 self.dropout = nn.Dropout(dropout) 91 92 def forward(self, x): 93 x = self.embedding(x) #(batch, word_num, embedding_dim) 94 x = x.unsqueeze(1) #[128, 1, 20, 200] 即(batch, channel_num, word_num, embedding_dim) 95 out = [conv(x) for conv in self.convs] 96 97 out = torch.cat(out, dim=1) # [128, 300, 1, 1] 98 out = out.view(x.size(0), -1) #[128, 300] 99 out = self.dropout(out) 100 logit = self.fc(out) #[128, 2] 101 102 return logit 103 104 105 PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] 106 UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token] 107 108 #使用预训练过的embedding来替换随机初始化 109 cnn = TextCNN(len(TEXT.vocab), 200, 2) 110 111 pretrained_embedding = TEXT.vocab.vectors #torch.Size([10002, 200]) 112 cnn.embedding.weight.data.copy_(pretrained_embedding) 113 cnn.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_SIZE) 114 cnn.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_SIZE) 115 116 117 optimizer = optim.Adam(cnn.parameters(), lr=LEARNING_RATE, weight_decay = 0.01) 118 criteon = nn.CrossEntropyLoss() 119 120 121 #计算准确率 122 def binary_acc(preds, y): 123 124 correct = torch.eq(preds, y).float() 125 acc = correct.sum() / len(correct) 126 return acc 127 128 129 #训练函数 130 def train(cnn, iterator, optimizer, criteon): 131 avg_acc = [] 132 cnn.train() #表示进入训练模式 133 134 for i, batch in enumerate(iterator): 135 pred = cnn(batch.text) #torch.Size([128, 2]) 136 loss = criteon(pred, batch.label.long()) #不加.long()会报错 137 138 #torch.max(pred, dim=1)[1]得到每一行概率值较大的索引 139 acc = binary_acc(torch.max(pred, dim=1)[1], batch.label) #计算每个batch的准确率 140 avg_acc.append(acc) 141 142 optimizer.zero_grad() 143 loss.backward() 144 optimizer.step() 145 146 avg_acc = np.array(avg_acc).mean() 147 return avg_acc 148 149 150 151 #评估函数 152 def evaluate(cnn, iterator, criteon): 153 avg_acc = [] 154 cnn.eval() #表示进入测试模式 155 156 with torch.no_grad(): 157 for i, batch in enumerate(iterator): 158 pred = cnn(batch.text) #torch.Size([128, 2]) 159 acc = binary_acc(torch.max(pred, dim=1)[1], batch.label) 160 avg_acc.append(acc) 161 162 avg_acc = np.array(avg_acc).mean() 163 return avg_acc 164 165 166 167 cnn_train_acc, cnn_test_acc = [], [] 168 169 for epoch in range(50): 170 171 train_acc = train(cnn, train_iterator, optimizer, criteon) 172 print('epoch={},训练准确率={}'.format(epoch, train_acc)) 173 174 test_acc = evaluate(cnn, test_iterator, criteon) 175 print("epoch={},测试准确率={}".format(epoch, test_acc)) 176 177 cnn_train_acc.append(train_acc) 178 cnn_test_acc.append(test_acc) 179 180 plt.plot(cnn_train_acc) 181 plt.plot(cnn_test_acc) 182 plt.ylim(ymin=0.5, ymax=1.01) 183 plt.title("The accuracy of CNN model") 184 plt.legend(["train", "test"])
使用LabelField时,定义label_field = tdata.LabelField(dtype=torch.int, sequential=False, use_vocab=False)
下面label_field.build_vocab(train_data)就可以省略了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号