


Assignment2 word2vec的实现
首先实现word2vec.py中的sigmoid函数,和softmax、负采样、skip-gram的损失函数和导数,接着实现sgd.py中的sgd优化器,最后运行run.py进行展示。
1word2vec.py
1.1sigmoid函数
1 def sigmoid(x): 2 """ 3 Compute the sigmoid function for the input here. 4 Arguments: 5 x -- A scalar or numpy array. 6 Return: 7 s -- sigmoid(x) 8 """ 9 ### YOUR CODE HERE (~1 Line) 10 s = 1 / (1 + np.exp(-x)) 11 ### END YOUR CODE 12 13 return s
1.2naiveSoftmaxLossAndGradient函数
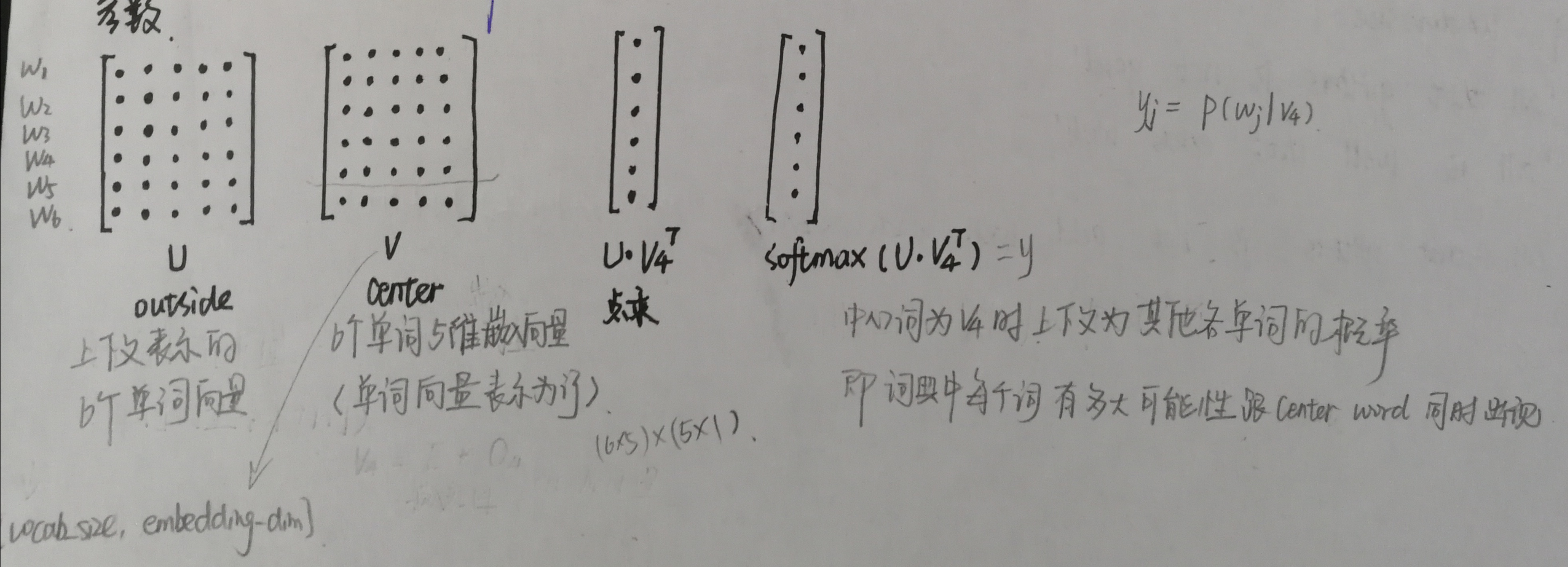

1 def naiveSoftmaxLossAndGradient(centerWordVec, outsideWordIdx, outsideVectors, dataset): 2 """ Naive Softmax loss & gradient function for word2vec models 3 4 Implement the naive softmax loss and gradients between a center word's 5 embedding and an outside word's embedding. This will be the building block 6 for our word2vec models. 7 8 Arguments: 9 centerWordVec -- numpy ndarray, center word's embedding 10 in shape (word vector length, ) 11 (v_c in the pdf handout) 12 outsideWordIdx -- integer, the index of the outside word 13 (o of u_o in the pdf handout) 14 outsideVectors -- outside vectors is 15 in shape (num words in vocab, word vector length) 16 for all words in vocab (U in the pdf handout) 17 dataset -- needed for negative sampling, unused here. 18 19 Return: 20 loss -- naive softmax loss 21 gradCenterVec -- the gradient with respect to the center word vector 22 in shape (word vector length, ) 23 (dJ / dv_c in the pdf handout) 24 gradOutsideVecs -- the gradient with respect to all the outside word vectors 25 in shape (num words in vocab, word vector length) 26 (dJ / dU) 27 """ 28 ### YOUR CODE HERE (~6-8 Lines) 29 30 ### Please use the provided softmax function (imported earlier in this file) 31 ### This numerically stable implementation helps you avoid issues pertaining to integer overflow. 32 y_hat = softmax(np.dot(outsideVectors, centerWordVec.T)) #(num words, 1) 33 34 loss = -np.log(y_hat[outsideWordIdx]) 35 36 y = y_hat.copy() 37 y[outsideWordIdx] -= 1 38 gradCenterVec = np.dot(y, outsideVectors) 39 gradOutsideVecs = np.dot(y[:, np.newaxis], centerWordVec[np.newaxis, :]) 40 ### END YOUR CODE 41 42 return loss, gradCenterVec, gradOutsideVecs
1.3negSamplingLossAndGradient函数
先实现getNegativeSamples函数,选取非outsideWordIdx的K个负样本索引。
1 def getNegativeSamples(outsideWordIdx, dataset, K): 2 """ Samples K indexes which are not the outsideWordIdx """ 3 4 negSampleWordIndices = [None] * K 5 for k in range(K): 6 newidx = dataset.sampleTokenIdx() 7 while newidx == outsideWordIdx: 8 newidx = dataset.sampleTokenIdx() 9 negSampleWordIndices[k] = newidx 10 return negSampleWordIndices
negSamplingLossAndGradient与naiveSoftmaxLossAndGradient不同的是:
- 只选取K个非外围词(负样本,可能有重复词),外加1个正确的外围词,共K+1个输出
- 最后一层使用sigmoid输出,而不是softmax
Tip:反向传播得到的是这K+1个词的梯度,所以需要挨个更新到梯度矩阵中去。

1 def negSamplingLossAndGradient(centerWordVec, outsideWordIdx, outsideVectors, dataset, K=10): 2 """ Negative sampling loss function for word2vec models 3 4 Implement the negative sampling loss and gradients for a centerWordVec 5 and a outsideWordIdx word vector as a building block for word2vec 6 models. K is the number of negative samples to take. 7 8 Note: The same word may be negatively sampled multiple times. For 9 example if an outside word is sampled twice, you shall have to 10 double count the gradient with respect to this word. Thrice if 11 it was sampled three times, and so forth. 12 13 Arguments/Return Specifications: same as naiveSoftmaxLossAndGradient 14 """ 15 , 16 # Negative sampling of words is done for you. Do not modify this if you 17 # wish to match the autograder and receive points! 18 negSampleWordIndices = getNegativeSamples(outsideWordIdx, dataset, K) #选取非outsideWordIdx的K个负样本索引 19 indices = [outsideWordIdx] + negSampleWordIndices #K+1个样本索引 20 21 ### YOUR CODE HERE (~10 Lines) 22 ### Please use your implementation of sigmoid in here. 23 gradCenterVec = np.zeros(centerWordVec.shape) 24 gradOutsideVecs = np.zeros(outsideVectors.shape) 25 loss = 0.0 26 27 u_o = outsideVectors[outsideWordIdx] 28 u_k = outsideVectors[negSampleWordIndices] 29 z1 = sigmoid(np.dot(u_o, centerWordVec)) #z1.shape= () 30 z2 = sigmoid(-np.dot(u_k, centerWordVec)) #z2.shape= (K,) 31 32 loss = -np.log(z1) - np.sum(np.log(z2)) 33 34 gradCenterVec += (z1-1.0) * u_o + np.dot((1.0-z2), u_k) 35 gradOutsideVecs[outsideWordIdx] += (z1-1.0) * centerWordVec 36 37 for i, negSampleWordIdx in enumerate(negSampleWordIndices): 38 gradOutsideVecs[negSampleWordIdx] += (1.0 - z2[i]) * centerWordVec 39 ### END YOUR CODE 40 41 return loss, gradCenterVec, gradOutsideVecs
1.4skipgram
遍历所有的外围词,求和损失函数。

1 def skipgram(currentCenterWord, windowSize, outsideWords, word2Ind, 2 centerWordVectors, outsideVectors, dataset, 3 word2vecLossAndGradient=naiveSoftmaxLossAndGradient): 4 """ Skip-gram model in word2vec 5 6 Implement the skip-gram model in this function. 7 8 Arguments: 9 currentCenterWord -- a string of the current center word 10 windowSize -- integer, context window size 11 outsideWords -- list of no more than 2*windowSize strings, the outside words 12 word2Ind -- a dictionary that maps words to their indices in 13 the word vector list 14 centerWordVectors -- center word vectors (as rows) is in shape 15 (num words in vocab, word vector length) 16 for all words in vocab (V in pdf handout) 17 outsideVectors -- outside vectors is in shape 18 (num words in vocab, word vector length) 19 for all words in vocab (U in the pdf handout) 20 word2vecLossAndGradient -- the loss and gradient function for 21 a prediction vector given the outsideWordIdx 22 word vectors, could be one of the two 23 loss functions you implemented above. 24 25 Return: 26 loss -- the loss function value for the skip-gram model 27 (J in the pdf handout) 28 gradCenterVec -- the gradient with respect to the center word vector 29 in shape (word vector length, ) 30 (dJ / dv_c in the pdf handout) 31 gradOutsideVecs -- the gradient with respect to all the outside word vectors 32 in shape (num words in vocab, word vector length) 33 (dJ / dU) 34 """ 35 loss = 0.0 36 gradCenterVecs = np.zeros(centerWordVectors.shape) #(num words, word vector length) 37 gradOutsideVectors = np.zeros(outsideVectors.shape) #(num words, word vector length) 38 39 ### YOUR CODE HERE (~8 Lines) 40 currentCenterWordIdx = word2Ind[currentCenterWord] 41 centerWordVec = centerWordVectors[currentCenterWordIdx] #中心词向量 42 43 for word in outsideWords: #遍历外围词,依次计算损失和梯度 44 idx = word2Ind[word] 45 l, gradCenter, gradOutside = word2vecLossAndGradient(centerWordVec, idx, outsideVectors, dataset) 46 47 loss += l 48 gradCenterVecs[currentCenterWordIdx] += gradCenter 49 gradOutsideVectors += gradOutside 50 51 ### END YOUR CODE 52 53 return loss, gradCenterVecs, gradOutsideVectors
1.5功能测试
1 ############################################# 2 # Testing functions below. DO NOT MODIFY! # 3 ############################################# 4 5 def word2vec_sgd_wrapper(word2vecModel, word2Ind, wordVectors, dataset, 6 windowSize, word2vecLossAndGradient=naiveSoftmaxLossAndGradient): 7 batchsize = 50 8 loss = 0.0 9 grad = np.zeros(wordVectors.shape) 10 N = wordVectors.shape[0] 11 centerWordVectors = wordVectors[:int(N/2),:] 12 outsideVectors = wordVectors[int(N/2):,:] 13 for i in range(batchsize): 14 windowSize1 = random.randint(1, windowSize) 15 centerWord, context = dataset.getRandomContext(windowSize1) 16 17 c, gin, gout = word2vecModel( 18 centerWord, windowSize1, context, word2Ind, centerWordVectors, 19 outsideVectors, dataset, word2vecLossAndGradient 20 ) 21 loss += c / batchsize 22 grad[:int(N/2), :] += gin / batchsize 23 grad[int(N/2):, :] += gout / batchsize 24 25 return loss, grad 26 27 28 def test_word2vec(): 29 """ Test the two word2vec implementations, before running on Stanford Sentiment Treebank """ 30 dataset = type('dummy', (), {})() 31 def dummySampleTokenIdx(): 32 return random.randint(0, 4) 33 34 def getRandomContext(C): 35 tokens = ["a", "b", "c", "d", "e"] 36 return tokens[random.randint(0,4)], \ 37 [tokens[random.randint(0,4)] for i in range(2*C)] 38 dataset.sampleTokenIdx = dummySampleTokenIdx 39 dataset.getRandomContext = getRandomContext 40 41 random.seed(31415) 42 np.random.seed(9265) 43 dummy_vectors = normalizeRows(np.random.randn(10,3)) 44 dummy_tokens = dict([("a",0), ("b",1), ("c",2),("d",3),("e",4)]) 45 46 print("==== Gradient check for skip-gram with naiveSoftmaxLossAndGradient ====") 47 gradcheck_naive(lambda vec: word2vec_sgd_wrapper( 48 skipgram, dummy_tokens, vec, dataset, 5, naiveSoftmaxLossAndGradient), 49 dummy_vectors, "naiveSoftmaxLossAndGradient Gradient") 50 51 grad_tests_softmax(skipgram, dummy_tokens, dummy_vectors, dataset) 52 53 print("==== Gradient check for skip-gram with negSamplingLossAndGradient ====") 54 gradcheck_naive(lambda vec: word2vec_sgd_wrapper( 55 skipgram, dummy_tokens, vec, dataset, 5, negSamplingLossAndGradient), 56 dummy_vectors, "negSamplingLossAndGradient Gradient") 57 58 grad_tests_negsamp(skipgram, dummy_tokens, dummy_vectors, dataset, negSamplingLossAndGradient) 59 60 61 if __name__ == "__main__": 62 test_word2vec()
==== Gradient check for skip-gram with naiveSoftmaxLossAndGradient ====
Gradient check passed!. Read the docstring of the `gradcheck_naive` method in utils.gradcheck.py to understand what the gradient check does.
======Skip-Gram with naiveSoftmaxLossAndGradient Test Cases======
The first test passed!
The second test passed!
The third test passed!
All 3 tests passed!
==== Gradient check for skip-gram with negSamplingLossAndGradient ====
Gradient check passed!. Read the docstring of the `gradcheck_naive` method in utils.gradcheck.py to understand what the gradient check does.
======Skip-Gram with negSamplingLossAndGradient======
The first test passed!
The second test passed!
The third test passed!
All 3 tests passed!
2sgd.py
1 def sgd(f, x0, step, iterations, postprocessing=None, useSaved=False, PRINT_EVERY=10): 2 """ Stochastic Gradient Descent 3 4 Implement the stochastic gradient descent method in this function. 5 6 Arguments: 7 f -- the function to optimize, it should take a single 8 argument and yield two outputs, a loss and the gradient 9 with respect to the arguments 10 x0 -- the initial point to start SGD from 11 step -- the step size for SGD 12 iterations -- total iterations to run SGD for 13 postprocessing -- postprocessing function for the parameters 14 if necessary. In the case of word2vec we will need to 15 normalize the word vectors to have unit length. 16 PRINT_EVERY -- specifies how many iterations to output loss 17 18 Return: 19 x -- the parameter value after SGD finishes 20 """ 21 # Anneal learning rate every several iterations 22 ANNEAL_EVERY = 20000 23 24 if useSaved: 25 start_iter, oldx, state = load_saved_params() 26 if start_iter > 0: 27 x0 = oldx 28 step *= 0.5 ** (start_iter / ANNEAL_EVERY) 29 30 if state: 31 random.setstate(state) 32 else: 33 start_iter = 0 34 35 x = x0 36 37 if not postprocessing: 38 postprocessing = lambda x: x 39 40 exploss = None 41 42 for iter in range(start_iter + 1, iterations + 1): 43 # You might want to print the progress every few iterations. 44 45 loss = None 46 ### YOUR CODE HERE (~2 lines) 47 loss, gradient = f(x) 48 x = x - step * gradient 49 ### END YOUR CODE 50 51 x = postprocessing(x) 52 if iter % PRINT_EVERY == 0: 53 if not exploss: 54 exploss = loss 55 else: 56 exploss = .95 * exploss + .05 * loss 57 print("iter %d: %f" % (iter, exploss)) 58 59 if iter % SAVE_PARAMS_EVERY == 0 and useSaved: 60 save_params(iter, x) 61 62 if iter % ANNEAL_EVERY == 0: 63 step *= 0.5 64 65 return x
3run.py
1 import random 2 import numpy as np 3 from utils.treebank import StanfordSentiment 4 import matplotlib 5 matplotlib.use('agg') 6 import matplotlib.pyplot as plt 7 import time 8 9 from word2vec import * 10 from sgd import * 11 12 # Check Python Version 13 import sys 14 assert sys.version_info[0] == 3 15 assert sys.version_info[1] >= 5 16 17 # Reset the random seed to make sure that everyone gets the same results 18 random.seed(314) 19 dataset = StanfordSentiment() 20 tokens = dataset.tokens() 21 nWords = len(tokens) 22 23 # We are going to train 10-dimensional vectors for this assignment 24 dimVectors = 10 25 26 # Context size 27 C = 5 28 29 # Reset the random seed to make sure that everyone gets the same results 30 random.seed(31415) 31 np.random.seed(9265) 32 33 startTime=time.time() 34 wordVectors = np.concatenate( 35 ((np.random.rand(nWords, dimVectors) - 0.5) / 36 dimVectors, np.zeros((nWords, dimVectors))), 37 axis=0) 38 wordVectors = sgd( 39 lambda vec: word2vec_sgd_wrapper(skipgram, tokens, vec, dataset, C, 40 negSamplingLossAndGradient), 41 wordVectors, 0.3, 40000, None, True, PRINT_EVERY=10) 42 # Note that normalization is not called here. This is not a bug, 43 # normalizing during training loses the notion of length. 44 45 print("sanity check: cost at convergence should be around or below 10") 46 print("training took %d seconds" % (time.time() - startTime)) 47 48 # concatenate the input and output word vectors 49 wordVectors = np.concatenate( 50 (wordVectors[:nWords,:], wordVectors[nWords:,:]), 51 axis=0) 52 53 visualizeWords = [ 54 "great", "cool", "brilliant", "wonderful", "well", "amazing", 55 "worth", "sweet", "enjoyable", "boring", "bad", "dumb", 56 "annoying", "female", "male", "queen", "king", "man", "woman", "rain", "snow", 57 "hail", "coffee", "tea"] 58 59 visualizeIdx = [tokens[word] for word in visualizeWords] 60 visualizeVecs = wordVectors[visualizeIdx, :] 61 temp = (visualizeVecs - np.mean(visualizeVecs, axis=0)) 62 covariance = 1.0 / len(visualizeIdx) * temp.T.dot(temp) 63 U,S,V = np.linalg.svd(covariance) 64 coord = temp.dot(U[:,0:2]) 65 66 for i in range(len(visualizeWords)): 67 plt.text(coord[i,0], coord[i,1], visualizeWords[i], 68 bbox=dict(facecolor='green', alpha=0.1)) 69 70 plt.xlim((np.min(coord[:,0]), np.max(coord[:,0]))) 71 plt.ylim((np.min(coord[:,1]), np.max(coord[:,1]))) 72 73 plt.savefig('word_vectors.png')
渣渣本跑不动,但loss的总体趋势在减小。

