支持向量机(SVM、决策边界函数)
1.处理线性问题
1.1数据集预处理
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import datasets 4 5 iris = datasets.load_iris() 6 X = iris.data 7 y = iris.target 8 9 X = X[y<2, :2] #只取前面两个特征 10 y = y[y<2] 11 12 13 plt.scatter(X[y==0,0], X[y==0,1], color='red') 14 plt.scatter(X[y==1,0], X[y==1,1], color='blue') 15 plt.show() 16 17 #数据标准化 18 from sklearn.preprocessing import StandardScaler 19 20 standardScaler=StandardScaler() 21 standardScaler.fit(X) 22 X_standard=standardScaler.transform(X)
1.2决策边界函数
1 def plot_decision_boundary(model, axis): 2 x0,x1=np.meshgrid( 3 np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1), 4 np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1) 5 ) 6 X_new = np.c_[x0.ravel(), x1.ravel()] #c_[]将两个数组以列的形式拼接起来,形成矩阵。 7 y_predict = model.predict(X_new) 8 9 zz = y_predict.reshape(x0.shape) #通过训练好的模型,预测平面上这些点的分类 10 11 from matplotlib.colors import ListedColormap 12 custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) 13 14 plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap)
1.3拟合数据,显示边界
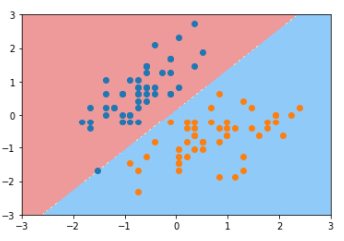
1 from sklearn.svm import LinearSVC 2 3 svc = LinearSVC(C=1e9) #Hard margin 4 print(svc.fit(X_standard, y)) 5 6 plot_decision_boundary(svc, axis=[-3, 3, -3, 3]) 7 plt.scatter(X_standard[y==0,0], X_standard[y==0,1]) 8 plt.scatter(X_standard[y==1,0], X_standard[y==1,1]) 9 plt.show() 10 11 12 svc2 = LinearSVC(C=0.01) #Soft margin 13 print(svc2.fit(X_standard, y)) 14 15 plot_decision_boundary(svc2, axis=[-3, 3, -3, 3]) 16 plt.scatter(X_standard[y==0,0], X_standard[y==0,1]) 17 plt.scatter(X_standard[y==1,0], X_standard[y==1,1]) 18 plt.show()
LinearSVC(C=1000000000.0, class_weight=None, dual=True, fit_intercept=True,intercept_scaling=1, loss='squared_hinge', max_iter=1000,multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,verbose=0)
LinearSVC(C=0.01, class_weight=None, dual=True, fit_intercept=True,intercept_scaling=1, loss='squared_hinge', max_iter=1000,multi_class='ovr', penalty='l2', random_state=None, tol=0.0001,verbose=0)
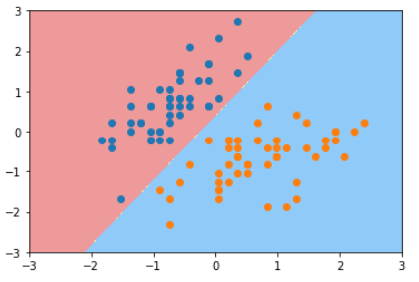
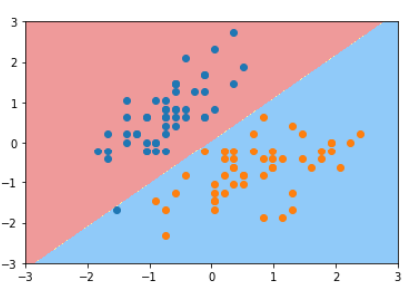
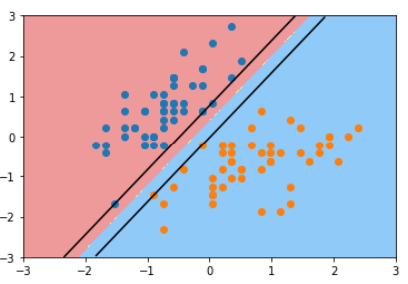
软间隔对数据的包容性更大,所以会有少许分类错误的点。
1.4改编决策边界,画出间隔面的上下两个面
1 def plot_svc_decision_boundary(model, axis): 2 x0,x1=np.meshgrid( 3 np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1, 1), 4 np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1, 1) 5 ) 6 X_new = np.c_[x0.ravel(), x1.ravel()] #c_[]将两个数组以列的形式拼接起来,形成矩阵。 7 y_predict = model.predict(X_new) 8 9 zz = y_predict.reshape(x0.shape) 10 11 from matplotlib.colors import ListedColormap 12 custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9']) 13 14 plt.contourf(x0, x1, zz, linewidth=5, cmap=custom_cmap) 15 16 w = model.coef_[0] 17 b = model.intercept_[0] 18 19 #w0*x0 + w1*x1 + b = 0 20 #x1 = -w0/w1 *x0 -b/w1 21 plot_x = np.linspace(axis[0], axis[1], 200) 22 up_y = -w[0]/w[1] *plot_x - b/w[1] + 1/w[1] #w0*x0 + w1*x1 + b = 1 23 down_y = -w[0]/w[1] *plot_x - b/w[1] - 1/w[1] #w0*x0 + w1*x1 + b = -1 24 25 #防止超出绘图,进行过滤 26 up_index = (up_y >= axis[2]) & (up_y <= axis[3]) 27 down_index = (down_y >= axis[2]) & (down_y <= axis[3]) 28 29 plt.plot(plot_x[up_index], up_y[up_index], color='black') 30 plt.plot(plot_x[down_index], down_y[down_index], color='black') 31 32 33 #以上面hard margin为例,绘图 34 plot_svc_decision_boundary(svc, axis=[-3, 3, -3, 3]) 35 plt.scatter(X_standard[y==0,0], X_standard[y==0,1]) 36 plt.scatter(X_standard[y==1,0], X_standard[y==1,1]) 37 plt.show()
2.处理非线性问题
2.1加载数据集
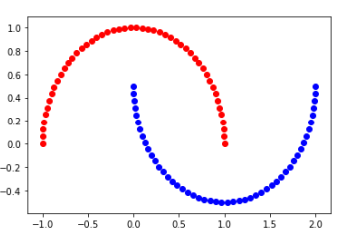
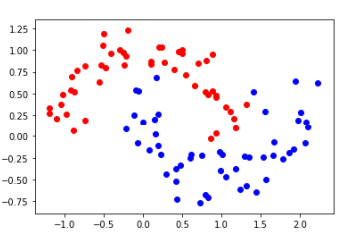
1 #SVM使用多项式特征 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from sklearn import datasets 5 6 X, y = datasets.make_moons() #X.shape=(100,2) y.shape=(100,) 7 8 plt.scatter(X[y==0,0], X[y==0,1], color='red') 9 plt.scatter(X[y==1,0], X[y==1,1], color='blue') 10 plt.show() 11 12 #加点噪音扰乱一下 13 X, y = datasets.make_moons(noise=0.15, random_state=666) 14 plt.scatter(X[y==0,0], X[y==0,1], color='red') 15 plt.scatter(X[y==1,0], X[y==1,1], color='blue') 16 plt.show()
2.2拟合数据,显示边界
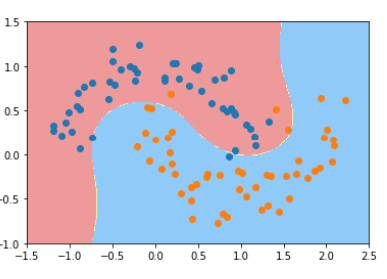
多项式特征可以理解为对现有特征的乘积,比如现在有特征A,特征B,特征C,那就可以得到特征A的平方(A^2),A*B,A*C,B^2,B*C以及C^2. 新生成的这些变量即原有变量的有机组合,换句话说,当两个变量各自与y的关系并不强时候,把它们结合成为一个新的变量可能更会容易体现出它们与y的关系。
Pipeline(list)
list 内的每一个元素为为管道的一步,每一步是一个元组。
1 from sklearn.preprocessing import PolynomialFeatures,StandardScaler 2 from sklearn.svm import LinearSVC 3 from sklearn.pipeline import Pipeline 4 5 def PolynomialSVC(degree, C=1.0): 6 return Pipeline([ 7 ('poly',PolynomialFeatures(degree=degree)), 8 ('std_scaler', StandardScaler()), 9 ('linearSVC', LinearSVC(C=C)) 10 ]) 11 12 poly_svc = PolynomialSVC(degree=3) 13 poly_svc.fit(X, y) 14 15 plot_decision_boundary(poly_svc, axis=[-1.5, 2.5, -1.0, 1.5]) 16 plt.scatter(X[y==0,0], X[y==0,1]) 17 plt.scatter(X[y==1,0], X[y==1,1]) 18 plt.show()
3.对决策边界函数的应用
以1.1中标准化的数据为例:
1 #KNN 2 from sklearn.neighbors import KNeighborsClassifier 3 knn = KNeighborsClassifier() #n_neighbors越大,模型越简单,也意味着过拟合的程度越轻,决策边界越清晰 4 knn.fit(X_standard, y) 5 6 plot_decision_boundary(knn, axis=[-3, 3, -3, 3]) 7 plt.scatter(X_standard[y==0,0], X_standard[y==0,1]) 8 plt.scatter(X_standard[y==1,0], X_standard[y==1,1]) 9 plt.show()
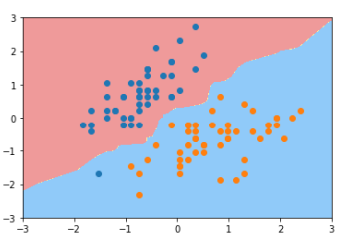
1 #逻辑回归 2 from sklearn.linear_model import LogisticRegression 3 reg = LogisticRegression() 4 reg.fit(X_standard, y) 5 6 plot_decision_boundary(reg, axis=[-3, 3, -3, 3]) 7 plt.scatter(X_standard[y==0,0], X_standard[y==0,1]) 8 plt.scatter(X_standard[y==1,0], X_standard[y==1,1]) 9 plt.show()