

Pytorch-卷积神经网络&Batch Norm
1.卷积层
1.1torch.nn.Conv2d()类式接口
1 torch.nn.Conv2d(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True))
参数:
- in_channel:输入数据的通道数,例RGB图片通道数为3;
- out_channel:输出数据的通道数,也就是kernel数量;
- kernel_size: 卷积核大小,可以是int,或tuple;kernel_size=2,意味着卷积大小(2,2),kernel_size=(2,3),意味着卷积大小(2,3)即非正方形卷积
- stride:步长,默认为1,与kernel_size类似,stride=2,意味着步长上下左右扫描皆为2, stride=(2,3),左右扫描步长为2,上下为3;
- padding:零填充
1 import torch 2 import torch.nn as nn 3 4 x=torch.rand(1,1,28,28) #batch, channel, height, width 5 layer=nn.Conv2d(1,3,kernel_size=3,stride=2,padding=1) #in_channel(和上面x中的channel数量一致), out_channel(kernel个数) 6 7 out=layer.forward(x) #或者直接out=layer(x) 8 print(out.shape) #torch.Size([1, 3, 14, 14]) 1指一张图片,3指三个kernel,14*14指图片大小
- 第五行layer的相关属性:
- layer.weight.shape = torch.Size([3,1,3,3]) 第一个3指out_channel,即输出数据的通道数(kernel个数),第二个1指in_channel,即输入数据的通道数,这个值必须和x的channel数目一致。(Tip:前两个参数顺序是和Conv2d函数的前两个参数顺序相反的)
- layer.bias.shape = torch.Size([3]) 这个3指kernel个数,不同的通道共用一个偏置。
- out输出维度的计算: 与 做卷积操作=
- n表示图片尺寸,p表示padding,f表示kernel尺寸,s表示slide步长,(28+2-3)/2+1=14.5,向下取整,即14
1.2F.conv2d()函数式接口
PyTorch里一般小写的都是函数式的接口,相应的大写的是类式接口。函数式的更加low-level一些,如果不需要做特别复杂的配置只要用类式接口即可。

1 import torch 2 from torch.nn import functional as F 3 4 #手动定义卷积核(weight)和偏置 5 w = torch.rand(16, 3, 5, 5) #16种3通道的5*5卷积核 6 b = torch.rand(16) 7 8 #定义输入样本 9 x = torch.randn(1, 3, 28, 28) #1张3通道的28*28的图像 10 11 #2D卷积得到输出 12 out = F.conv2d(x, w, b, stride=1, padding=1) 13 print(out.shape) #torch.Size([1, 16, 26, 26]) 14 15 out = F.conv2d(x, w, b, stride=2, padding=2) 16 print(out.shape) #torch.Size([1, 16, 14, 14])
2.池化层Pooling(下采样)
1 torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数:
- kernel_size(int or tuple) - max pooling的窗口大小,
- stride(int or tuple, optional) - max pooling的窗口移动的步长。默认值是kernel_size
- padding(int or tuple, optional) - 输入的每一条边补充0的层数
- dilation(int or tuple, optional) – 一个控制窗口中元素步幅的参数
- return_indices - 如果等于True,会返回输出最大值的序号,对于上采样操作会有帮助
- ceil_mode - 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作
接着上面卷积运算得到的1张16通道的14*14的图像,在此基础上做池化。
torch.MaxPool2d类式接口
1 x=out #torch.Size([1, 16, 14, 14]) 2 layer=nn.MaxPool2d(2,stride=2) #池化层(池化核为2*2,步长为2),最大池化 3 4 out=layer(x) 5 print(out.shape) #torch.Size([1, 16, 7, 7])
F.avg_pool2d()函数式接口
1 x = out #torch.Size([1, 16, 14, 14]) 2 out = F.avg_pool2d(x, 2, stride=2) 3 print(out.shape) #torch.Size([1, 16, 7, 7])
Tip:池化后通道数不变。
3.upsample(上采样)
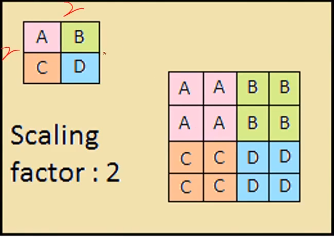
1 F.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)
参数:
- size(int):输出的spatial大小;
- scale_factor(float): spatial尺寸的缩放因子;
- mode(string):上采样算法:nearest,linear,bilinear,trilinear,area,默认nearest;
- align_corners(bool, optional):如果align_corners=True,则对齐input和output的角点像素,只会对 mode=linear, bilinear 和 trilinear 有作用。默认是 False。
1 x = out #torch.Size([1, 16, 7, 7]) 2 3 out = F.interpolate(x, scale_factor=2, mode='nearest') #向上采样,放大2倍,最近插值 4 print(out.shape) #torch.Size([1, 16, 14, 14])
4.RELU激活函数
4.1torch.nn.RELU()类式接口
1 x = out #torch.Size([1, 16, 14, 14]) 2 3 layer = nn.ReLU(inplace=True) #ReLU激活,inplace=True表示直接覆盖掉ReLU目标的内存空间 4 out = layer(x) 5 print(out.shape) #torch.Size([1, 16, 14, 14])
4.2F.relu()函数式接口
1 x = out #torch.Size([1, 16, 14, 14]) 2 3 out = F.relu(x) 4 print(x.shape) #torch.Size([1, 16, 14, 14])
5.Batch Norm
归一化可以使代价函数平均起来看更对称,使用梯度下降法更方便。
通常分为两步:调整均值、方差归一化
5.1Batch Norm
一个Batch的图像数据shape为[样本数N, 通道数C, 高度H, 宽度W],将其最后两个维度flatten,得到的是[N, C, H*W],标准的Batch Normalization就是在通道channel这个维度上进行移动,对所有样本的所有值求均值和方差,所以有几个通道,得到的就是几个均值和方差。
eg.[6, 3, 784]会生成[3],代表当前batch中每一个channel的特征均值,3个channel有3个均值和3个方差,只保留了channel维度,所以是[3]。
5.2Layer Norm
样本N的维度上滑动,对每个样本的所有通道的所有值求均值和方差,所以一个Batch有几个样本实例,得到的就是几个均值和方差。
eg.[6, 3, 784]会生成[6]
5.3Instance Norm
在样本N和通道C两个维度上滑动,对Batch中的N个样本里的每个样本n,和C个通道里的每个样本c,其组合[n, c]求对应的所有值的均值和方差,所以得到的是N*C个均值和方差。
5.4Batch Norm详解
输入数据是6张3通道784个像素点的数据,将其分到三个通道上,在每个通道上也就是[6, 784]的数据,然后分别得到和通道数一样多的统计数据均值μ和方差σ,将每个像素值减去μ除以σ也就变换到了接近N(0,1)的分布,后面又使用参数β和γ将其变换到接近N(β,γ)的分布。

Tip:μ和σ只是样本中的统计数据,是没有梯度信息的,不过会保存在运行时参数里。而γ和β属于要训练的参数,他们是有梯度信息的。
正式计算:

nn.BatchNorm1d()
1 import torch 2 from torch import nn 3 4 x = torch.rand(100, 16, 784) #100张16通道784像素点的数据,均匀分布 5 6 layer = nn.BatchNorm1d(16) #传入通道数,因为H和W已经flatten过了,所以用1d 7 out = layer(x) 8 9 print(layer.running_mean) 10 #tensor([0.0499, 0.0501, 0.0501, 0.0501, 0.0501, 0.0502, 0.0500, 0.0499, 0.0499, 11 # 0.0501, 0.0500, 0.0500, 0.0500, 0.0501, 0.0500, 0.0500]) 12 print(layer.running_var) 13 #tensor([0.9083, 0.9083, 0.9083, 0.9084, 0.9083, 0.9083, 0.9084, 0.9083, 0.9083, 14 # 0.9083, 0.9083, 0.9083, 0.9084, 0.9084, 0.9083, 0.9083])
Tip:layer.running_mean和layer.running_var得到的是全局的均值和方差,不是当前Batch上的,只不过这里只跑了一个Batch而已所以它就是这个Batch上的。
nn.BatchNorm2d()
1 import torch 2 from torch import nn 3 4 x = torch.rand(1, 16, 7, 7) #1张16通道的7*7的图像 5 6 layer = nn.BatchNorm2d(16) #传入通道数(必须和上面的通道数目一致) 7 out = layer(x) 8 9 print(out.shape) #torch.Size([1, 16, 7, 7]) 10 print(layer.running_mean) 11 print(layer.running_var) 12 print(layer.weight.shape) #torch.Size([16])对应上面的γ 13 print(layer.bias.shape) #torch.Size([16])对应上面的β 14 print(vars(layer)) #查看网络中一个层上的所有参数 15 # {'training': True, 16 # '_parameters': 17 # OrderedDict([('weight', Parameter containing: 18 # tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], requires_grad=True)), 19 # ('bias', Parameter containing: 20 # tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], requires_grad=True))]), 21 # '_buffers': 22 # OrderedDict([('running_mean', tensor([0.0527, 0.0616, 0.0513, 0.0488, 0.0484, 0.0510, 0.0590, 0.0459, 0.0448, 0.0586, 0.0535, 0.0464, 0.0581, 0.0481, 0.0420, 0.0549])), 23 # ('running_var', tensor([0.9089, 0.9075, 0.9082, 0.9079, 0.9096, 0.9098, 0.9079, 0.9086, 0.9081, 0.9075, 0.9052, 0.9081, 0.9093, 0.9075, 0.9086, 0.9073])), 24 # ('num_batches_tracked', tensor(1))]), 25 # '_backward_hooks': OrderedDict(), 26 # '_forward_hooks': OrderedDict(), 27 # '_forward_pre_hooks': OrderedDict(), 28 # '_state_dict_hooks': OrderedDict(), 29 # '_load_state_dict_pre_hooks': OrderedDict(), 30 # '_modules': OrderedDict(), 31 # 'num_features': 16, 32 # 'eps': 1e-05, 33 # 'momentum': 0.1, 34 # 'affine': True, 35 # 'track_running_stats': True}
Tip:
- layer.weight和layer.bias是当前batch上的;
-
如果在定义层时使用了参数affine=False,那么就是固定γ=1和β=0不自动学习,这时参数layer.weight和layer.bias将是None。
5.5Train和Test
类似于Dropout,Batch Normalization在训练和测试时的行为不同。
测试模式下,和使用训练集得到的全局和,归一化前调用layer.eval()设置Test模式。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!
2017-07-15 Android学习——控件ListView的使用