手写KNN情感分类器
训练集和测试集(训练集包含两个文件:train_negative.txt和train_positive.text,分别包含2000多的负样本和2000多的正样本。文件里面的每一行代表一个样本(例如:一篇电影评论)。测试样本类似。):
链接:https://pan.baidu.com/s/1GybqIYsqGiUgL84EbrCY0w
提取码:d5ml
以下步骤不调用sklearn库
1.文本预处理
包括读取文本内容进行分词,过滤标点符号,过滤停用词,还原词形。
1 stopwords = nltk.corpus.stopwords.words('english') 2 3 #过滤掉标点 4 def get_tokens(text): 5 lowers = text.lower() 6 remove_punctuation_map = dict((ord(char), None) for char in string.punctuation) 7 no_punctuation = lowers.translate(remove_punctuation_map) 8 tokens = nltk.word_tokenize(no_punctuation) 9 return tokens 10 11 #单词词形还原 12 def stem_tokens(tokens, stemmer): 13 stemmed = [] 14 for item in tokens: 15 stemmed.append(stemmer.stem(item)) 16 return stemmed 17 18 #输入文件路径 19 #返回list(res)中存储所有不同的单词,tmp中存储许多列,每一列中对应每一句评价的单词 20 def readFile(filename): 21 f = open(filename,encoding='utf-8') 22 content = f.read().splitlines() 23 res, tmp = set(), [] 24 25 for s in content: 26 lst=[] 27 tokens = get_tokens(s) #去除标点 28 filtered = [w for w in tokens if not w in stopwords] #去除停用词 29 stemmer = PorterStemmer() 30 stemmed = stem_tokens(filtered, stemmer) #单词词形还原 31 32 for word in stemmed: 33 lst.append(word) 34 res.add(word) 35 tmp.append(lst) 36 f.close() 37 return list(res),tmp
2.文本向量化
VSM( Vector space model):即向量空间模型。是指忽略文档内的单词顺序和语法、句法等要素,将其仅仅看作是若干个词汇的集合,将每个文档表示成同一向量空间的向量。用向量空间模型表示文本需要进行权重计算,常见的有布尔权重和tf-idf权重。
布尔权重:
1 #输入单词列表和句子列表 2 #返回特征向量 3 def boolCountVectorizer(wordlst,senlst): 4 wordCount = len(wordlst) #总单词数,向量共wordCount列 5 senCount = len(senlst) #总句子数,向量共senCount行 6 mat = np.zeros((senCount,wordCount), dtype=int) 7 word_index={} 8 for i in range(len(wordlst)): #提前记录每个单词在wordlst中的序号 9 word_index[str(wordlst[i])] = i 10 for i in range(senCount): 11 for j in range(len(senlst[i])): 12 if senlst[i][j] in wordlst: 13 idx = word_index[str(senlst[i][j])] 14 mat[i][idx] += 1 15 16 return mat
tf-idf权重:
在 tf-idf模式下,词条t在文档d中的权重计算为w(t)=tf(t, d)*idf(t)。其中,tf(t,d)表示为词条t在文档d中的出现频率,idf(t)表示与包含词条t的文档数目成反比( inverse document frequency)
idf(t)计算公式: (nd表示文档总数,df(t)表示包含该词条t的文档数)
(nd表示文档总数,df(t)表示包含该词条t的文档数)
(nd表示文档总数,df(t)表示包含该词条t的文档数)数据平滑问题:为了防止分母df(t)为零
1 def tfidfCountVectorizer(wordlst,senlst): 2 3 wordCount=len(wordlst) 4 senCount=len(senlst) 5 weight = np.zeros((senCount,wordCount), dtype=float) 6 7 n3 = senCount #n3表示句子总数 8 for j,word in enumerate(wordlst): 9 n4 = 0 #n4表示包含该word的句子数 10 for eve in senlst: 11 if word in eve: 12 n4 += 1 13 idf = math.log(((n3+1)/(n4+1))+1) 14 15 for i in range(senCount): 16 n1 = senlst[i].count(word) 17 n2 = len(senlst[i]) 18 tf = n1/n2 #tf表示word在句子senlst[i]中的出现频率 19 20 weight[i][j]=tf*idf #weight[i][j]表示第j个词在i个句子中的tf-idf权重 21 return weight
3.特征选择
文本向量化之后要进行特征选择,选择对于训练任务有帮助的若干特征,剔除掉不相关的特征,从而减少特征个数(缩短列坐标的长度),常见的有方差选择法、皮尔森相关系数法。
方差选择法
原理:方差非常小的特征维度对于样本的区分作用很小,可以剔除。
例如,假设数据集为布尔特征,想去掉那些超过80%情况下为1或者为0的特征。由于布尔特征是 Bernoulli(伯努利)随机变量,其方差可以计算为Var[x]=p*(1-p),因此阈值为0.8*(1-0.8)=0.16
 第一列方差为(5/6)*(1/6)=0.14,小于0.16,因此第一列所对应的特征可以被过滤掉。
第一列方差为(5/6)*(1/6)=0.14,小于0.16,因此第一列所对应的特征可以被过滤掉。1 #输入特征向量mat,参数p,单词列表wordlst 2 #返回特征选择后的向量mat,特征单词wordlst 3 def featureSupport1(mat, p, wordlst): 4 wordlst=np.array(wordlst) 5 6 var = p * (1 - p) 7 lst = np.var(mat, axis=0) #计算每列的方差 8 mu = lst >= var #mu得到一个bool矩阵 9 return mat[:,mu],wordlst[mu]
皮尔森相关系数法
皮尔森相关系数显示两个随机变量之间线性关系的强度和方向。
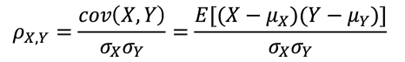
其中,cov(X,Y)表示X和之间的协方差( Covariance),![]()
 是X的均方差,
是X的均方差,![]()
 是X的均值,E表示数学期望。
是X的均值,E表示数学期望。
是X的均方差,是X的均值,E表示数学期望。计算完毕后,可以将与目标值相关性较小的特征过滤掉。
代码中直接调用scipy库,手动实现速度太慢了。
1 def featureSupport2(mat,threshold,wordlst,y_train): 2 wordlst=np.array(wordlst) 3 y_train=np.array(y_train) 4 5 lst=[pearsonr(mat[:,i],y_train.T)[0] for i in range(mat.shape[1])] 6 mu=np.abs(np.array(lst))>=threshold 7 return mat[:,mu],wordlst[mu]
4.KNN分类
步骤如下:
- 计算训练集中所有点与当前测试点间的距离(使用欧式距离公式,代码中计算的是距离的平方,省去了开根)
- 选取距离测试点最近的K个点
- 记录这K个点所属的类别
- 所有类别中出现次数最多的类别,作为该测试点的预测类别
- 将预测类别和测试集标签相比,计算预测的准确率
1 #输入训练向量matTest,训练标签y_train,测试向量matTest,测试标签y_test 2 #返回预测准确率,positive准确率,negtative准确率 3 def KNN(matTrain, y_train, matTest, y_test, k=13): 4 5 numTrain=matTrain.shape[0] 6 numTest=matTest.shape[0] 7 8 numPos,numNeg=y_test.count(1),y_test.count(0) 9 predTrue,posTrue,negTrue=0,0,0 10 for i in range(numTest): 11 distances=[np.sum((matTrain[j]-matTest[i])**2) for j in range(numTrain)] 12 13 distances = np.array(distances) 14 nearest = distances.argsort() #返回原数组的下标 15 topK_y=[y_train[i] for i in nearest[:k]] #topK_y得到最近的k个点所属的类别(很多个) 16 votes=Counter(topK_y) 17 predict_y=votes.most_common(1)[0][0] #多个类别中的大多数类别 18 19 if predict_y==y_test[i]==1: 20 posTrue+=1 21 predTrue+=1 22 if predict_y==y_test[i]==0: 23 negTrue+=1 24 predTrue+=1 25 26 return predTrue/numTest,posTrue/numPos,negTrue/numNeg
5.结果展示
使用布尔权重运行一次时间20min~30min,使用tf-idf时间约40min。
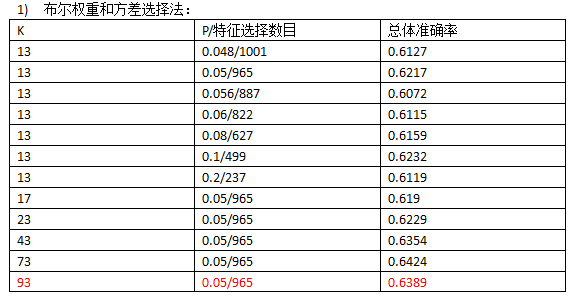
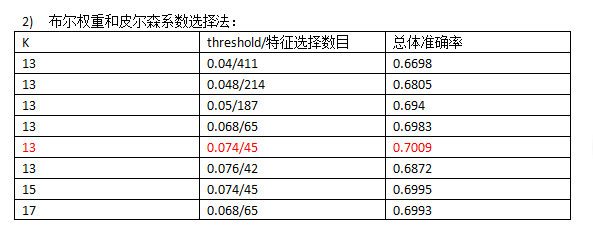

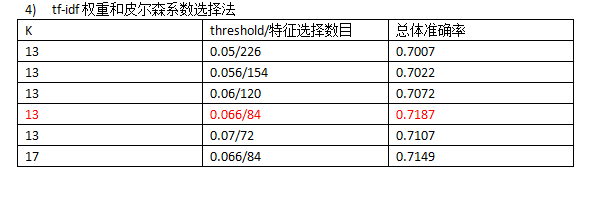
从运行结果来看,使用tf-idf权重和皮尔森系数选择法是较为理想的选择,总体准确率在70%以上。
从运行效率来看,执行方差选择法和皮尔森系数选择法时利用numpy库代替for循环会大大缩短时间,从原来的一个多小时,降到半小时以内,tf-idf权重循环次数更多,耗时会长一些,四十几分钟。
参考:https://www.jb51.net/article/128346.htm
6.附完整代码
1 import numpy as np 2 import math 3 from scipy.stats import pearsonr 4 from collections import Counter 5 import string 6 import nltk 7 from nltk.stem.porter import PorterStemmer 8 from time import * 9 10 stopwords = nltk.corpus.stopwords.words('english') 11 12 #过滤掉标点 13 def get_tokens(text): 14 lowers = text.lower() 15 remove_punctuation_map = dict((ord(char), None) for char in string.punctuation) 16 no_punctuation = lowers.translate(remove_punctuation_map) 17 tokens = nltk.word_tokenize(no_punctuation) 18 return tokens 19 20 #单词词形还原 21 def stem_tokens(tokens, stemmer): 22 stemmed = [] 23 for item in tokens: 24 stemmed.append(stemmer.stem(item)) 25 return stemmed 26 27 #输入文件路径 28 #返回list(res)中存储所有不同的单词,tmp中存储许多列,每一列中对应每一句评价的单词 29 def readFile(filename): 30 f = open(filename,encoding='utf-8') 31 content = f.read().splitlines() 32 res, tmp = set(), [] 33 34 for s in content: 35 lst=[] 36 tokens = get_tokens(s) #去除标点 37 filtered = [w for w in tokens if not w in stopwords] #去除停用词 38 stemmer = PorterStemmer() 39 stemmed = stem_tokens(filtered, stemmer) #单词词形还原 40 41 for word in stemmed: 42 lst.append(word) 43 res.add(word) 44 tmp.append(lst) 45 f.close() 46 return list(res),tmp 47 48 49 #特征向量化 50 #法一:布尔权重 51 #输入单词列表和句子列表 52 #返回特征向量 53 def boolCountVectorizer(wordlst,senlst): 54 wordCount = len(wordlst) #总单词数,向量共wordCount列 55 senCount = len(senlst) #总句子数,向量共senCount行 56 mat = np.zeros((senCount,wordCount), dtype=int) 57 word_index={} 58 for i in range(len(wordlst)): #提前记录每个单词在wordlst中的序号 59 word_index[str(wordlst[i])] = i 60 for i in range(senCount): 61 for j in range(len(senlst[i])): 62 if senlst[i][j] in wordlst: 63 idx = word_index[str(senlst[i][j])] 64 mat[i][idx] += 1 65 return mat 66 67 68 #法二:tf-idf权重 69 def tfidfCountVectorizer(wordlst,senlst): 70 71 wordCount=len(wordlst) 72 senCount=len(senlst) 73 weight = np.zeros((senCount,wordCount), dtype=float) 74 75 n3 = senCount #n3表示句子总数 76 for j,word in enumerate(wordlst): 77 n4 = 0 #n4表示包含该word的句子数 78 for eve in senlst: 79 if word in eve: 80 n4 += 1 81 idf = math.log(((n3+1)/(n4+1))+1) 82 83 for i in range(senCount): 84 n1 = senlst[i].count(word) 85 n2 = len(senlst[i]) 86 tf = n1/n2 #tf表示word在句子senlst[i]中的出现频率 87 88 weight[i][j]=tf*idf #weight[i][j]表示第j个词在i个句子中的tf-idf权重 89 return weight 90 91 92 #特征选择 93 #法一:方差选择法 94 #输入特征向量mat,参数p,单词列表wordlst 95 #返回特征选择后的向量mat,特征单词wordlst 96 def featureSupport1(mat, p, wordlst): 97 wordlst=np.array(wordlst) 98 99 var = p * (1 - p) 100 lst = np.var(mat, axis=0) #计算每列的方差 101 mu = lst >= var #mu得到一个bool矩阵 102 return mat[:,mu],wordlst[mu] 103 104 105 106 #法二:皮尔森相关系数法 107 def featureSupport2(mat,threshold,wordlst,y_train): 108 wordlst=np.array(wordlst) 109 y_train=np.array(y_train) 110 111 lst=[pearsonr(mat[:,i],y_train.T)[0] for i in range(mat.shape[1])] 112 mu=np.abs(np.array(lst))>=threshold 113 return mat[:,mu],wordlst[mu] 114 115 116 #输入训练向量matTest,训练标签y_train,测试向量matTest,测试标签y_test 117 #返回预测准确率,positive准确率,negtative准确率 118 def KNN(matTrain, y_train, matTest, y_test, k=13): 119 120 numTrain=matTrain.shape[0] 121 numTest=matTest.shape[0] 122 123 numPos,numNeg=y_test.count(1),y_test.count(0) 124 predTrue,posTrue,negTrue=0,0,0 125 for i in range(numTest): 126 distances=[np.sum((matTrain[j]-matTest[i])**2) for j in range(numTrain)] 127 128 distances = np.array(distances) 129 nearest = distances.argsort() #返回原数组的下标 130 topK_y=[y_train[i] for i in nearest[:k]] #topK_y得到最近的k个点所属的类别(很多个) 131 votes=Counter(topK_y) 132 predict_y=votes.most_common(1)[0][0] #多个类别中的大多数类别 133 134 if predict_y==y_test[i]==1: 135 posTrue+=1 136 predTrue+=1 137 if predict_y==y_test[i]==0: 138 negTrue+=1 139 predTrue+=1 140 141 return predTrue/numTest,posTrue/numPos,negTrue/numNeg 142 143 144 if __name__=='__main__': 145 146 beginTime = time() 147 x1,s1=readFile("knn_corpurs/train_positive.txt") 148 x2,s2=readFile("knn_corpurs/train_negative.txt") 149 wordlst1=x1+x2 150 senlst1=s1+s2 151 y_train = [1]*len(s1)+[0]*len(s2) #训练集标签 152 153 print('len(wordlst1)=',len(wordlst1)) 154 print('len(senlst1)=',len(senlst1)) 155 156 157 y1,t1=readFile("knn_corpurs/test_positive.txt") 158 y2,t2=readFile("knn_corpurs/test_negative.txt") 159 wordlst2=y1+y2 160 senlst2=t1+t2 161 y_test = [1]*len(t1)+[0]*len(t2) #测试集标签 162 print('len(wordlst2)=',len(wordlst2)) 163 print('len(senlst2)=',len(senlst2)) 164 165 166 # mat1=boolCountVectorizer(wordlst1, senlst1) 167 mat1=tfidfCountVectorizer(wordlst1, senlst1) 168 print('mat1.shape=',mat1.shape) 169 170 # matTrain,wordTrain=featureSupport1(mat1, 0.2, wordlst1) #wordTrain表示训练出的特征单词 171 matTrain,wordTrain=featureSupport2(mat1, 0.066, wordlst1,y_train) 172 print('matTrain.shape=',matTrain.shape) #(5990,训练出的特征单词数) 173 print('len(wordTrain)=',len(wordTrain)) 174 175 176 # matTest=boolCountVectorizer(wordTrain, senlst2) #wordTrain是训练集训练出的特征单词 177 matTest=tfidfCountVectorizer(wordTrain, senlst2) 178 print('matTest.shape=',matTest.shape) #(,训练出的特征单词数) 179 180 accuarcy,posAccuarcy,negAccuarcy=KNN(matTrain,y_train,matTest,y_test,17) 181 print('总体准确率=',accuarcy) 182 print('positive文本准确率=',posAccuarcy) 183 print('negtative文本准确率=',negAccuarcy) 184 185 endTime=time() 186 runTime=endTime-beginTime 187 print("运行时间:",runTime) 188 189 190 #调库测试准确率 191 from sklearn.neighbors import KNeighborsClassifier 192 kNN_classifier=KNeighborsClassifier(n_neighbors=17) 193 kNN_classifier.fit(matTrain,y_train) 194 195 y_predict=kNN_classifier.predict(matTrain) 196 print('训练集positive准确率=',np.sum(y_predict[:600]==1)/600) 197 print('训练集negtative准确率=',np.sum(y_predict[-600:]==0)/600) 198 print('训练集总体准确率=',(np.sum(y_predict[:100]==1)+np.sum(y_predict[-100:]==0))/200) 199 200 y_predict_test=kNN_classifier.predict(matTest) 201 print('测试集positive准确率=',np.sum(y_predict_test[:100]==1)/100) 202 print('测试集negative准确率=',np.sum(y_predict_test[-100:]==0)/100) 203 print('测试集总体准确率=',(np.sum(y_predict_test[:100]==1)+np.sum(y_predict_test[-100:]==0))/200)
