
SAM学习笔记
前言
前排提示:由于作者水平很菜,所以本篇文章不会讲最优性证明、复杂度证明。如有需要请自行搜索
前排提示2;本文巨无敌长,阅读并完全理解可能需要
前排提示3:可能有点啰嗦,但在能忍受的情况下建议看完,会加深理解。
本篇文章的例子和插图全部来自 pecco 大佬的博客,作者也是通过那篇文章学会的 SAM。但那篇文章的思维跳跃比较快,有些理解写的也不是很完整(大佬博客通病),这篇文章可以看作那篇文章的详细版、简单版。
SAM 是干什么的
SAM,后缀自动机,顾名思义,是后缀的自动机(划掉)。可以理解为一个升级版的 trie 树,其中 trie 树内保存某字符串的所有后缀。例如,对于字符串
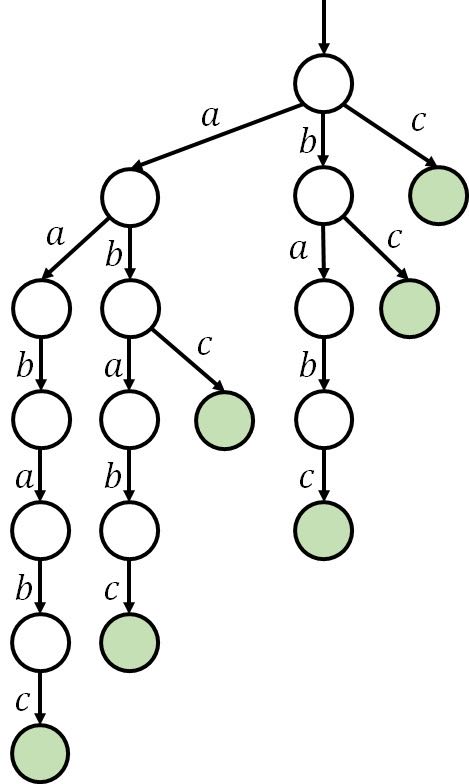
用 trie 树存字符串的每个后缀的其中一个用处为,可以快速地找到一个字符串
容易发现,这种 trie 树包含了很多浪费,如下图:
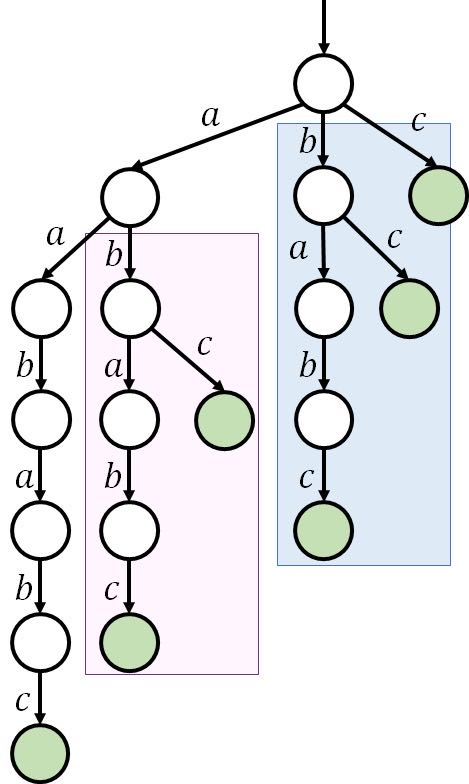
紫色的部分和蓝色的部分结构完全一样,所以可以从根节点直接连一个
endpos 集合与 parent tree
定义一个函数
另一种直观的理解方式为,我当前从字符串
我们发现,对于上面例子
于是我们可以得出一个结论:在 SAM 中,
我们显然不能暴力地去找每一个等价类,这就引出了一个新概念:parent tree。它建立了所有
还是以
对于
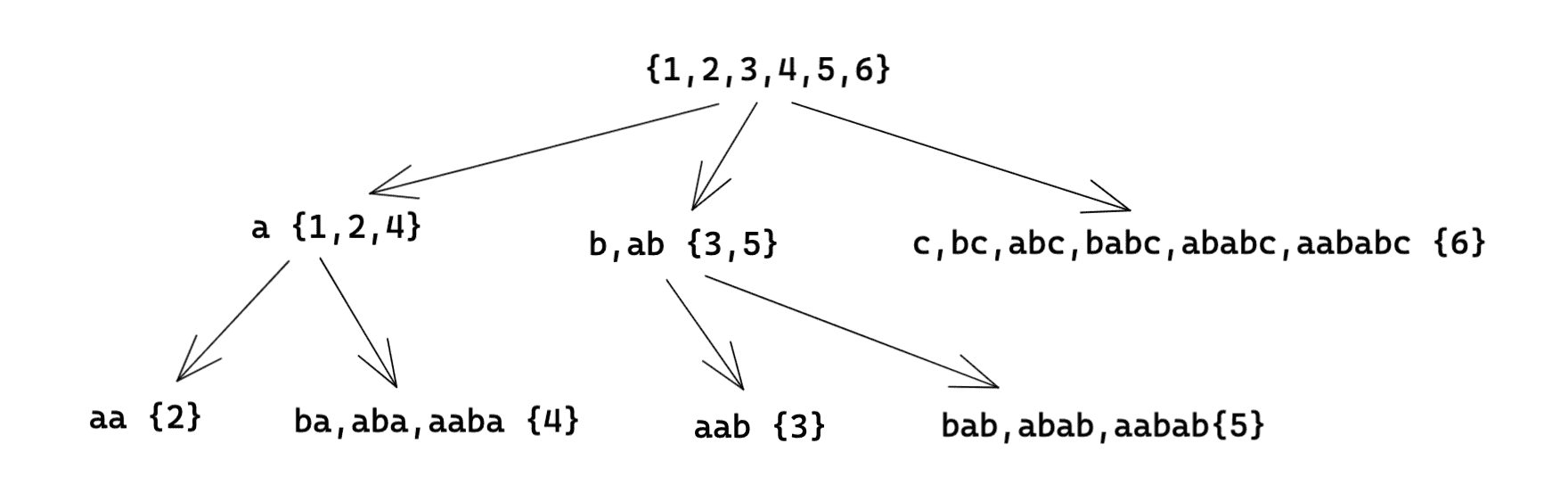
这里说一下对于这张图的感性理解:假如我走了一步,经过
通过感性理解可以发现,parent tree 有几个非常重要的性质:
- 一个点代表的若干个字符串为最长的字符串的后缀,且长度连续(不可能出现代表
- 一个节点的祖先为该节点字符串的后缀,且依次往上遍历可以遍历到所有后缀。
- 由性质 2 推出,一个节点的最短字符串长度为,父亲节点的最长长度
接下来考虑 parent tree 的节点数(即不同的等价类个数,也就是 SAM 的节点数)。由于叶子节点的集合元素个数为
构建 SAM
来到重头戏了!在这里,我们采取动态构造的方法,依次加入每个字符,并同时维护 parent tree 和 SAM。因为两者的节点一一对应,所以我们在同一个结构体里维护:
struct node {
int fa,nxt[26],len;
} sam[MAXN*2];
其中 sam[u].fa 表示 sam[u].nxt[ch] 表示 sam[u].len 表示 sam[sam[u].fa].len+1。
这里先把算法流程过一遍,有一个框架,后面再详细说明。
首先有根节点,这里设为
号节点。 加入字符的过程中,维护当前整个串对应的节点
。 加入一个字符
时,新建一个节点 表示整个串(也可能表示了其他串,但整串是最长的)。 从
开始在 parent tree 上往上爬,直到爬到一个节点 已经存在 的出边。在这之前,每个节点都没有 的出边,所以新建一个 的出边指向 。 如果爬完了 parent tree,每个节点都没有
的出边,则将 sam[cur].fa设为根。否则,设碰到的节点为,作如下判断:
- 如果
sam[p].len+1==sam[q].len,那么将sam[cur].fa设为,结束。 - 否则,新建一个节点
,信息与 完全相同,但 sam[r].len=sam[sam[q].fa].len+1,并将sam[q].fa和sam[cur].fa改为。接下来,让 继续往上爬,对于每个 改为 。 最后将当前整个串的节点
lst改为cur。
int cnt=1,lst=1;
void insert(int ch) {
int cur=++cnt,p=lst;
sam[cur].len=sam[lst].len+1;
for(;p&&!sam[p].nxt[ch];p=sam[p].fa)
sam[p].nxt[ch]=cur;
int q=sam[p].nxt[ch];
if(!q) sam[cur].fa=1;
else if(sam[p].len+1==sam[q].len) sam[cur].fa=q;
else {
int r=++cnt;
sam[r]=sam[q],sam[r].len=sam[p].len+1;
for(;p&&sam[p].nxt[ch]==q;p=sam[p].fa)
sam[p].nxt[ch]=r;
sam[q].fa=sam[cur].fa=r;
}
lst=cur;
}
看完肯定非常晕,但没关系,我们接下来通过一个例子,将每一步的原理解释清楚。
对于
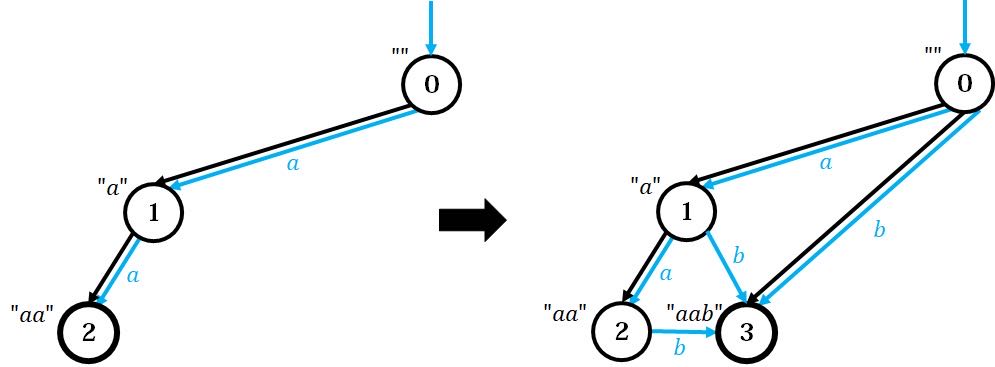
左图为加入前两个字符
我们当然不只是模拟过程,接下来进行解释:
根据 tree 的性质,在原图上往上爬一定能遍历原串所有的后缀,且是从长往短遍历。我们希望让新图也能存下新串的所有后缀,而新串的后缀等于原串后缀+字符
这里一直到根节点都不存在
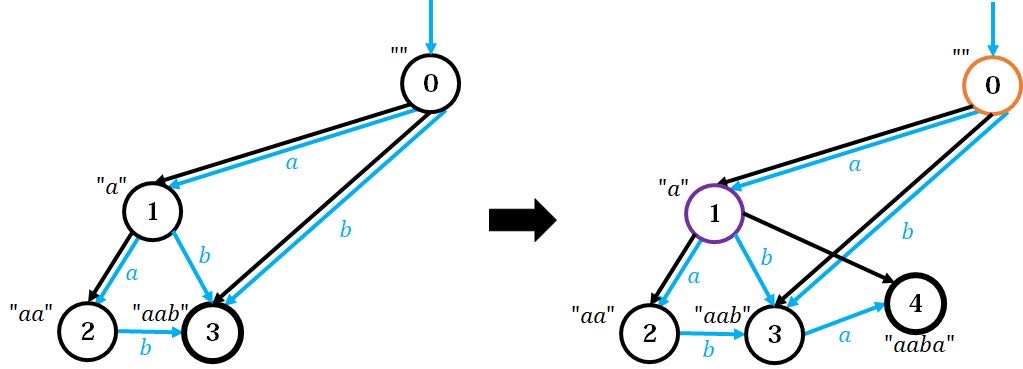
左图为加入
事情就是从这里开始奇怪的。这里的过程明显比上面难懂,解释如下:
考虑节点
跳到了节点
读到这里,可能还有一个疑问,为什么要求
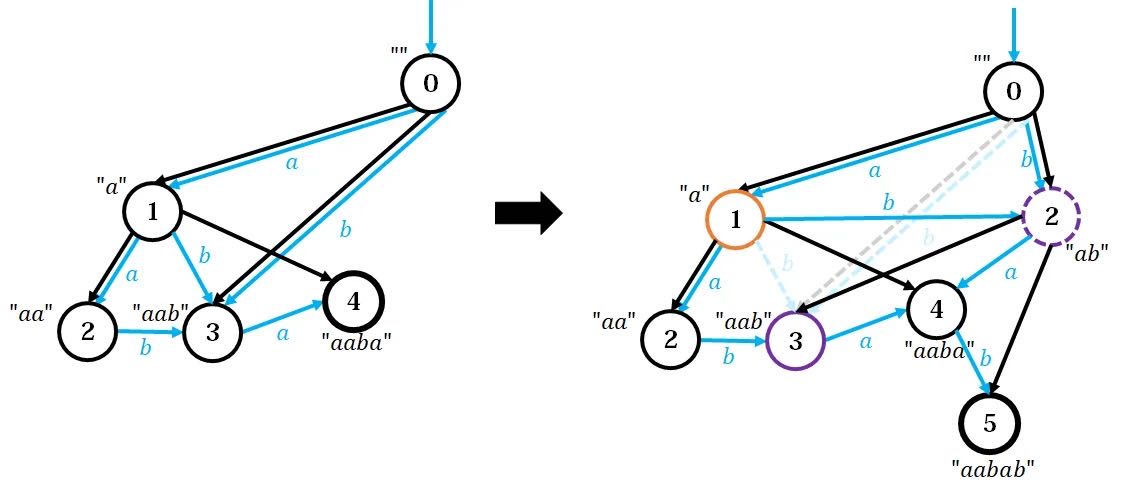
左图为添加
观察左图,找到原串的节点
接着沿着 tree 往上爬,找到节点
如果我们像上面一样,直接把新点
因为,
原来,在原串中
由于以前这两个等价,所以
此时,还要将
现在可以解释第二节最后的问题了:为什么
完结撒花! 如果有哪些部分没看懂或不清楚,强烈建议先对照图和算法流程模拟一遍,再看我的解析。个人认为绝对能理解(蜜汁自信)
应用
基础应用可以直接看 pecco 大佬的原文,讲得比较明白。这里着重说一下较难理解的最长公共子串。
要求
如果要求
更多神仙应用可参见 OI-wiki。
例题
由于作者很菜,所以这里只放链接,就不班门弄斧了。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步