
201871030106-陈鑫莲 实验三 结对项目—《D{0-1}KP 实例数据集算法实验平台》项目报告
| 项目 | 内容 |
|---|---|
| 课程班级博客链接 | 班级博客 |
| 这个作业要求链接 | 作业要求 |
| 我的课程学习目标 | 1.学会结对学习,体会结对学习的快乐 2.了解并实践结对编程 3.加深对D{0-1}问题的解法的理解 4.复习并熟悉PSP流程 |
| 这个作业在哪些方面帮助我实现学习目标 | 1.体验软件项目开发中的两人合作,练习结对编程 2.掌握Github协作开发程序的操作方法 3.进一步加强GitHub的练习与使用 4.使用并熟悉java语言的编写 |
| 结对方学号-姓名 | 201871030103-陈荟茹 |
| 结对方本次博客作业链接 | 结对方本次博客作业链接 |
| 本项目Github的仓库链接地址 | 仓库链接 |
1、实验目的与要求
(1)体验软件项目开发中的两人合作,练习结对编程(Pair programming)。(2)掌握Github协作开发程序的操作方法。
2、实验内容与步骤
任务1
已阅读《现代软件工程—构建之法》第3-4章内容。代码风格规范、代码设计规范、代码复审、结对编程概念如下:
-
代码风格规范: 主要是文字上的规定,看似表面文章,实际上很重要。代码风格的原则是:简明,易读,无二义性。代码风格规范主要涉及以下几个方面的内容:缩进,行宽,括号,断行与空白的{}行,分行,命名,下划线,大小写,以及注释。
-
代码设计规范:代码设计规范不光是程序书写的格式问题,而且牵涉到程序设计,模块之间的关系,设计模式等方方面面。具体为以下几个方面:函数,goto,错误处理以及如何处理C++中的类。
-
代码复审:代码复审的正确定义是看代码是否在“代码规范”的框架内正确地解决了问题。主要有自我复审,团队复审以及同伴复审三种方式。代码复审的主要目的:在项目开发时,不管多厉害的开发者都会或多或少地犯一些错误,有欠考虑的地方。而且越是项目后期发现的问题,修复的代价就越大,代码复审正是要在早期发现并修复这些问题,另外,在代码复审时的提问与回应能帮助团队成员相互了解。
-
结对编程:结对编程是指两人结对编程,一对程序员肩并肩,平等地,互补地进行开发工作。
任务2
2-1.结对方博客链接
结对方博客链接:博客链接
2-2.结对方Github项目仓库链接
结对方Github项目仓库链接:仓库链接
2-3.博客评论

2-4.代码核查表
1.克隆结对方项目源码到本地机器,阅读并测试运行代码,参照《现代软件工程—构建之法》4.4.3节核查表复审同伴项目代码并记录,克隆步骤如下:
(1)进入原作者的仓库,如图2:
(2)点击clone,复制链接,如图3:
(3)输入git clone 原作者的链接,如图4:
2.代码核查表具体内容如下:
-概要部分
(1)代码能符合需求和规格说明么?
答:基本符合,就是有些代码可能是因为平台的问题,有些语句显示时有一点问题。
(2)代码设计是否有周全的考虑?
答:在switch语句使用时没有运用Default。
(3)代码可读性如何?
答:可读性很好。对类,方法还有变量都做了相关注释。
(4)代码容易维护么?
答:比较容易 。
(5)代码的每一行都执行并检查过了吗?
答:是的,检查过。
-设计规范部分
(1)设计是否遵从已知的设计模式或项目中常用的模式?
答:是。
(2)有没有硬编码或字符串/数字等存在?
答:有一部分。
(3)代码有没有依赖于某一平台,是否会影响将来的移植(如Win32到Win64)
答:没有依赖
(4)开发者新写的代码能否用已有的Library/SDK/Framework中的功能实现?在本项目中是否存在类似的功能可以调用而不用全部重新实现?
答:可以实现,不存在
(5)有没有无用的代码可以清除?(很多人想保留尽可能多的代码,因为以后可能会用上,这样导致程序文件中有很多注释掉的代码,这些代码都可以删除,因为源代码控制已经保存了原来的老代码。)
答:没有。
-代码规范部分
(1)修改的部分符合代码标准和风格么(详细条文略)?
答:符合代码标准和风格。
-具体代码部分
(1)有没有对错误进行处理?对于调用的外部函数,是否检查了返回值或处理了异常?
答:有错误处理,并且处理了异常。
(2)参数传递有无错误,字符串的长度是字节的长度还是字符(可能是单/双字节)的长度,是以0开始计数还是以1开始计数?
答:无错误,字符串的长度是字节的长度,以0开始计数。
(3)边界条件是如何处理的?Switch语句的Default是如何处理的?循环有没有可能出现死循环?
答:针对需要的操作进行Switch,在目前代码中没有发现Default。经测试代码不会出现死循环。
(4)有没有使用断言(Assert)来保证我们认为不变的条件真的满足?
答:没有。
(5)对资源的利用,是在哪里申请,在哪里释放的?有没有可能导致资源泄露(内存、文件、各种GUI资源、数据库访问的连接,等等)?有没有可能优化?
答:资源都是在类中申请,在类中释放,对资源都有一定的控制,不会导致资源泄露。
(6)数据结构中是否有无用的元素?
答:没有。
-效能
(1)代码的效能(Performance)如何?最坏的情况是怎样的?
答:经检查,代码正确,并且功能都已实现,暂无错误。
(2)代码中,特别是循环中是否有明显可优化的部分(C++中反复创建类,C#中 string 的操作是否能用StringBuilder 来优化)?
答:循环中暂无,但在柱状图的设置部分需要优化。
(3)对于系统和网络调用是否会超时?如何处理?
答:不会超时。
-可读性
(1)代码可读性如何?有没有足够的注释?
答:代码可读性较好,对类,方法和变量都进行了注释。
-可测试性
(1)代码是否需要更新或创建新的单元测试?还可以有针对特定领域开发(如数据库、网页、多线程等)的核查表。
答:希望用较多的数据对代码进行测试。
2-5.结对方项目仓库中的Fork、Clone、Push、Pull request、Merge pull request日志数据
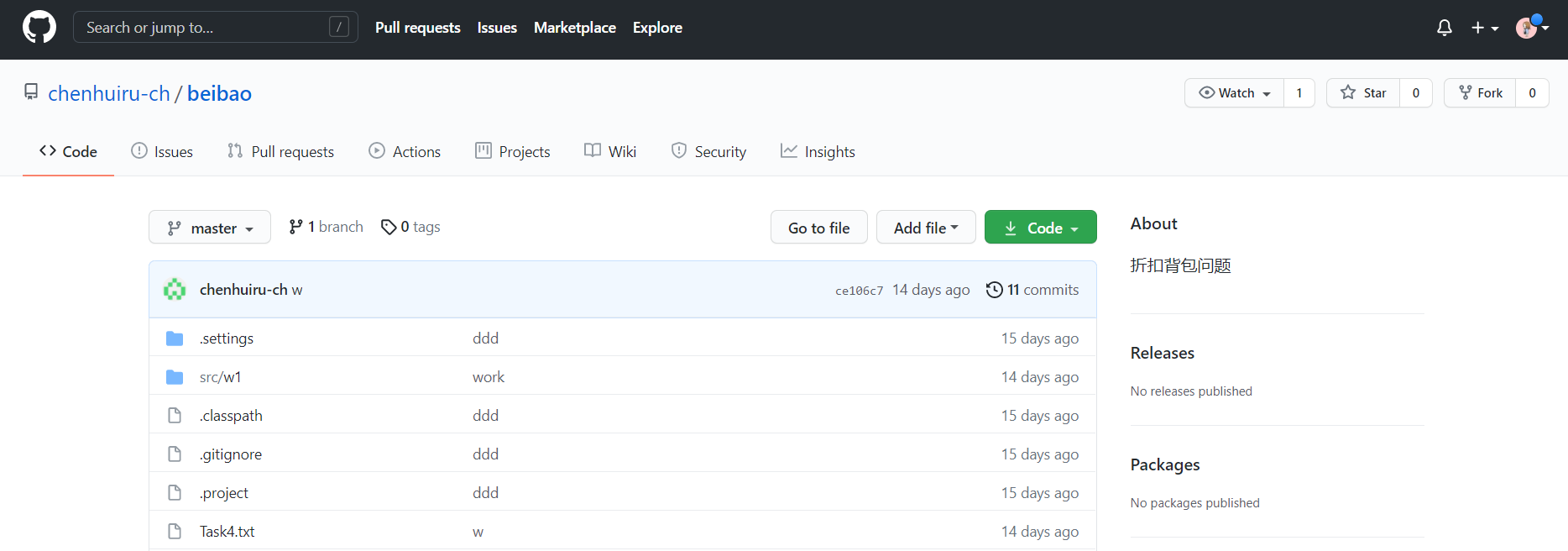
1.Fork
(1)点击原作者仓库github右上角的fork按钮,就会在你自己的github中新建一个同名仓库,如图5-1和5-2:
2.Clone
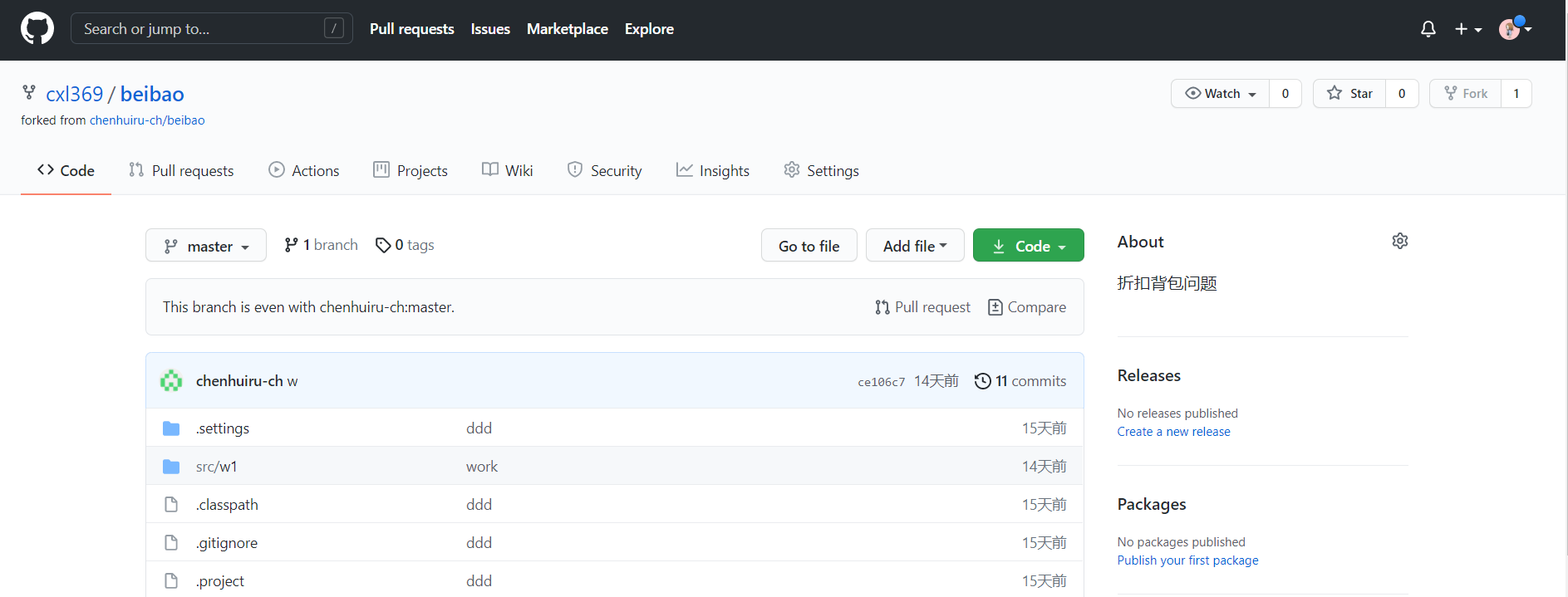
(1)进入自己的页面,打开原作者的同名仓库,如图6:
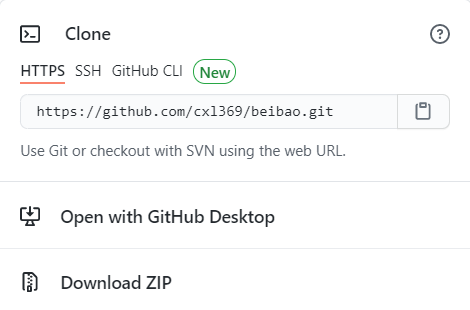
(2)clone fork仓库到本地,如图7:
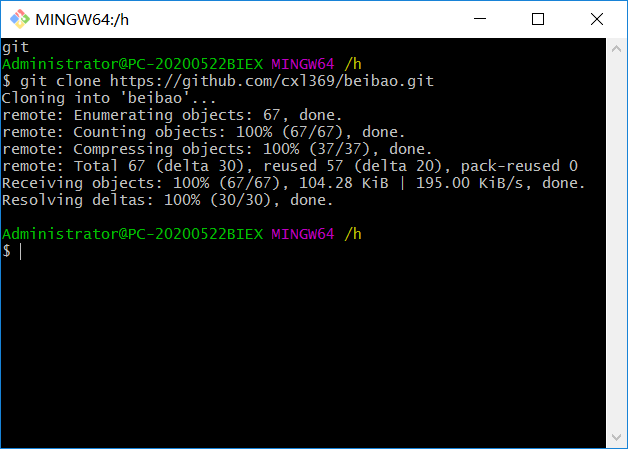
(3)打开git bush here,输入:git clone http://github.com/cxl369/beibao.git 的地址,如图8:
3.本地库与原始库关联
(1)进入我们的项目文件夹: cd beibao,如图9:

(2)添加与原始库的关联,命名为upstream,此地址是原项目开发者的项目主页上的clone的地址:这是专门用来与主开发者保持相同进度的方法,如图10:

(3)从原始库中抓取最新的更新,如图11:

4.Push过程
(1)把Test文件夹下面的文件都添加进来,查看,如图12:
(2)git commit -a -m"提交信息",如图13:

(3)git push https://github.com/cxl369/beibao.git ,如图14:
5.Pull request
(1)在项目主页上,如图15:

(2) 代码目录左上方有如图所示的图表,点击拉取要求的图标,然后就可以比较你的版本和源中代码的差别,然后就可以选择发送一个Pull request给主开发者,添加修改的原因描述。然后就等待主开发者去merge了,如图16:

任务3
3-1.需求分析
设计WEB页面,背包问题(Knapsack Problem,KP)是NP Complete问题,也是一个经典的组合优化问题,有着广泛而重要的应用背景。{0-1}背包问题({0-1 }Knapsack Problem,{0-1}KP)是最基本的KP问题形式,在此之前,学习过{0-1}背包问题的动态规划算法以及回溯法,本实验中要求读取所给TXT文件的有效D{0-1}KP数据,将其读取的有效数据以重量为横轴、价值为纵轴的数据散点图,要求对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序,即递减排序,任务3-4是选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位)。
3-2.功能设计
-基本功能:
(1)设计Web页面;
(2)可正确读入实验数据文件的有效D{0-1}KP数据;
(3)能够绘制任意一组D{0-1}KP数据以重量为横轴、价值为纵轴的数据散点图;
(4)能够对一组D{0-1}KP数据按项集第三项的价值:重量比进行非递增排序;
(5)用户能够自主选择动态规划算法、回溯算法求解指定D{0-1} KP数据的最优解和求解时间(以秒为单位);
3-3.核心代码展示
1.动态规划法:
for (int i=1; i <mvaluel.length;i++) {
for (int j=1; j < mvaluel[i].length; j++) {
//如果物品的重量小于当前背包的容量
if (weight[i - 1] > j) {
mvaluel[i][j] = mvaluel[i - 1][j];
} else {//如果物品的重量大于当前背包的容量
//如果上一次最大价值<当前物品的价值+上一次重量-当前物品重量的价值总和。
if (mvaluel[i - 1][j] < value[i - 1] + mvaluel[i - 1][j - weight[i - 1]]) {
mvaluel[i][j] = value[i - 1] + mvaluel[i - 1][j - weight[i - 1]];
wup[i][j] = 1;//将物品放入背包
} else {
mvaluel[i][j] = mvaluel[i - 1][j];
}
}
}
}
2.回溯法:
// 当没有物品可以放入背包时,当前价值为最优价值
if (i >= n) {
bestValue = currValue;
return bestValue;
}
// 首要条件:放入当前物品,判断物品放入背包后是否小于背包的总承重
if (currWeight + bags[i].getWeight() <= totalWeight) {
// 将物品放入背包中的状态
currWeight += bags[i].getWeight();
currValue += bags[i].getValue();
// 选择下一个物品进行判断
bestValue = solve(i + 1);
// 将物品从背包中取出的状态
currWeight -= bags[i].getWeight();
currValue -= bags[i].getValue();
}
// 次要条件:不放入当前物品,放入下一个物品可能会产生更优的价值,则对下一个物品进行判断
// 当前价值+剩余价值<=最优价值,不需考虑右子树情况,由于最优价值的结果是由小往上逐层返回,
// 为了防止错误的将单位重量价值大的物品错误的剔除,需要将物品按照单位重量价值从大到小进行排序
if (currValue + getSurplusValue(i + 1) > bestValue) {
// 选择下一个物品进行判断
bestValue = solve(i + 1);
}
return bestValue;
}
3.遗传算法:
/*
计算种群适应度
*/
public void caculteFitness(){
bestFitness=population.get(0).getFitness();
worstFitness=population.get(0).getFitness();
totalFitness=0;
for (Chromosome g:population) {
//changeGene(g);
setNowGenome(g);
if(g.getFitness()>bestFitness){
setBestFitness(g.getFitness());
if(y<bestFitness){
y=g.getFitness();
}
setIterBestFit(g);
}
if(g.getFitness()<worstFitness){
worstFitness=g.getFitness();
}
totalFitness+=g.getFitness();
}
averageFitness = totalFitness / popSize;
//因为精度问题导致的平均值大于最好值,将平均值设置成最好值
averageFitness = averageFitness > bestFitness ? bestFitness : averageFitness;
}
/*
遗传算法GA流程
*/
public void geneticAlgorithProcess(){
generation=1;
init();
while(generation<iterNum){
evolve();
print();
generation++;
}
}
3-4.程序运行
一、注册登录页面,输入相应的用户名和密码,点击“立即登录”,跳转到后台页面,如图17:
二、后台页面,如图18:
1.散点图部分
(1)输入相应的文件名和数据行数,点击“搜索”,显示出具体的散点图页面,如图19:
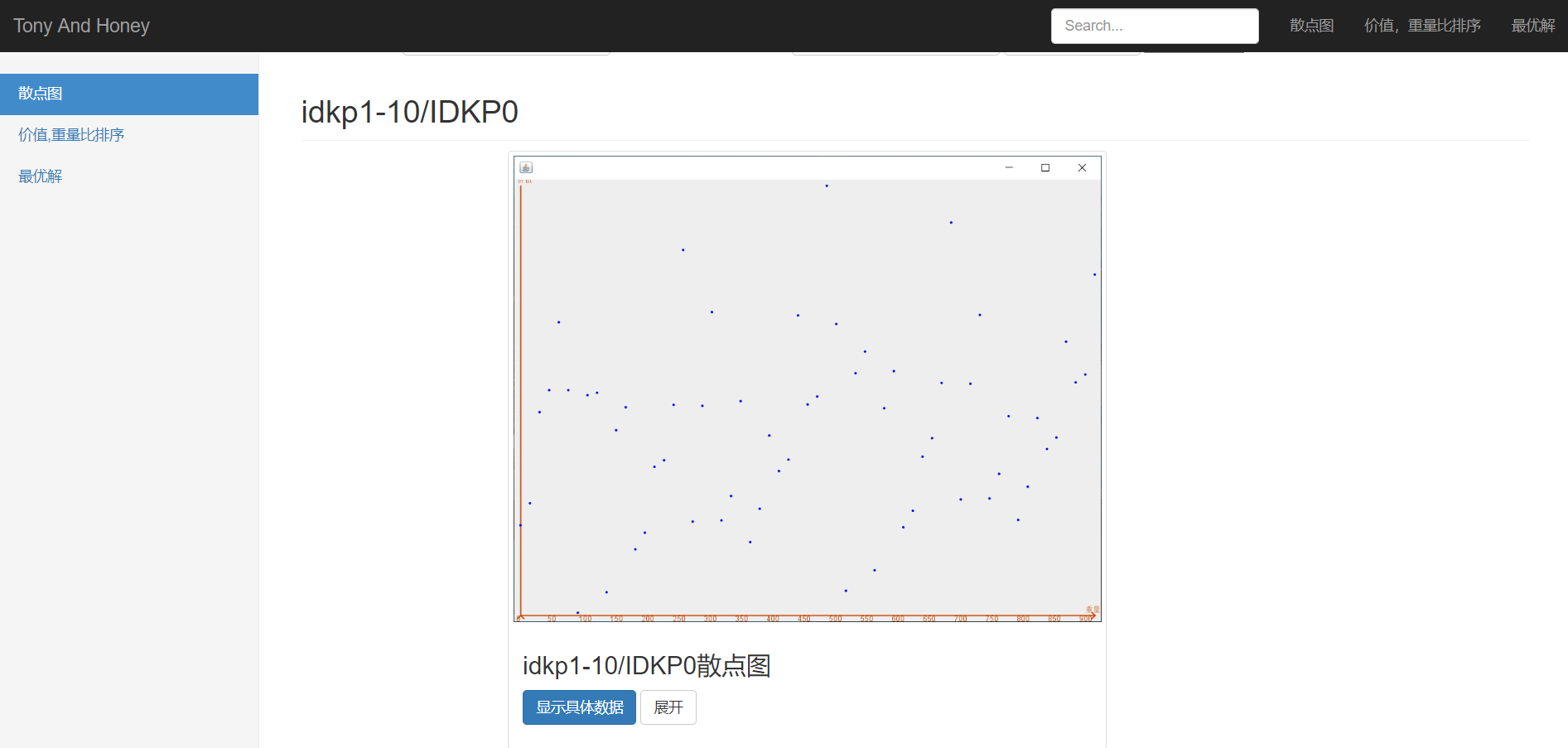
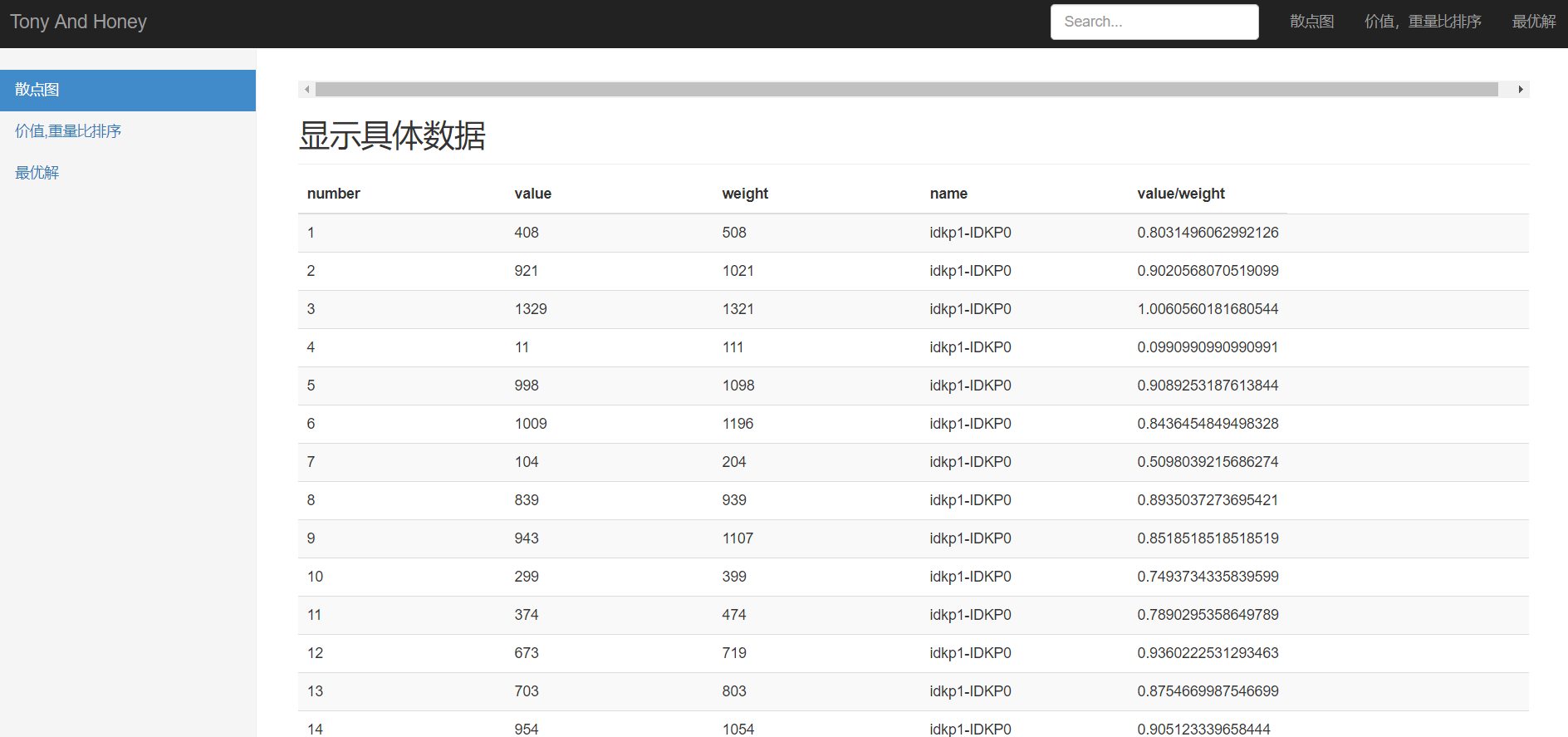
(2)点击“展开”按钮,显示具体数据(部分),如图20:
2.排序部分
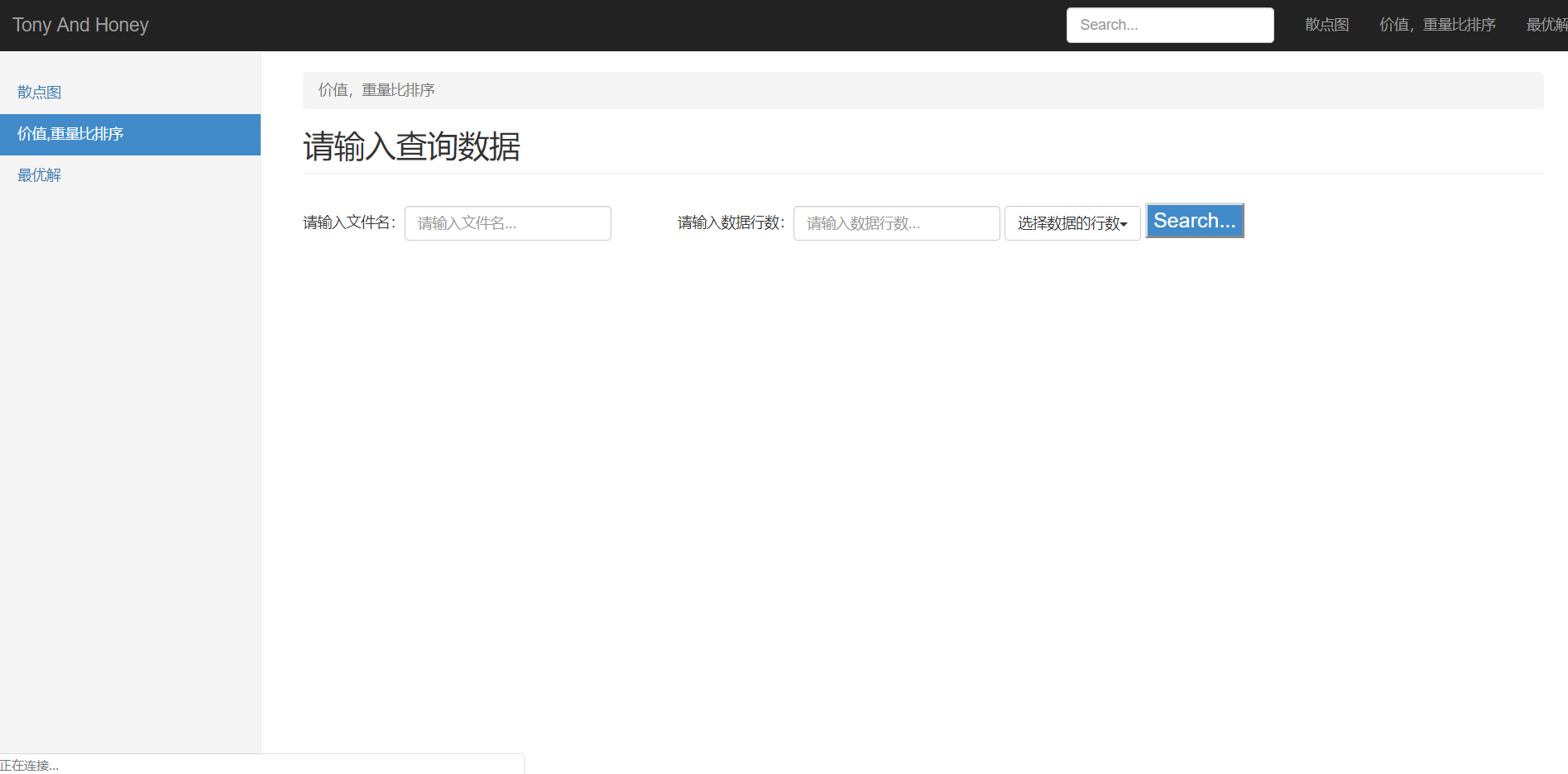
(1)输入相应的文件名和数据行数,点击“搜索”,如图21:
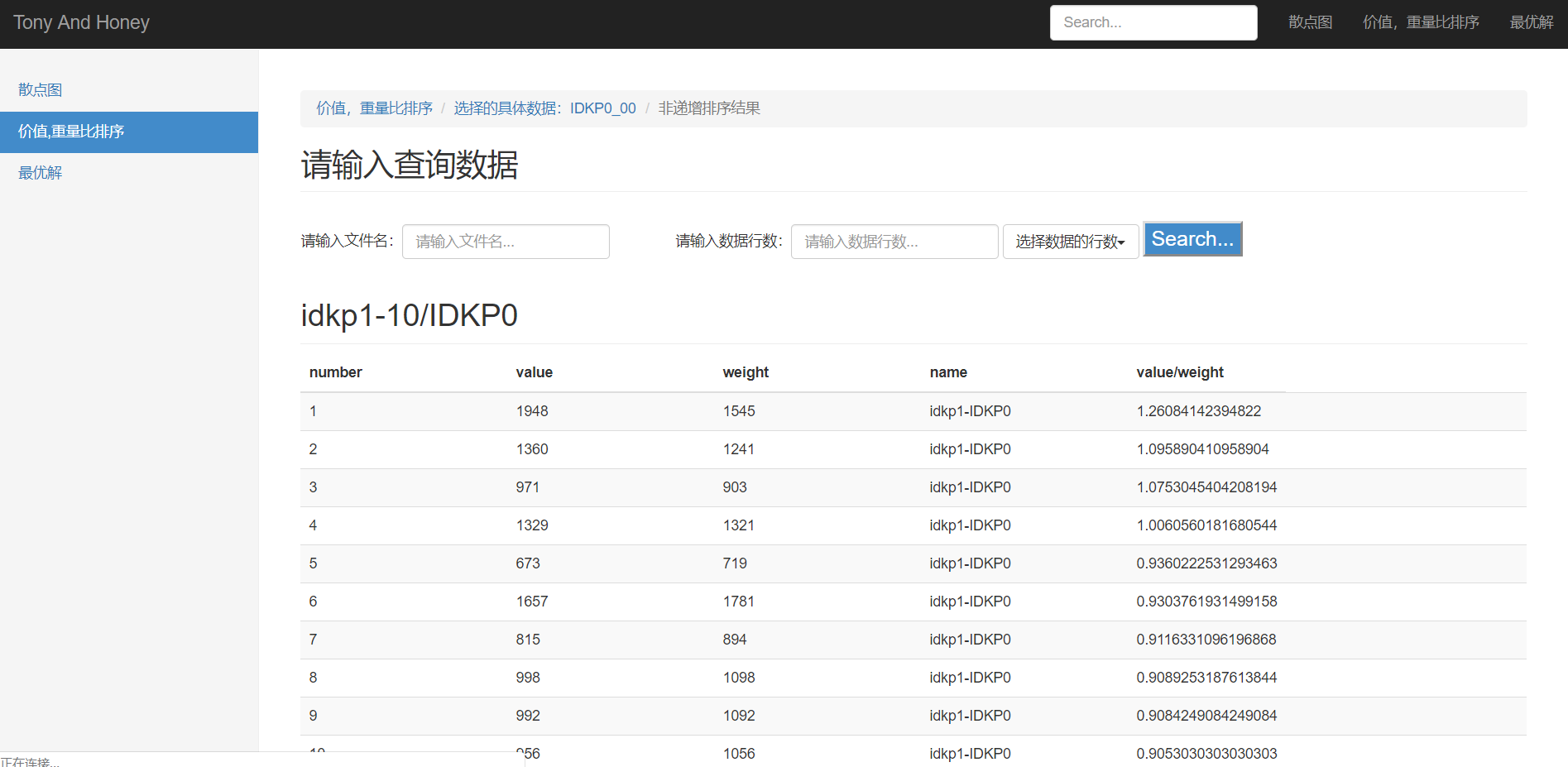
(2)下图为未排序数据页面,点击本页面中的“显示排序结果”,显示出具体的所需要的未排序数据(部分),跳转至排序成功页面如图22:

(3)排序成功页面,如图23:
3.最优解部分
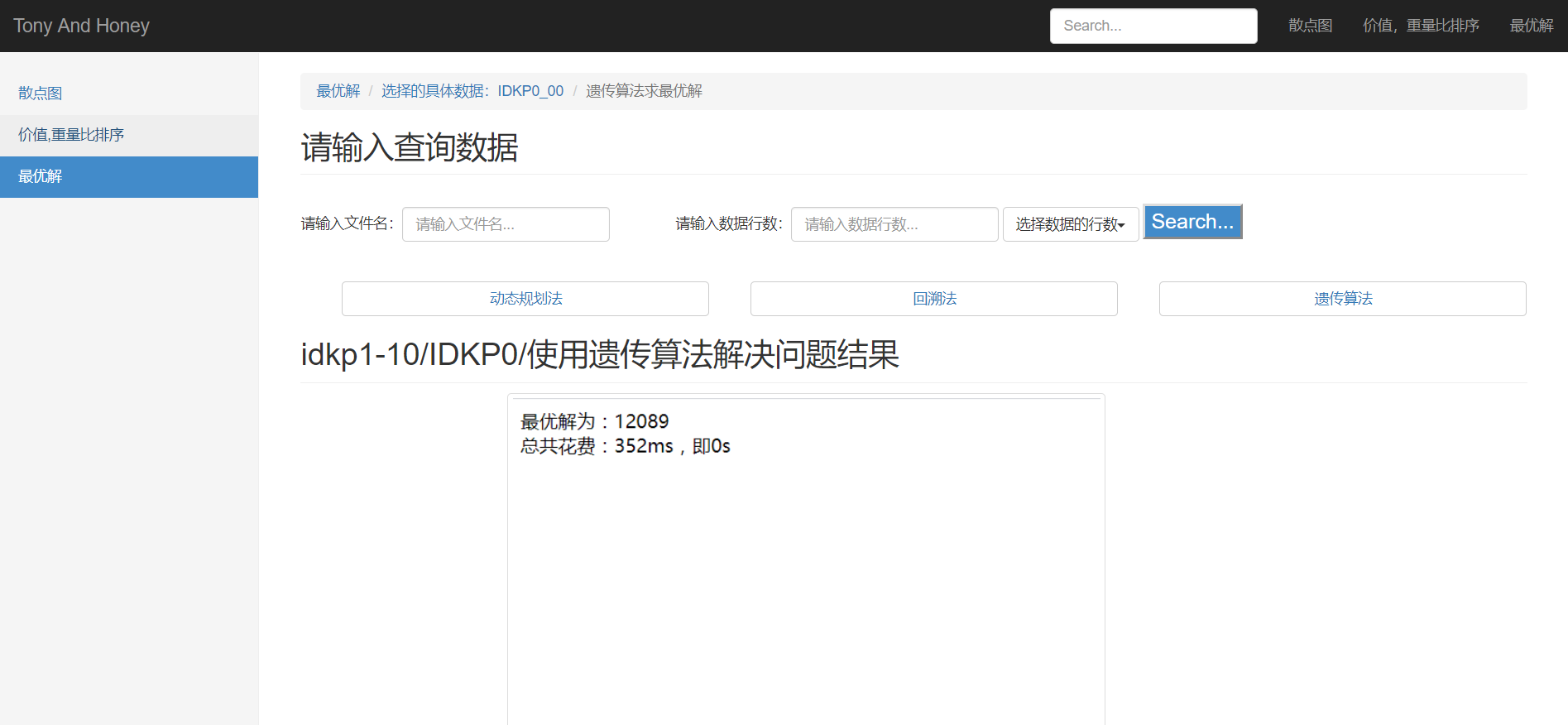
(1)输入相应的文件名和数据行数,点击“搜索”,如图24:
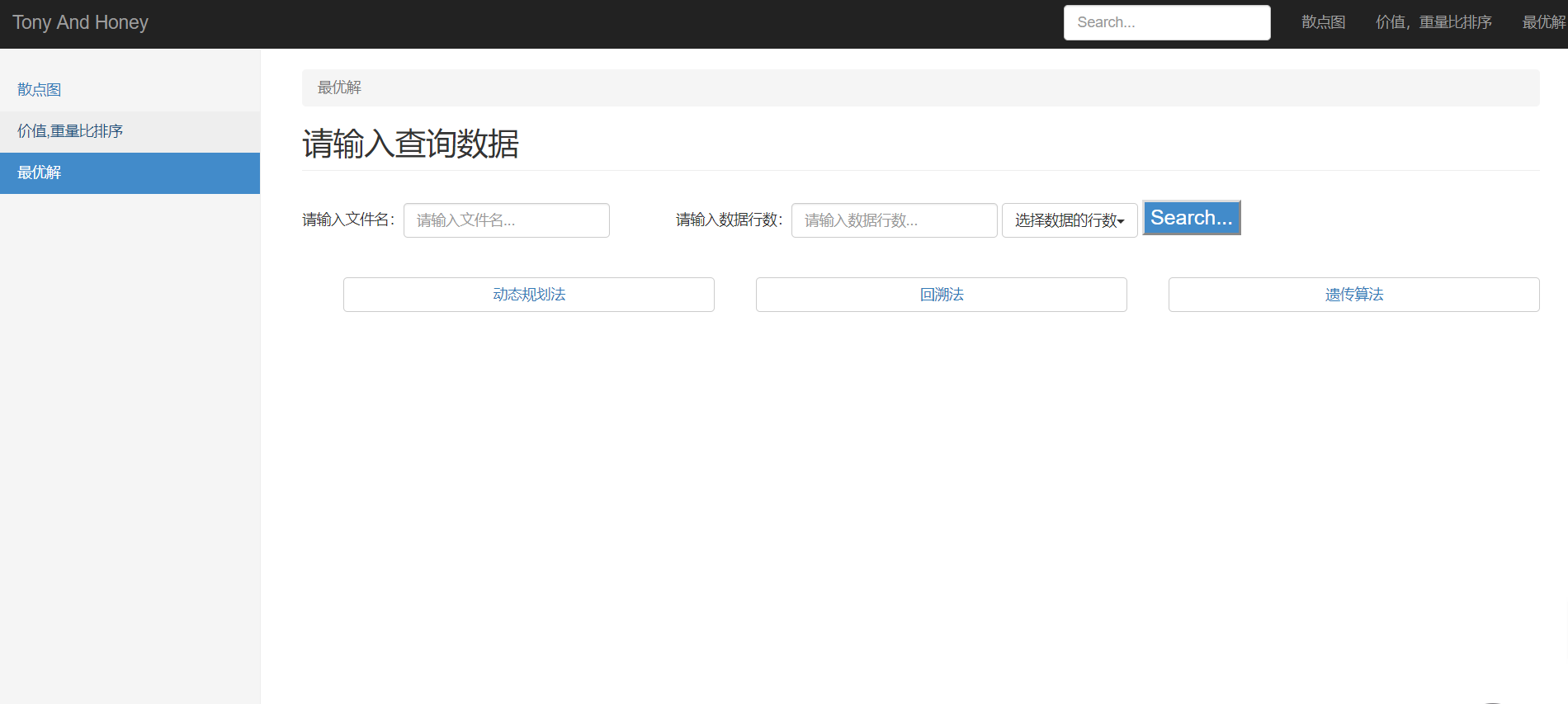
(2)显示具体测试数据,此时我们可用:动态规划法、回溯法以及遗传算法对所选择的数据进行最优解求解,如图25:
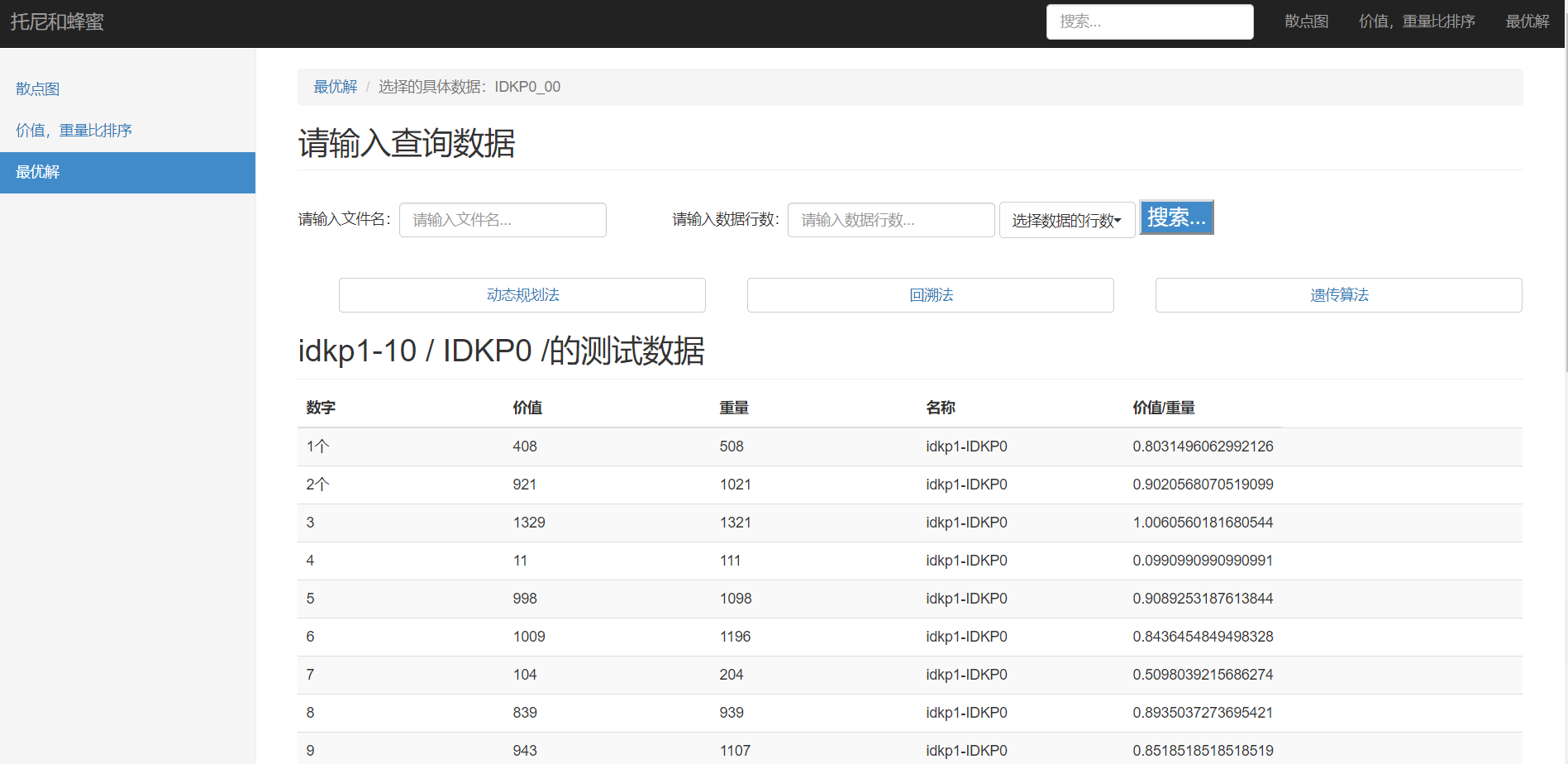
a.动态规划法求解结果,如图26:
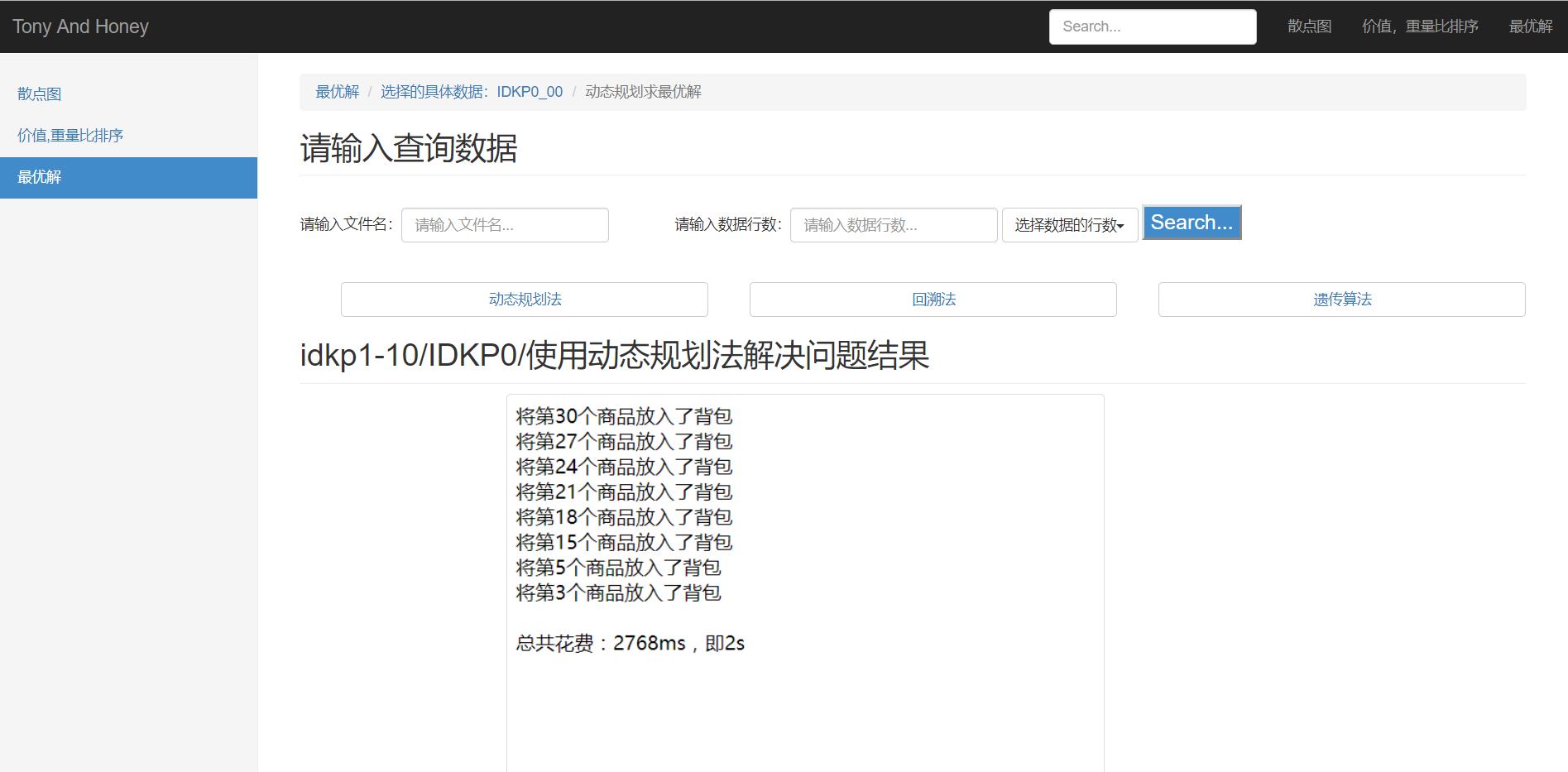
b.回溯法求解结果,如图27:
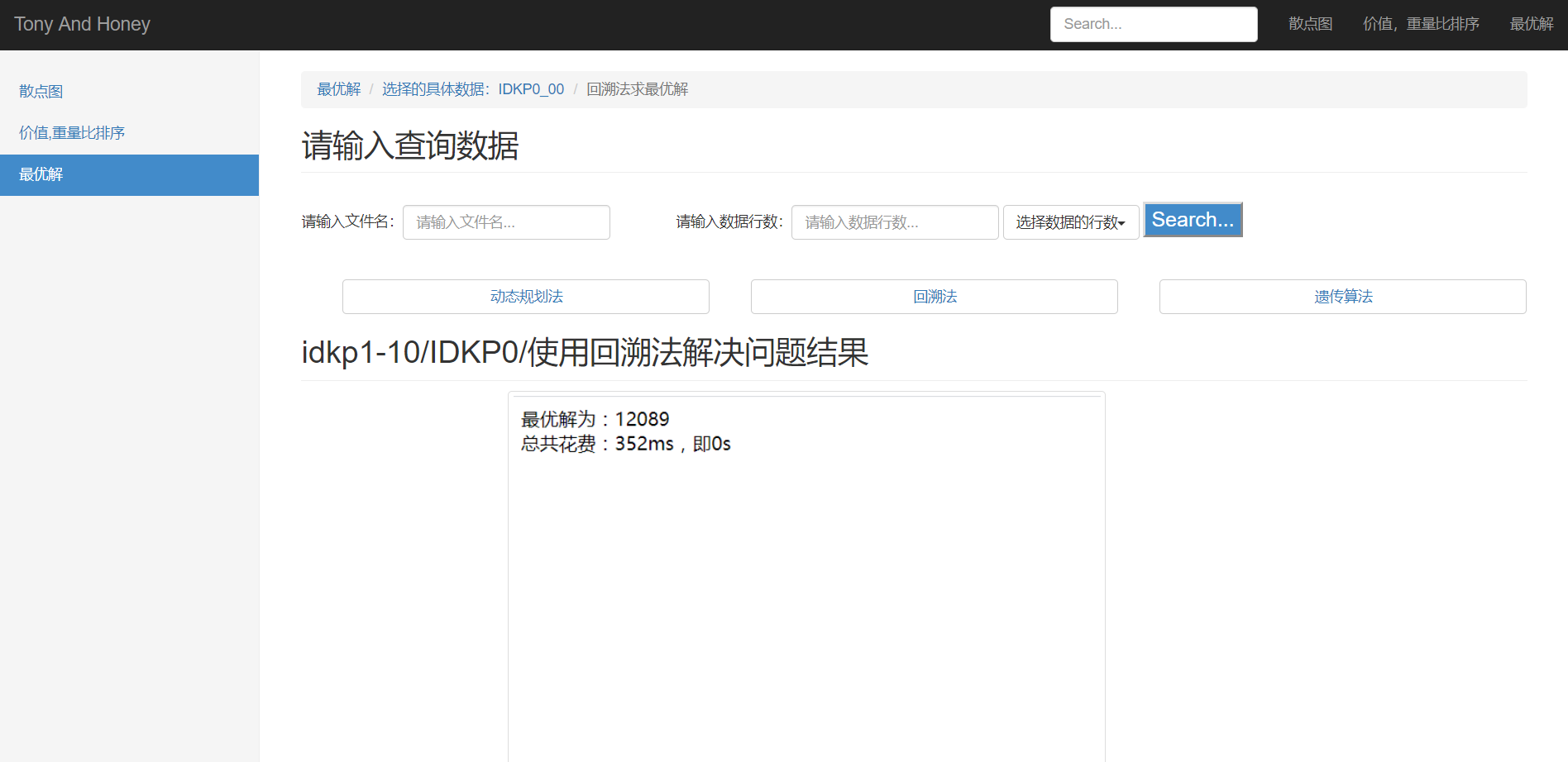
c.遗传算法求解结果,如图28:
三、数据库部分
1.MySql部分
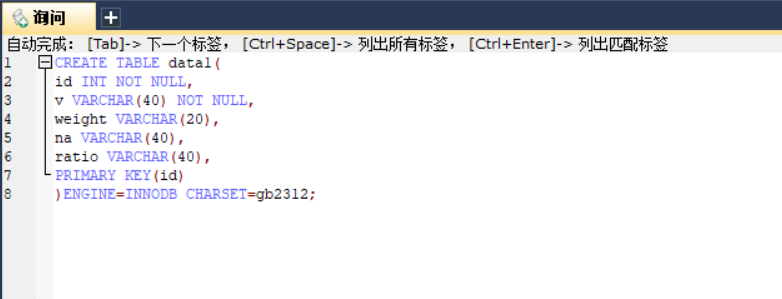
(1)在数据库soft中创建表data1,如图29:
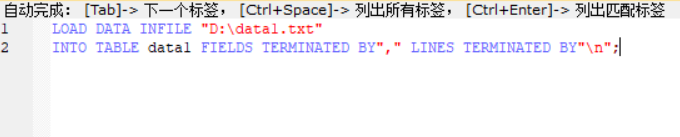
(2)将文件data1.txt中的数据导入到表data1中,如图30:
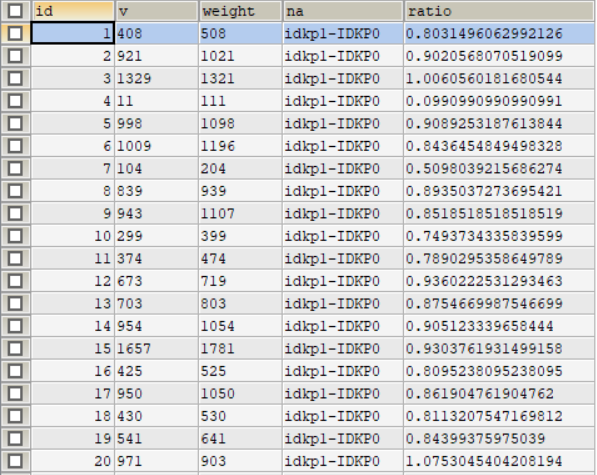
(3)导入成功,显示如下数据,如图31:
1.Eclipse部分,步骤如下:
(1)Data1.java:根据数据表定义一个Java bean
(2)Data1DAO.java:Product的数据访问类
(3)dbtool.java:驱动注册+得到连接对象
(4)dbServlet.java:对表中数据进行操作
(5)在具体的jsp页面中,代码块如图32-1:

(6)在具体的jsp页面中,代码块如图32-2:
3-5.结对过程
(1)线上交流,如图:33
(2)线下交流,如图34:

3-6.PSP展示
| PSP | 任务内容 | 计划共完成需要的时间(min) | 实际完成需要的时间(min) |
|---|---|---|---|
| Planning | 计划 | 8 | 30 |
| Estimate | 估计这个任务需要多少时间,并规划大致工作步骤 | 8 | 30 |
| Development | 开发 | 298 | 410 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 30 |
| Design Spec | 生成设计文档 | 15 | 25 |
| Design Review | 设计复审 (和同事审核设计文档) | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 3 | 5 |
| Design | 具体设计 | 35 | 40 |
| Coding | 具体编码 | 155 | 200 |
| Code Review | 代码复审 | 15 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 45 | 60 |
| Reporting | 报告 | 9 | 11 |
| Test Report | 测试报告 | 3 | 5 |
| Size Measuremen | 计算工作量 | 3 | 2 |
| Postmortem & Process Improvement Plan | 事后总结 ,并提出过程改进计划 | 3 | 4 |
3-7.小结感受
对于此次结对编程实验,我有如下感受及体会:第一次接触结对编程,对于结对编程的整体感受总的来说是利大于弊的,即有1+1>2的效果。
我认为或许结对编程并不适用于简单的写代码的工作,结对编程更适用于解决一些方向性的问题,因为在编程时,每个人的思想不同可能用到的方法及语句也就不同,所以难免会产生分歧与不一致,但是,两个人的思想可能会碰撞出新的火花,有时候还可以找到更适合、更节省空间与时间的方法与算法。在结对编程中,双方的互动目的在于开启思路,避免单独编程时思维容易阻塞的情况,有时候一个人在写代码时,难免会陷入僵局出不来,而两个人合作缺可以解决不这个问题,有时候对方的一句话可以启发自己换一种思考方式,从而高效地解决问题。
在自己编程过程时不难发现,编程耗时最多的方面就是debug。在我们得出设计思路,并将它们初次转化成代码后,编程之路其实才走了一小段。由于个人的疏忽,输入的错误,以及设计思路的偏差,往往会让我们的程序陷入无止尽的bug泥潭中,难以挣脱,这会消耗我们大量的时间。 而结对编程的好处就在于此。由于身边有个领航员角色的存在,在编写代码时,一旦出现输入错误,就会有人及时的提醒。并且,在设计代码时,有个同伴可以一起讨论,融合两个人不同的见解和观点,我们往往可以得出更加准确且更加高效的设计思路。这一切都为我们在完成代码后的debug过程省去了大量的时间。
总体来说,结对编程可以很大程度上提高编程效率,而且两人轮流编程,不会太过疲惫,因此十分适合敏捷开发。如果未来我们从事软件开发的工作,我们会十分乐于进行结对编程,因为这会极大的改善我们的编程体验,是编程不再那么枯燥,debug之路也不会那么恐怖。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号