
Python+Selenium爬取招聘岗位详情信息------2023年2月有效!!!
最近学习了一些爬虫的知识,尝试爬取招聘类网站的岗位信息,由于这种类型的网站不像某瓣电影一样,它的内容可能比较敏感,开发者小哥哥们可能不太愿意我们过度爬取他们的数据用于某些不利用途,因此会有许多反扒机制(虽然这篇文章也没有解决任何一个[doge]),但是还是记录一下吧(目前还有效2023年2月)
本文章包含两个网站的爬取方式:
- 某程无忧
- 辣沟网
1.某程无忧
开始试过用request模块静态获取url,然后发现那样获取不到数据,于是改用selenium自动化工具,它可以模拟浏览器的点击,刷新,获取url等一系列动作,但速度往往不如静态获取快。
- 首先我们可以观察网站招聘信息特点(输入“大数据”关键词为例)
每一页有50条相关数据,点击上图的黄圈标注可以实现翻页;
我们现在的目标是要获取所有相关职位的详情信息,因此需要从上图的页面中获得详情页的url,
from selenium import webdriver
import csv
from selenium.webdriver.common.by import By
import time
# 创建结果储存文件,将结果保存到data.csv文件中
f = open('./data.csv', 'a', newline='')
writer = csv.writer(f)
def outpage(driver,start_page):

driver.get(url)
time.sleep(8)
driver.find_element(By.XPATH,'//*[@id="jump_page"]').clear()
driver.find_element(By.XPATH,'//*[@id="jump_page"]').send_keys(start_page)
driver.find_element(By.XPATH,'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[3]/div/div/span[3]').click()
time.sleep(6)
for page in range(60):
for cnt in range(1,51):
job=driver.find_element(By.XPATH,'/html/body/div/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div[{}]/a'.format(cnt))
job_href=job.get_attribute("href")
company_name=driver.find_element(By.XPATH,'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div[{}]/div[2]/a'.format(cnt)).text
company_type=driver.find_element(By.XPATH,'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[2]/div/div[2]/div[1]/div[{}]/div[2]/p[2]'.format(cnt)).text
li=[job_href,company_name,company_type]
writer.writerow(li)
time.sleep(2)
try:
driver.find_element(By.XPATH,'//*[@id="app"]/div/div[2]/div/div/div[2]/div/div[1]/div[2]/div/div/div/a').click() #找到">"翻页按钮并点击
except:
time.sleep(5)
time.sleep(5)
# 主函数:启动浏览器并登录爬取信息
def main():
## 调用Microsoft Edge浏览器
options = webdriver.EdgeOptions()
options.add_argument(
"--disable-blink-features=AutomationControlled") # 就是这一行告诉chrome去掉了webdriver痕迹,令navigator.webdriver=false,极其关键
# 还有其他options配置,此处和问题无关,略去
driver = webdriver.Edge(options=options)
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
driver.execute_script(script)
driver.set_page_load_timeout(35)
start_page=input("enter your start page(at least 1):")
outpage(driver,start_page)
# 调用函数进行数据爬取
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36 Edg/109.0.1518.70'}
main()
f.close()
这样代码执行之后,前3000条的公司名,公司类型,详情页url就会存储在data.csv中了,上述代码中有个start_page的参数,这个参数的意义在于【当你的程序由于网站封ip等其他原因被打断时,你可以手动看看自己的程序已经爬了几页,下次启动就可以page++开始,hhh】
- 获得3000条详情页url后,在下面的程序中请求这一系列url,
from selenium import webdriver
import codecs
import csv
from selenium.webdriver.common.by import By
import time
import random
from selenium.webdriver import ActionChains
f = open('./result.csv', 'a', newline='')
writer = csv.writer(f)
import pandas as pd
def slide(driver):
slider = driver.find_element_by_id('nc_1_n1z')
action_chains=ActionChains(driver)
action_chains.click_and_hold(slider)
action_chains.pause(2)
action_chains.move_by_offset(290,0)
action_chains.pause(2)
action_chains.move_by_offset(10, 0)
action_chains.pause(2)
action_chains.release()
action_chains.perform() # 释放滑块
time.sleep(5)
def func(driver):
df = pd.read_csv('./data.csv',encoding='utf-8')
cnt = 100
for index, row in df.iterrows():
url=row['job_href']
if not url.startswith("该网站官网"):
continue
else :
driver.get(url)
#1.该详情页存在有效信息
if not driver.find_elements_by_class_name("bname")==[] and driver.find_elements_by_class_name("bname")[0].text == "职位信息":
job_name = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/div/div[1]/h1').text
salary = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/div/div[1]/strong').text
fuli = driver.find_elements(By.XPATH, '/html/body/div[2]/div[2]/div[2]/div/div[1]/div/div/span')
fl = []
for item in fuli:
fl.append(item.text)
place = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/div/div[1]/p').text.split(' |')[0]
job_info = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[3]/div[1]/div').text
company_name = row['company_name']
company_type = row['company_type']
li = [job_name, salary, company_name, company_type, fl, place, job_info]
writer.writerow(li)
time.sleep(random.randrange(2,3, 1))
#2.该详情页以停止招聘
elif not driver.find_elements_by_class_name("bname")==[] and driver.find_elements_by_class_name("bname")[0].text == "热门职位推荐":
continue
#3.遇到滑块验证,调用slide(driver)
else:
slide(driver)
def main():
## 调用Microsoft Edge浏览器
options = webdriver.EdgeOptions()
options.add_argument(
"--disable-blink-features=AutomationControlled") # 就是这一行告诉chrome去掉了webdriver痕迹,令navigator.webdriver=false,极其关键
# 还有其他options配置,此处和问题无关,略去
# options.add_argument("--proxy-server=https://117.41.38.16:9000")
driver = webdriver.Edge(options=options)
script = 'Object.defineProperty(navigator, "webdriver", {get: () => false,});'
driver.execute_script(script)
driver.set_page_load_timeout(35)
func(driver)
# 调用函数进行数据爬取
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.60 Safari/537.36'}
main()
f.close()
不足之处在于当爬取1000条左右的数据之后,会被网站封ip,可以用代理ip池的方法,但我不会.....
只能等第二天了....
2.辣沟网
辣沟网就相对比较好弄,因为我们无需请求详情页就可以获取每条招聘信息的详情信息,它的详情信息可以在返回的html中的script中直接获取
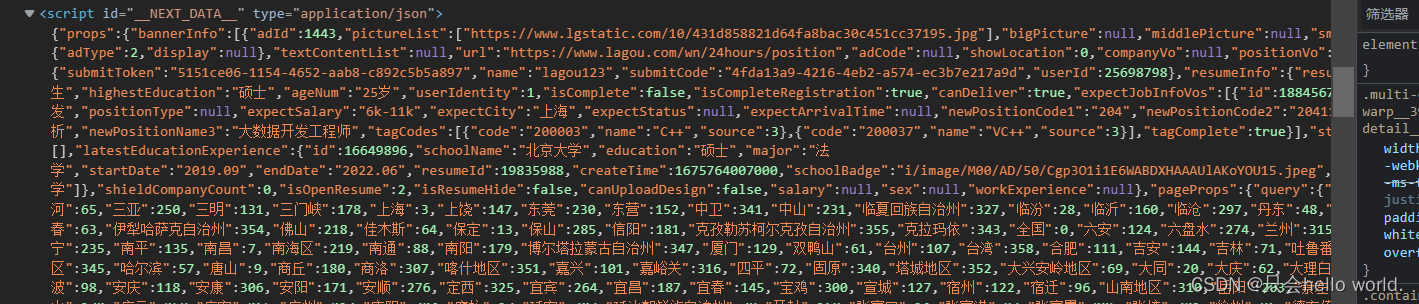
我们采取先登录的方式,由于没有加入图片识别的模块,因此,验证的时候可能需要手动进行验证。。。
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
import json
import csv
f = open('./lagou.csv', 'a', newline='',errors='ignore')
writer = csv.writer(f)
drivers = webdriver.Edge(executable_path='msedgedriver.exe')

drivers.get(url)
username="****"
pd="*****"
time.sleep(5)
drivers.find_element_by_xpath('//*[@id="lg_tbar"]/div[1]/div[2]/ul/li[1]/a').click()
time.sleep(4)
drivers.find_element(By.XPATH,"/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div/div[2]/div[3]/div").click()
time.sleep(1)
drivers.find_element_by_xpath('/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div/div[1]/div[1]/input').send_keys(username)
drivers.find_element_by_xpath('/html/body/div[12]/div/div[2]/div/div[2]/div/div[2]/div[3]/div[1]/div/div[1]/div[2]/input').send_keys(pd)
time.sleep(20)
a=["大数据产品经理","大数据测试工程师","大数据总监"]
for word in a:

drivers.get(url)
j=2
while j<30:
drivers.refresh()
json_str = drivers.find_element_by_id("__NEXT_DATA__").get_attribute('innerText')
json_dict = json.loads(json_str)
for i in range(15): # 每次页面有15个岗位信息
position_name = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['positionName']
salary = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['salary']
cp_name = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['companyFullName']
company_field = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['industryField']
fuli = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['positionAdvantage']
position_place = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['city']
position_info = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['positionDetail']
position_field = json_dict["props"]["pageProps"]["initData"]["content"]["positionResult"]["result"][i]['positionLables']
writer.writerow([position_name,salary,cp_name,company_field,fuli,position_place,position_info,position_field])
time.sleep(2)
drivers.find_element_by_class_name("lg-pagination-item-{}".format(j)).click()
time.sleep(2)
j+=1
f.close()
程序中有一步driver.refresh()非常重要,因为页面翻页后不刷新的话,script是不会变的,
这就是所有内容啦,很多反扒问题都没有解决,只能勉强爬个三四千条数据,希望有点用吧,全民制作人们请多多为我投票吧[doge]


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~