#今日目标
**拉勾网python开发要求爬虫**
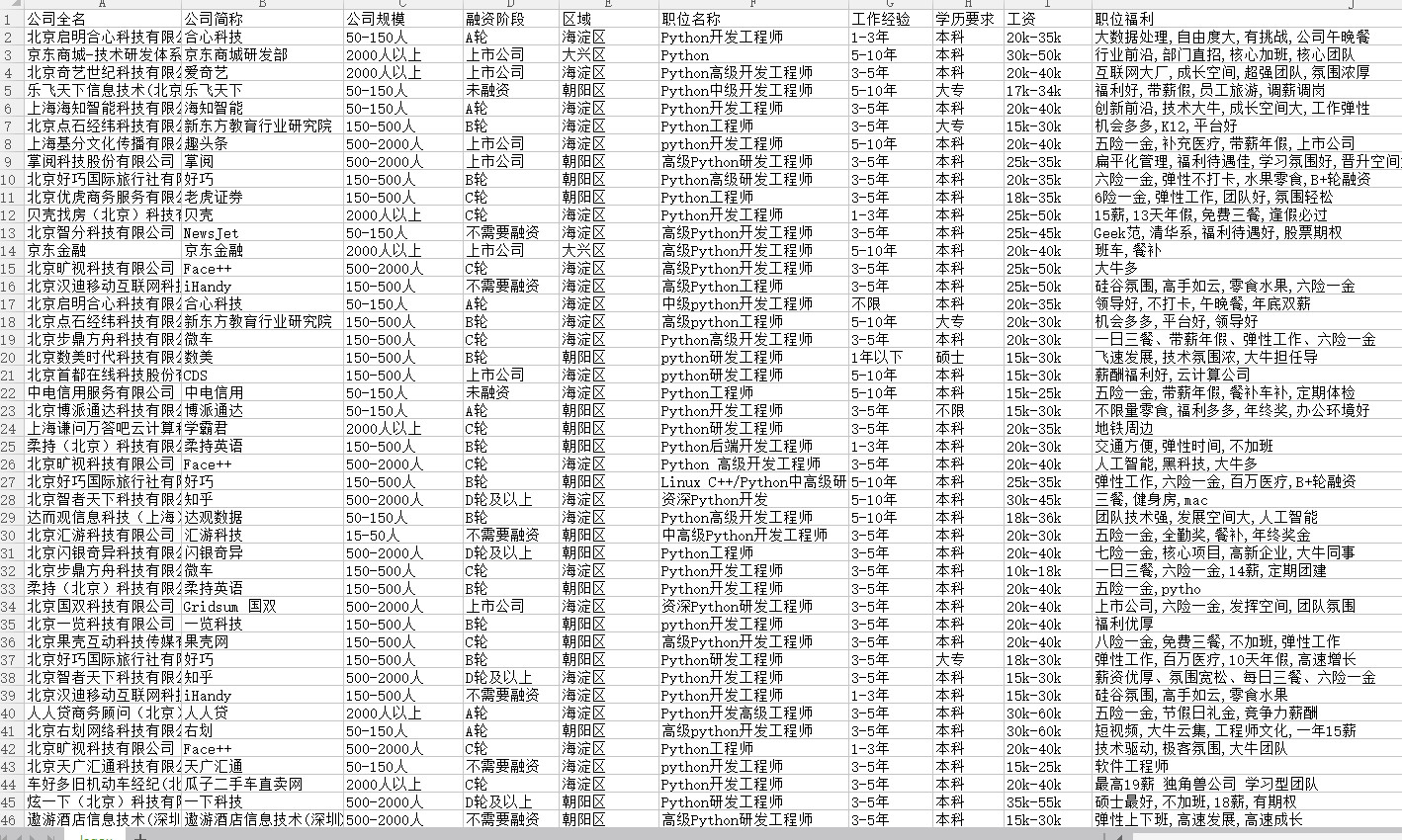
今天要爬取的是北京python开发的薪资水平,招聘要求,福利待遇以及公司的地理位置。
通过实践发现除了必须携带headers之外,拉勾网对ip访问频率也是有限制的。一开始会提示 '访问过于频繁',继续访问则会将ip拉入黑名单。不过一段时间之后会自动从黑名单中移除。
针对这个策略,我们可以对请求频率进行限制,这个弊端就是影响爬虫效率。其次我们还可以通过代理ip来进行爬虫。网上可以找到免费的代理ip,但大都不太稳定。付费的价格又不太实惠。
具体就看大家如何选择了。
**思路**
通过分析请求我们发现每页返回15条数据,totalCount又告诉了我们该职位信息的总条数。
向上取整就可以获取到总页数。然后将所得数据保存到csv文件中。这样我们就获得了数据分析的数据源!
post请求的Form Data传了三个参数
first :是否首页(并没有什么用)
pn:页码
kd:搜索关键字
代码实现
```
# 获取请求结果
# kind 搜索关键字
# page 页码 默认是1
def get_json(kind, page=1,):
# post请求参数
param = {
'first': 'true',
'pn': page,
'kd': kind
}
header = {
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
# 设置代理
proxies = [
{'http': '140.143.96.216:80', 'https': '140.143.96.216:80'},
{'http': '119.27.177.169:80', 'https': '119.27.177.169:80'},
{'http': '221.7.255.168:8080', 'https': '221.7.255.168:8080'}
]
# 请求的url
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
# 使用代理访问
# response = requests.post(url, headers=header, data=param, proxies=random.choices(proxies))
response = requests.post(url, headers=header, data=param, proxies=proxies)
response.encoding = 'utf-8'
if response.status_code == 200:
response = response.json()
# 请求响应中的positionResult 包括查询总数 以及该页的招聘信息(公司名、地址、薪资、福利待遇等...)
return response['content']['positionResult']
return None
```
接下来我们只需要每次翻页之后调用 get_json 获得请求的结果 再遍历取出需要的招聘信息即可。
```
if __name__ == '__main__':
# 默认先查询第一页的数据
kind = 'python'
# 请求一次 获取总条数
position_result = get_json(kind=kind)
# 总条数
total = position_result['totalCount']
print('{}开发职位,招聘信息总共{}条.....'.format(kind, total))
# 每页15条 向上取整 算出总页数
page_total = math.ceil(total/15)
# 所有查询结果
search_job_result = []
#for i in range(1, total + 1)
# 为了节约效率 只爬去前100页的数据
for i in range(1, 100):
position_result = get_json(kind=kind, page= i)
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
# 当前页的招聘信息
page_python_job = []
for j in position_result['result']:
python_job = []
# 公司全名
python_job.append(j['companyFullName'])
# 公司简称
python_job.append(j['companyShortName'])
# 公司规模
python_job.append(j['companySize'])
# 融资
python_job.append(j['financeStage'])
# 所属区域
python_job.append(j['district'])
# 职称
python_job.append(j['positionName'])
# 要求工作年限
python_job.append(j['workYear'])
# 招聘学历
python_job.append(j['education'])
# 薪资范围
python_job.append(j['salary'])
# 福利待遇
python_job.append(j['positionAdvantage'])
page_python_job.append(python_job)
# 放入所有的列表中
search_job_result += page_python_job
print('第{}页数据爬取完毕, 目前职位总数:{}'.format(i, len(search_job_result)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
```
ok!数据我们已经获取到了,最后一步我们需要将数据保存下来。
```
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')
```
运行后结果如下:
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号