
正则
引入正则包:
import re
规范:
str_base = "Hello world, hello world“
final_str = re.findall( r" " , str_base) 前面为搜索规则,后面是被搜索字符串
1. " . " 代表一个任意字符:
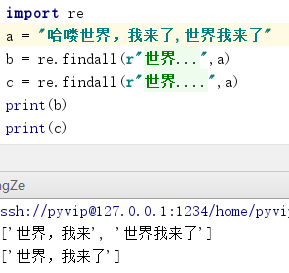 ;
;
2. ” [7] “代表数字(也可以筛选字母): []只代表一个字符
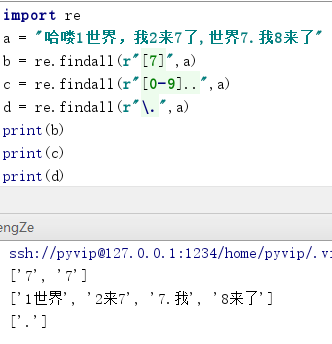
[abc] :可筛选字母
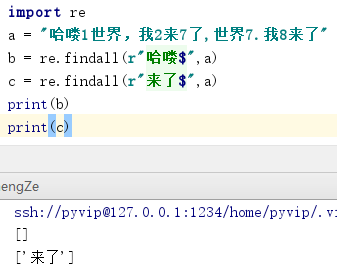
3. ” ^ “ 表示只匹配开头符合的元素:

4. ” $ “ 只匹配结尾符合的元素:
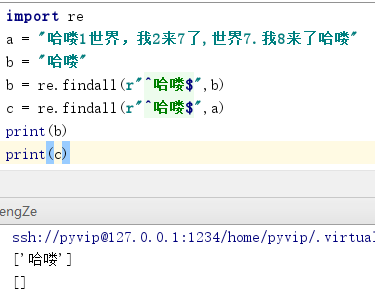
5. ” ^ “ 和 " $ " 结合使用,表示前后都没有杂的元素符合:
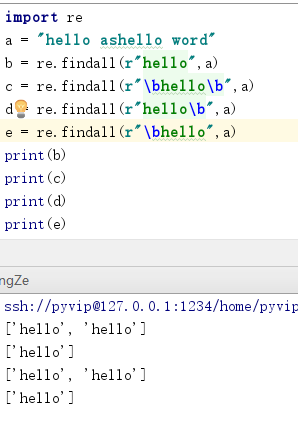
6. " \b " 边界符,可用来提出单词:
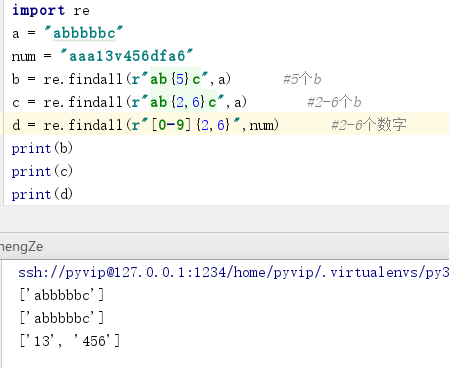
7. {}控制次数:
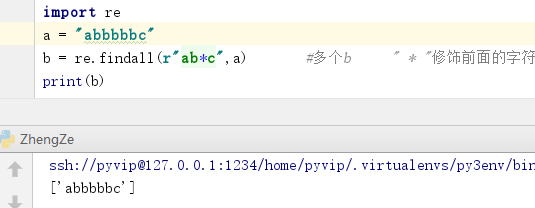
8. " * " 修饰前面字符,有多个(可以是0个,也就是没有):
9. " + " 跟上面的 " * "类似,但是 " + " 不能匹配0个(也就是必须要有)
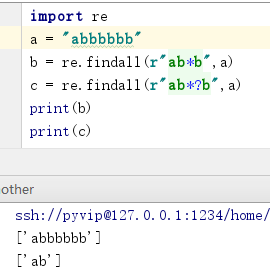
10. " ? " 同上,但可以匹配0个和1个,大于1个不能匹配
11. 在匹配符号后面 + " ? " 表示非贪婪模式:
12. “ | ” 可以匹配多个:

13. “ ^ ” 在 " [] " 里可表示非(即不取这些):

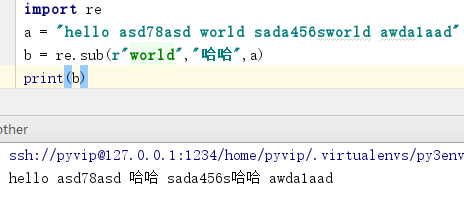
14. re.sub(r" " , " " , a) 替换:
15. re.findall("",a,re.S)
匹配有换行的字段
16. re.findall("hello|world",a) 匹配hello 或者world
17. 归纳:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号