


tensorflow2.3实现Segformer
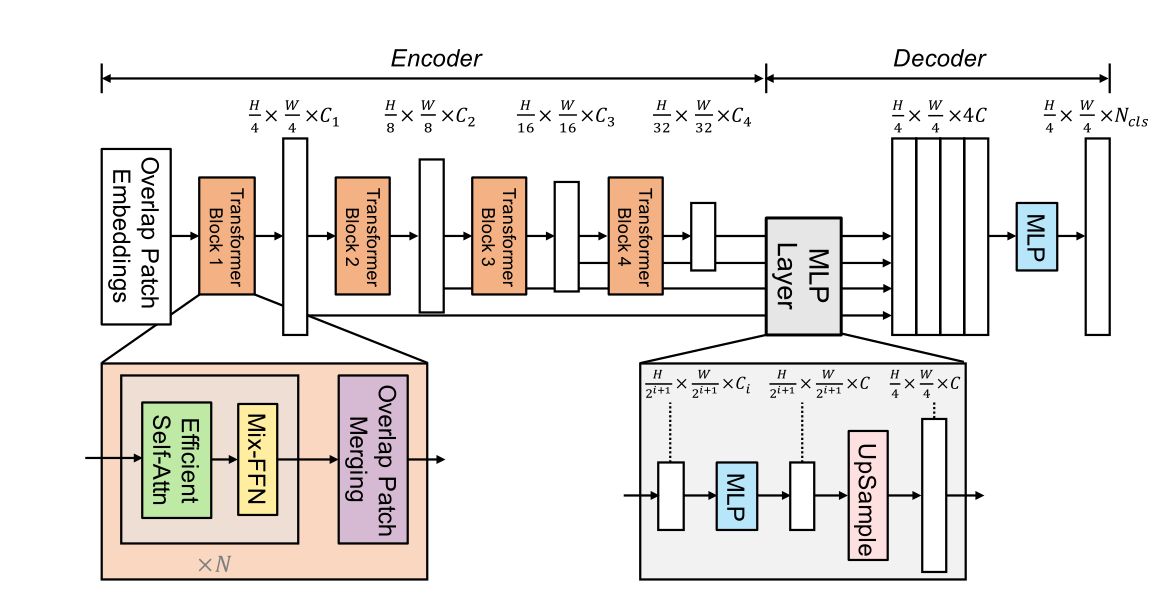
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 | import tensorflow as tfimport mathfrom math import sqrtfrom tensorflow import kerasimport sysfrom functools import partialimport cv2import numpy as npfrom einops import rearrangedef cast_tuple(val, depth): return val if isinstance(val, tuple) else (val,) * depth# print(cast_tuple((2,1),5))# print(cast_tuple(2,5))## dims = (32, 64, 160, 256),# heads = (1, 2, 5, 8),# ff_expansion = (8, 8, 4, 4),# reduction_ratio = (8, 4, 2, 1),# num_layers = 2,# channels = 3,# decoder_dim = 256,# num_classes = 4# c = dims, heads, ff_expansion, reduction_ratio, num_layers = map(# partial(cast_tuple, depth = 4), (dims, heads, ff_expansion, reduction_ratio, num_layers)# )## 分组卷积class DsConv2d(keras.layers.Layer): def __init__(self, dim_in, dim_out, kernel_size, padding, stride = (1,1), bias = True): super(DsConv2d, self).__init__() self.net = keras.Sequential([ keras.layers.BatchNormalization(), keras.layers.Conv2D(dim_in, kernel_size, padding = padding, groups = dim_in, strides = stride, use_bias = bias), # 改进:可以更深度 keras.layers.Conv2D(dim_out, kernel_size = 1, use_bias = bias) ]) def call(self, x): # print('x:',x.shape) return self.net(x)# d_conv = DsConv2d(dim_in=3,dim_out=512,kernel_size=3,padding='SAME')# input_data = keras.layers.Input(shape=(101,101,3))# deal1 = d_conv(input_data)# print(deal1.shape)class PreNorm(tf.keras.Model): def __init__(self, dim, fn): super().__init__() self.norm = tf.keras.layers.LayerNormalization(epsilon=1e-5) self.fn = fn def call(self, x): return self.fn(self.norm(x))class EfficientSelfAttention(keras.layers.Layer): def __init__(self,*,dim,heads,reduction_ratio): super(EfficientSelfAttention,self).__init__() self.scale = (dim // heads) ** -0.5 self.heads = heads self.to_q = keras.layers.Conv2D(dim, 1, use_bias = False) self.to_k = keras.layers.Conv2D(dim * 1, reduction_ratio, strides = reduction_ratio, use_bias = False) self.to_v = keras.layers.Conv2D(dim * 1, reduction_ratio, strides=reduction_ratio, use_bias=False) self.to_out = keras.layers.Conv2D(dim, 1, use_bias = False) def call(self, x): h, w = x.shape[-3:-1] heads = self.heads q, k, v = (self.to_q(x), self.to_k(x), self.to_v(x)) # 顺序 q, k, v = map(lambda t: rearrange(t, 'b x y (h c)-> (b h) (x y) c', h = heads), (q, k, v)) sim = tf.einsum('b i d, b j d -> b i j', q, k) * self.scale attn = tf.nn.softmax(sim,axis = -1) out = tf.einsum('b i j, b j d -> b i d', attn, v) out = rearrange(out, '(b h) (x y) c -> b x y (h c)', h = heads, x = h, y = w) return self.to_out(out)def gelu(x): """Gaussian Error Linear Unit. This is a smoother version of the RELU. Original paper: https://arxiv.org/abs/1606.08415 Args: x: float Tensor to perform activation. Returns: `x` with the GELU activation applied. """ cdf = 0.5 * (1.0 + tf.tanh( (math.sqrt(2 / math.pi) * (x + 0.044715 * tf.pow(x, 3))))) return x * cdfclass GELU(keras.layers.Layer): def call(self, inputs, **kwargs): cdf = 0.5 * (1.0 + tf.tanh( (math.sqrt(2 / math.pi) * (inputs + 0.044715 * tf.pow(inputs, 3))))) return inputs * cdfclass MixFeedForward(keras.layers.Layer): def __init__( self, *, dim, expansion_factor ): super().__init__() hidden_dim = dim * expansion_factor self.net = keras.Sequential([ keras.layers.Conv2D(hidden_dim, 1), DsConv2d(hidden_dim,hidden_dim, 3, padding = 'SAME'), # 改进 :加入一些空洞卷积 keras.layers.BatchNormalization(), GELU(), keras.layers.Conv2D(dim, 1)] ) def call(self, x): return self.net(x)# class my_Unfold(keras.layers.Layer):# def __init__(self,*,kernel, stride , padding,rates=[1, 1, 1, 1]):# self.kernel = kernel# self.stride = stride# self.padding = padding# self.rates = rates# def call(self, inputs, **kwargs):# return tf.image.extract_patches(images=inputs,sizes=[1,self.kernel,self.kernel,1], strides=[1,self.stride,self.stride,1],rates=[1,1,1,1],padding='SAME')class MiT(keras.layers.Layer): # dims = (32, 64, 160, 256),heads = (1, 2, 5, 8),ff_expansion = (8, 8, 4, 4), # reduction_ratio = (16, 4, 2, 1),num_layers = 2,channels = 3,decoder_dim = 256,num_classes = 4 def __init__(self,*,channels,dims,heads,ff_expansion,reduction_ratio,num_layers,stage_kernel_stride_pad): super().__init__() # self.stage_kernel_stride_pad = ((7, 4, 3), (3, 2, 1), (3, 2, 1), (3, 2, 1)) # self.stage_kernel_stride_pad = ((3, 2), (3, 2), (3, 2), (3, 2)) # patch self.stage_kernel_stride_pad = stage_kernel_stride_pad dims = (channels, *dims) dim_pairs = list(zip(dims[:-1], dims[1:])) self.stages = [] # self.stages = keras.Sequential() for (dim_in, dim_out), num_layers, ff_expansion, heads, reduction_ratio in \ zip(dim_pairs, num_layers, ff_expansion, heads, reduction_ratio): # get_overlap_patches = nn.Unfold(kernel, stride = stride, padding = padding) # get_overlap_patches = my_Unfold(kernel = kernel, stride=stride, padding='SAME') overlap_patch_embed = keras.layers.Conv2D( dim_out, 1) # 改动 : 可将卷积核变为3,提取较大的局部信息 layers = [] # layers = keras.Sequential() # for _ in range(num_layers): for _ in range(4): layers.append([ PreNorm(dim_out, EfficientSelfAttention(dim = dim_out, heads = heads, reduction_ratio = reduction_ratio)), PreNorm(dim_out, MixFeedForward(dim = dim_out, expansion_factor = ff_expansion)), ]) self.stages.append([ # get_overlap_patches, overlap_patch_embed, layers ]) def call(self,x,return_layer_outputs = False): layer_outputs = [] layer_index = 0 # for (get_overlap_patches, overlap_embed, layers) in self.stages: for (overlap_embed, layers) in self.stages: ksize,stride = self.stage_kernel_stride_pad[layer_index] x = tf.image.extract_patches(images=x,sizes=[1,ksize,ksize,1], strides=[1,stride,stride,1],rates=[1,1,1,1],padding='SAME') # num_patches = x.shape[-1] # ratio = int(sqrt((h * w) / num_patches)) # x = rearrange(x, 'b c (h w) -> b c h w', h = h // ratio) x = overlap_embed(x) for (attn, ff) in layers: x = attn(x) + x x = ff(x) + x layer_outputs.append(x) layer_index+=1 ret = x if not return_layer_outputs else layer_outputs return ret# @tf.functionclass Segformer(keras.Model): def __init__(self,dims = (32, 64, 160, 256),heads = (1, 2, 5, 8),ff_expansion = (8, 8, 4, 4), reduction_ratio = (16, 4, 2, 1),num_layers = 2,channels = 3,decoder_dim = 256,num_classes = 4,stage_kernel_stride_pad = ((3, 2), (3, 2), (3, 2), (3, 2))): super().__init__() dims, heads, ff_expansion, reduction_ratio, num_layers = map( partial(cast_tuple, depth = 4), (dims, heads, ff_expansion, reduction_ratio, num_layers) ) self.upscale = stage_kernel_stride_pad[0][1] assert all([*map(lambda t: len(t) == 4, (dims, heads, ff_expansion, reduction_ratio, num_layers))]), 'only four stages are allowed, all keyword arguments must be either a single value or a tuple of 4 values' self.mit = MiT( channels = channels, dims = dims, heads = heads, ff_expansion = ff_expansion, reduction_ratio = reduction_ratio, num_layers = num_layers, stage_kernel_stride_pad = stage_kernel_stride_pad ) self.to_fused = [ keras.Sequential([ keras.layers.Conv2D(decoder_dim, 1), # nn.Upsample(scale_factor=2 ** i) keras.layers.UpSampling2D(size=(2**i,2**i)) ]) for i, dim in enumerate(dims) ] self.to_segmentation = keras.Sequential([ keras.layers.Conv2D(decoder_dim, 1), # 改进: 激活函数 keras.layers.BatchNormalization(), keras.layers.ReLU(), # keras.layers.Conv2DTranspose(filters=decoder_dim//2,kernel_size = [self.upscale+2,self.upscale+2],strides=(self.upscale, self.upscale),padding='SAME'), keras.layers.UpSampling2D(size=(self.upscale,self.upscale)), # keras.layers.Conv2D(decoder_dim, 3,1, activation=tf.nn.relu), keras.layers.Conv2D(num_classes, 1,activation=tf.nn.sigmoid), ]) @tf.function def call(self, x): layer_outputs = self.mit(x, return_layer_outputs = True) # fused = [to_fused(output) for output, to_fused in zip(layer_outputs, self.to_fused)] fused = [] for i_stage in range(len(self.to_fused)): output = layer_outputs[i_stage] to_fused = self.to_fused[i_stage] fused.append(to_fused(output)) fused = tf.concat(fused, axis = -1) logits = self.to_segmentation(fused) # softmax_out = tf.nn.softmax(logits,axis=-1) return logits############## 测试 ################################# if __name__ == '__main__':# s_model = Segformer()# img_path = '1.PNG'# img = cv2.imread(img_path, 1)## input_data = np.reshape(img,(1,256,256,3)).astype(np.float32)## c = s_model(input_data)## print('input_data:',input_data.shape)# print('c:',c.shape) |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构