



tensorflow2.0——GRU(双门简化版)
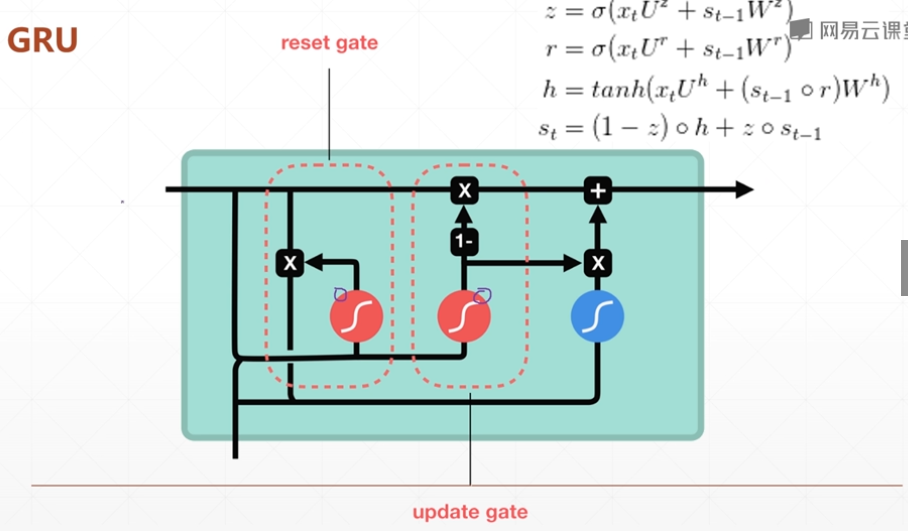
GRU相比于LSTM只有两个门:
import tensorflow as tf import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' assert tf.__version__.startswith('2.') # 设置相关底层配置 physical_devices = tf.config.experimental.list_physical_devices('GPU') assert len(physical_devices) > 0, "Not enough GPU hardware devices available" tf.config.experimental.set_memory_growth(physical_devices[0], True) # 只取10000个单词,超过10000的按生僻词处理 total_words = 10000 max_sentencelength = 121 # 每个句子最大长度 batchsize = 2000 embedding_len = 100 # 将单词从原来的的一个数扩充为100维的向量 (x_train,y_train),(x_test,y_test) = tf.keras.datasets.imdb.load_data(num_words=total_words) # numweord为单词种类个数 print('x_train.shape:',x_train.shape) print('x_train[3]:',len(x_train[3]),x_train[3]) x_train = tf.keras.preprocessing.sequence.pad_sequences(x_train,maxlen = max_sentencelength) # 把句子长度限制为定长 print('x_train[3]:',len(x_train[3]),x_train[3]) x_test = tf.keras.preprocessing.sequence.pad_sequences(x_test,maxlen = max_sentencelength) # x_train : [b,80] [b,max_sentencelength] b个句子,每句80(max_sentencelength)个单词 # x_test : [b,80] print('x_train.shape:',x_train.shape) # print('x_train[3]:',x_train[3].shape,x_train[3]) print('y_train.shape:',y_train.shape,tf.reduce_max(y_train),tf.reduce_min(y_train)) db_train = tf.data.Dataset.from_tensor_slices((x_train,y_train)) db_train = db_train.shuffle(1000).batch(batch_size=batchsize,drop_remainder=True) # 设置drop参数可以把最后一个batch如果与前面的batch长度不一样,就丢弃掉 db_test = tf.data.Dataset.from_tensor_slices((x_test,y_test)) db_test = db_test.batch(batch_size=batchsize,drop_remainder=True) class MyRnn(tf.keras.Model): def __init__(self,units): super(MyRnn,self).__init__() # [b,80] => [b,80,100] # [b,64] [b,units] # self.state0 = [tf.zeros([batchsize,units])] self.embedding = tf.keras.layers.Embedding(total_words,embedding_len,input_length = max_sentencelength) # [b,80,100] ,-> h_dim:units(比如64) # SimpleRNN 后面会用到 ,更简单 # self.rnn_cell0 = tf.keras.layers.SimpleRNNCell(units,dropout=0.2) # self.rnn_cell1 = tf.keras.layers.SimpleRNNCell(units, dropout=0.2) self.rnn_cell0 = tf.keras.layers.GRUCell(units,dropout=0.5) self.rnn_cell1 = tf.keras.layers.GRUCell(units, dropout=0.5) # fc , [b,80,100] =>[b,64]=>[b,1] self.outlayer = tf.keras.layers.Dense(1) def __call__(self, inputs, training = None): """ :param inputs:[b,80] [b,句子最大长度(80)] :param training: """ # [b,80] x = inputs print('x.shape:',x.shape) # embedding:[b,80]=>[b,80,100] x = self.embedding(x) # rnn cell compute # [b,80,100] = [b,64] # print('x.shape[0]:',x.shape[0]) state0 = [tf.zeros([x.shape[0],units])] state1 = [tf.zeros([x.shape[0], units])] for word in tf.unstack(x,axis=1): # word:[b,100] 以中间的1维度展开(按照需要时序处理的维度展开,这里是句子长度) # x * wxh + h * whh 2层的 out0,state0 = self.rnn_cell0(word,state0,training) out1, state1 = self.rnn_cell1(out0, state1, training) # out:[b,64] => [b,1] x = self.outlayer(out1) prob = tf.sigmoid(x) return prob if __name__ == '__main__': units = 64 epochs = 40 lr = 1e-2 model = MyRnn(units) model.compile(optimizer=tf.keras.optimizers.Adam(lr), loss= tf.losses.BinaryCrossentropy(), # 二分类的loss函数 metrics=['accuracy']) model.fit(db_train,epochs=epochs,validation_data=db_test) model.evaluate(db_test)

