
软工实践寒假作业(2/2)
| 作业的基本信息 | |
|---|---|
| 这个作业属于哪个课程 | 班级的链接 |
| 这个作业要求在哪里 | 作业要求的链接 |
| 这个作业的目标 | 重读《构建之法》并提问,学习使用Git和GitHub,完成WordCount作业,学习并进行单元测试,撰写作业博客 |
| 作业正文 | ... |
| 其他参考文献 | 《构建之法》、git教程、Github的使用、预培训文档C++版等 |
1、阅读《构建之法》后的问题
问题一:在《IT行业的创新-创新的迷思(5-6)》中,迷思之五部分有这样一句话:“70% 的创新者说, 他们最成功的创新, 是在他们的拿手领域之外发现的。”,虽然文章中举了些例子,但我对这个比例还是有疑问。
-
按我个人的经验,一个外行人如何能在其他领域创新呢,在某领域创新难道不需要精通这些行业的知识吗?就算真的出于某些偶然的因素,他做到了,但这个比例也不应该是70%啊,难道大部分创新都是偶然?鉴于个人观点的片面性,我就这句话百度到了几篇相关文章博文,其中有赞同的,也有反对的。但并没有直接证据说明这句话的对错。
我对这些看法作的总结如下: -
支持:“当局者迷”,领域内的专家由于拘于熟悉的知识而欠缺新的思考,往往不知如何突破。而领域之外的执着的人却会因为一个想法而刨根问底,不懈追求,最终创造专家都想不出来的新东西。另一种支持的观点是这70%的创新中部分是商业模式的创新,不关乎核心技术,正如《创新 - 王屋村的魔方们》中二柱同学的做法。
-
反对: 创新应该基于对该领域的深刻理解与知识储备,就好比一个小学生他做不出高数题,但有的题目他可以蒙出答案。
问题二:创新的时机跟黄金点游戏有关联吗?
- 我看了《创新的时机 – 黄金点游戏》这篇博文,博文中邹老师谈到了黄金点游戏以及对这个游戏的几点领悟,但是我觉得跟创新的时机没什么关系。关于时机,“只先一步”部分有这样一段话:“那些成功的企业只是比大众的平均值先走了一小步(平均值 * 0.618), 就是这一小步, 让大部分人看到了产品的“相对优势”从而接受产品。关于技术创新, 一些趋势(例如社会网络),大家早就看到了, 也有一些产品推出, 但是往往最后成功的产品成功在时机上。”,“Technology Hype Cycle”部分也提到:“说到时机, 任何新技术都有一个自身发展的规律,Gartner 的Jackie Fenn 写了一个很有意思的报告, 提到了Technology Hype Cycle。”我对这两部分的理解总结为:新产品在合适的时机推出才能获取成功,此前这个产品可能经历了几个发展换代阶段。但我觉得创新是创造新产品,创新的时机肯定是领先于产品推出的时机,正如文中说的:“做前沿研究的人, 可以早于其他人很多年提出新想法, 但是这些想法一般都是在“Innovator” 那个圈子里有影响, 这些想法要等若干年才能由成功的企业家看准时机推向大众市场。”,所以我认为黄金点游戏是跟推出新产品的时机有关联而不是创新的时机。
问题三:软件创新的出路真的是“走进作坊”?
- 邹老师在《软件工程讲义 9 创新的出路 走进作坊》中对于软件创新的出路提出了“走进作坊”的观点。原文中有这样一句话:“这些好的作坊, 都有这些核心特性: 从小事做起, 讲究质量, 信用, 对产品负责, 对工作自豪。”,我学识有限,对这篇文章笼统地理解为:创新的出路是作坊是因为好的作坊有匠人精神。感觉我的怀疑没什么依据,要说源头大概就是如原文中说的“哪里都有盗版, 哪里都有抄袭, 哪里都有竞争”,上网去搜索出路什么的大部分都是讲创新是出路,缺少实践的东西。只能说直觉告诉我走进作坊不错,但实际操作起来把它当做创新的出路真的可行吗,是不是大家一起“走进作坊”,我国软件业的创新就能搞起来了呢?
问题四:如何应对“主治医师模式”?
- 我读了《团队和流程》这篇博文,里面谈到了几种团队模式和软件开发模式。原文中有这样一段话:‘主治医师模式的退化: 在一些学校里, 软件工程的团队模式往往退化为“一个学生干活, 其余学生跟着打酱油。”’,即将面临软件工程实践课的组队,由于能力、性格的不同难免会形成各种团队模式。如果我有幸遇到这种模式,估计就是一打酱油的。所以一个团队如果能干活人的较少,但是为了项目能够进行下去,应该怎么做?
问题五:什么是单元测试的自动化?
- 读过《单元测试&回归测试》这篇博文,谈到了单元测试的自动化。原文是这样的:“另一个重要的措施是要把单元测试自动化,这样每个人都能很容易地运行它,并且可以使单元测试每天都运行。每个人都可以随时在自己的机器上运行。团队一般是在每日构建中运行单元测试的,这样每个单元测试的错误就能及时被发现并得到修改。”,虽然这次作业大概走了一遍单元测试流程,我还是想弱弱地问一句,比如VS上新建单元测试项目,编写好单元测试运行,是不是就算单元测试自动化了?
2、WordCount编程
2.1、Github项目地址
2.2、PSP表格
- 由于时间不多,没有详细计划准备。所以表格只填了有大概统计的步骤。
| PSP阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|
| 计划 | ||
| • 估计这个任务需要多少时间 | 0 | 1 |
| 开发 | ||
| • 需求分析 (包括学习新技术) | 60 | 120 |
| • 生成设计文档 | ||
| • 设计复审 | ||
| • 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| • 具体设计 | ||
| • 具体编码 | 600 | 480 |
| • 代码复审 | ||
| • 测试(自我测试,修改代码,提交修改) | 120 | 480 |
| 报告 | ||
| • 测试报告 | ||
| • 计算工作量 | ||
| • 事后总结, 并提出过程改进计划 | ||
| 合计 | 810 | 1141 |
2.3、解题思路描述
之前感觉来不及,没有针对题目进行完整构想后再动手,边写边想的。
-
step1.拿到题目,浏览一下发现关乎文件读写,所以先复习一下相关知识。输入用到命令行参数的形式,由于少接触需要测试一下。
-
step2.然后具体看实现要求,总共有4个要求。粗略看来1、3比较简单主要与字符有关,2、4比较难应该还涉及字符串的处理。可以秉着先易后难的原则分四个部分逐一实现。
-
step3.在命令行的环境下完成要求1和3后,再看要求2,发现其实和要求1、2一样主要是针对字符的处理。除了对字符的判断以外,在读取的过程构建单词并对单词合法性进行判断就好了。
-
step4.完成了2之后,发现4的功能似乎也不难实现,因为前面统计词数的时候就能够将单词提取出来,剩下的就是单词的存储和排序,这里存储用结构体,由于比较熟悉vector,所以尝试用sort对该结构体类型的vector进行排序。
2.4、代码规范制定链接
2.5、计算模块接口设计与实现过程
主要写了四个函数来实现功能
int countCharacter(char*);
int countLine(char*);
int countWord(char*);
void sortWord();
-
四个主要函数相对独立。
-
这边主要说明sortWord和countWord的关系:程序中声明了一个Word结构体类型的全局vector数组words用来存放文件中统计的单词和它的频数。countWord函数负责返回统计的单词个数,此外,其在读取单词的过程中会调用函数isExist,该函数负责判断单词是否已在words中,对已有的单词直接增加频数;若单词不在words中则返回假,于是,countWord将当前读到的单词加入words。函数sortWord则在countWord执行完后对words中的结果进行排序,即排序单词数组(因此之前说countWord的结果会影响sortWord),sortWord排序的方法是调用标准库中的函数sort(),使用该函数前需要针对自定义类型(我的程序中是Word类型的结构体)进行 < 运算符的重载。
-
新增函数间的关系流程图如下。其中没有注释的直箭头表示顺序执行,重复出现的 x 表示当前函数的返回值。
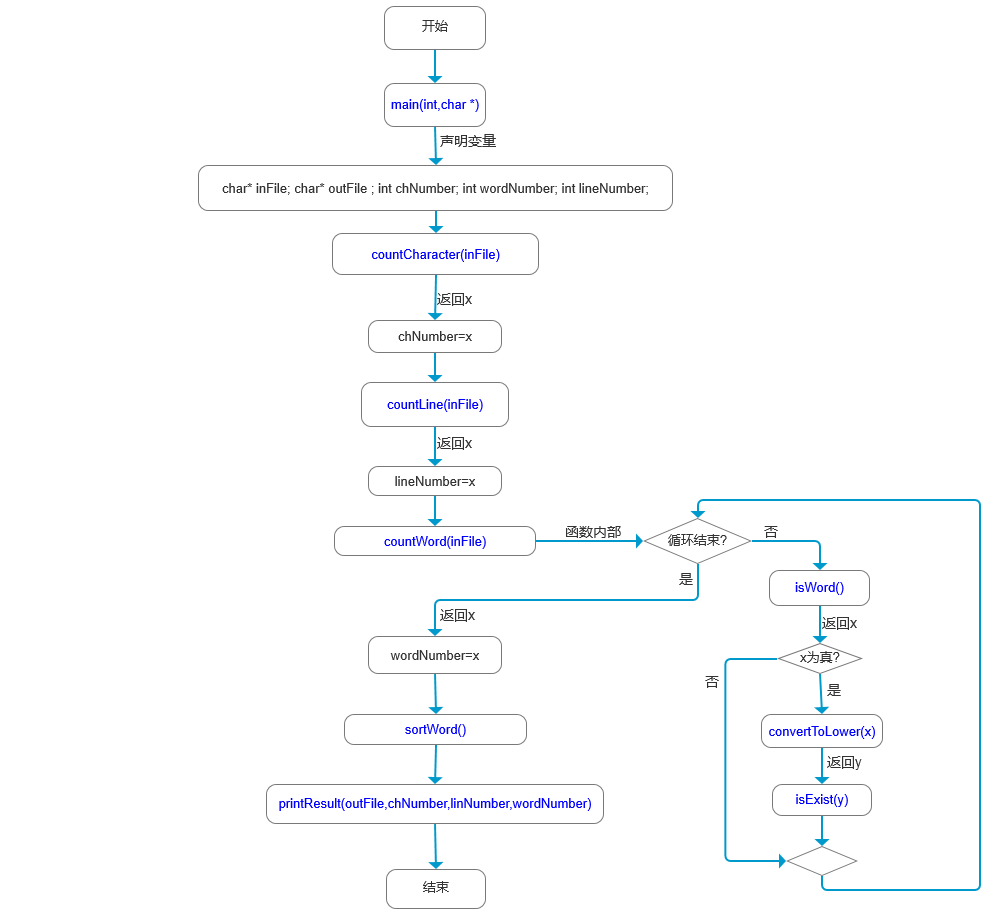
这四个函数的关键代码如下:
用于统计字符数的countCharacter
while (fin.get(ch))
{
if ((ch >= 32 && ch <= 126) || ch == 9 || ch == 10 || ch == 13)
{
chNumber++;
}
}
用于统计行数的countLine
char ch;
int judge = 0;//用于判断一行中是否有非空白符
int lineNumber = 0;
while (fin.get(ch))
{
if (ch == 10)
{
if (judge)
lineNumber++;
judge = 0;
}
if (ch >= 33 && ch <= 126)
judge = 1;
}
- 变量judge在遇到非空白符的时候置1,成功统计一行后置0。
用于统计单词数的countWord
if ((ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z') || (ch >= '0' && ch <= '9'))
{
word += ch;
}
else
{
judge = isWord(word);
if (judge)
{
//cout << word << endl;
word = convertToLower(word);
if (!isExist(word))
{
oneWord.word = word;
words.push_back(oneWord);
}
wordNumber++;
judge = false;
}
word = "";
}
- string对象word用来临时存放读到的单词。函数convertToLower将单词转为小写并返回,函数isWord和isExist分别用来判断单词是否合法和被统计过。
用于排序单词的sortWord
bool operator<(Word& w1, Word& w2)
{
if (w1.frequency == w2.frequency)
{
return w1.word < w2.word;
}
else
return w1.frequency > w2.frequency;
}
void sortWord()
{
sort(words.begin(), words.end());
}
2.6、性能改进
- 下面是对主函数加上循环后用性能探查器得到的CPU使用率的截图。
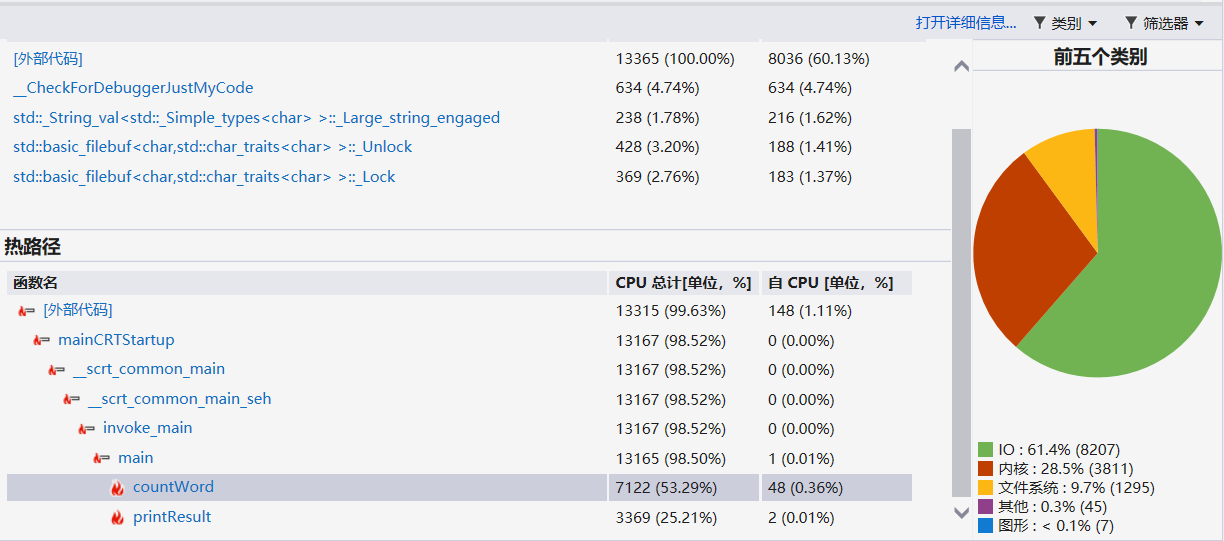
- countWord占用了过半的运行时间,因为其要调用其他函数,进行多次循环判断。
性能改进暂时不知道如何改进,估计得从整个算法入手,进行代码重构。
2.7、单元测试
- 下面是部分单元测试的代码,
估计写得不咋地。
TEST_CLASS(MainFunctions)
{
public:
TEST_METHOD(TestMethod1)
{
fstream f("in.txt", ios::out);
for (int i = 0;i < 10;i++)
{
f << "hhh真不错 windows" << '\n';
}
f.close();
int number = 120;
char str[] = "in.txt";
Assert::AreEqual(countCharacter(str), number);
}
TEST_METHOD(TestMethod2)
{
fstream f("in.txt", ios::out);
for (int i = 0;i < 1000;i++)
{
f << "hhh" << '\n';
}
f.close();
int number = 1000;
char str[] = "in.txt";
Assert::AreEqual(countLine(str), number);
}
TEST_METHOD(TestMethod3)
{
fstream f("in.txt", ios::out);
for (int i = 0;i < 10;i++)
{
f << "hhh真不错windows Windows" << '\n';
}
f.close();
int number = 20;
char str[] = "in.txt";
Assert::AreEqual(countWord(str), number);
}
};
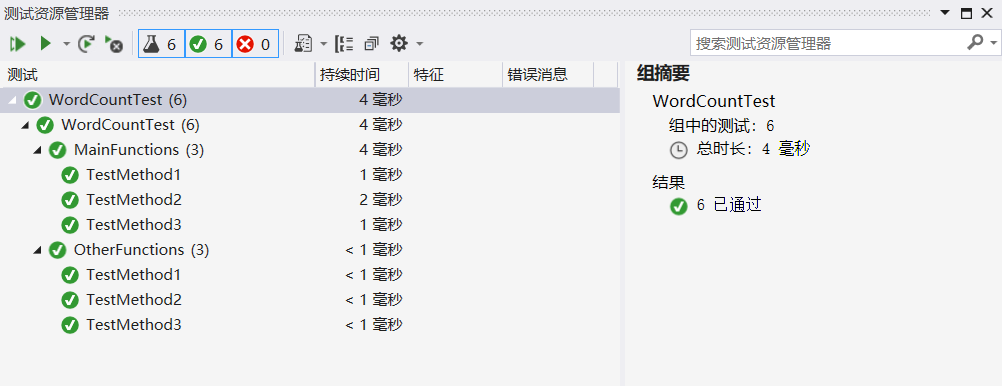
- 代码覆盖率用VS好像看不了。所有测试的通过截图如下:
2.8、异常处理说明
- 代码中没写什么异常处理。文件打开失败的话会直接退出程序。
2.9、心路历程与收获
-
这个随便讲讲吧(
假大空?,太难了,实事求是吧)。 -
我就做作业的过程讲讲我的心路历程。个人拖延的毛病比较重,宅家不想写作业,作业很晚才开始动工的。所以做作业的时候全程感觉压力大,因为不仅要学新的东西,还要写新的东西,还得认真学,还得尽量快点(
我只想说我尽力了)。中途的时候心态炸了几次,因为编程出了bug,不知道在哪修,刚想放弃挣扎的时候来一个峰回路转(发现错在了细节上),这时候真的是庆幸又十分不爽。好在最后坚持到底把作业交了。 -
收获除了学了些新东西外,还有成功加强了我的自知之明————吾是菜鸡,以及让我意识到
我离当场去世又近了一步。

