

比较不同的优化器
比较不同的优化器
以下代码比较了神经网络不同优化器的收敛速度:
import torch
import torch.utils.data as Data
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
if __name__ == '__main__':
# hyper parameters
LR = 0.01
BATCH_SIZE = 32
EPOCH = 12
x = torch.unsqueeze(torch.linspace(-1, 1, 1000), dim=1)
y = x.pow(2) + 0.1 * torch.normal(torch.zeros(*x.size()))
# torch.zeros(size): a tensor of size,filled by 0
# torch.normal(mean): a random number of mean
torch_dataset = Data.TensorDataset(x, y)
loader = Data.DataLoader(dataset=torch_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(1, 20) # hidden layer
self.predict = torch.nn.Linear(20, 1) # output layer
def forward(self, x):
x = F.relu(self.hidden(x)) # relu is activation function between hidden and predict
x = self.predict(x)
return x
# 4 nets of same structure
net_SGD = Net()
net_Momentum = Net()
net_RMSprop = Net()
net_Adam = Net()
nets = [net_SGD, net_Momentum, net_RMSprop, net_Adam] # together
# 4 nets of same structure but 4 different optimizers
opt_SGD = torch.optim.SGD(net_SGD.parameters(), lr=LR)
opt_Momentum = torch.optim.SGD(net_Momentum.parameters(), lr=LR, momentum=0.8)
opt_RMSprop = torch.optim.RMSprop(net_RMSprop.parameters(), lr=LR, alpha=0.9)
opt_Adam = torch.optim.Adam(net_Adam.parameters(), lr=LR, betas=(0.9, 0.99))
optimizers = [opt_SGD, opt_Momentum, opt_RMSprop, opt_Adam]
loss_func = torch.nn.MSELoss()
loss_his = [[], [], [], []]
for epoch in range(EPOCH):
print(epoch)
for step, (batch_x, batch_y) in enumerate(loader):
# turn to variable to be put into the net
b_x = Variable(batch_x)
b_y = Variable(batch_y)
for net, opt, l_his in zip(nets, optimizers, loss_his):
output = net(b_x) # output of net
loss = loss_func(output, b_y) # loss of net
opt.zero_grad() # clear gradients for next train
loss.backward() # back propagation,compute gradients
opt.step() # apply gradients
l_his.append(loss.data) # record loss
labels = ['SGD', 'Momentum', 'RMSprop', 'Adam']
for i, l_his in enumerate(loss_his):
plt.plot(l_his, label=labels[i]) # label:what the line is
plt.legend(loc='best') # set the label to the 'best' place
plt.xlabel('Steps')
plt.ylabel('Loss')
plt.ylim((0, 0.2))
plt.show()
输出结果:
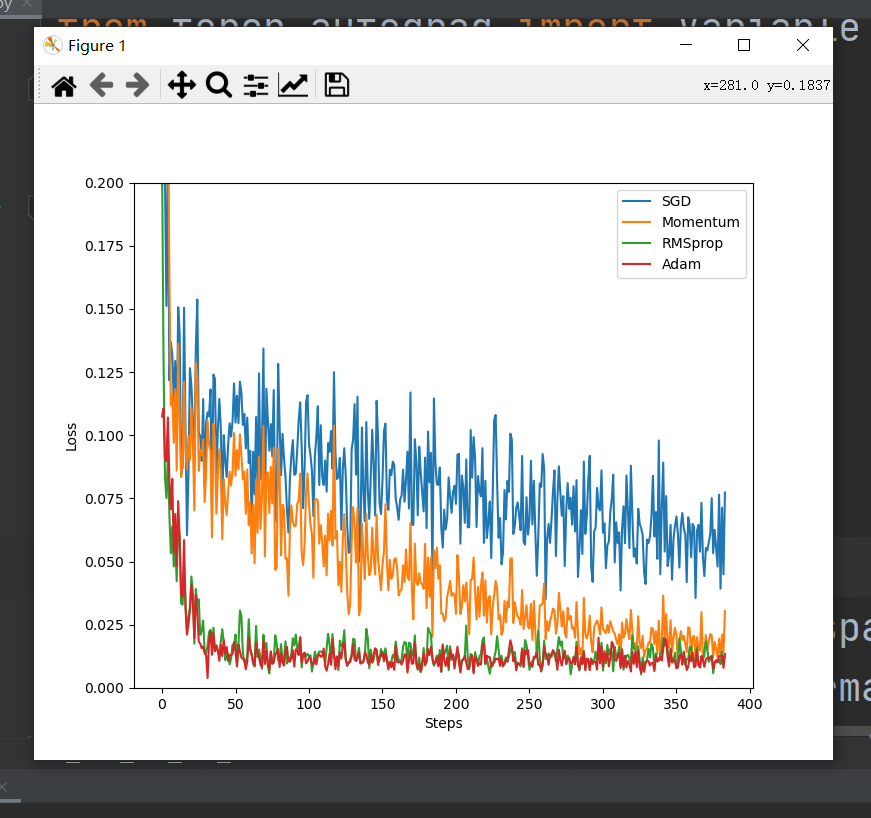
结果图的纵坐标是误差,横坐标是训练批数,优化器最终目标是误差接近零,接近零的过程叫收敛,越快收敛越好。
SGD作为最基础的优化器收敛最慢。
Momentum在梯度下降时增加斜坡,使下降速度变快。
AdaGrad在梯度下降时,减少左右摆动,使梯度方向保持直线。图中未画出此方法。
RMSprop结合了Momentum与AdaGrad的优点,反应在图上是最快的收敛速度。
Adam是RMSprop的升级版,不仅拥有最快的收敛速度,而且与RMSprop误差波动不大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号