
多进程4
多进程4
本文使用multiprocessing中的Pool类来进行任务分配和保存返回值。
具体是使用Pool类的两个方法,分别是map方法和apply_async方法。
map方法
以下代码使用map方法:
import multiprocessing as mp
def job(a):
return a * a
def by_multiprocess():
pool1 = mp.Pool()
res = pool1.map(job, range(10))
print(res)
if __name__ == '__main__':
by_multiprocess()
输出结果:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
此处我们把任务job和多个参数通过map放进一个Pool中,Pool自动把任务和参数分配给每个cpu去并行运行。
所有多线程和多进程1、2、3中的任务都没有返回值,而此处的任务有返回值,返回值存到了Pool中,便于取用。
apply_async方法
以下代码使用apply_async方法:
import multiprocessing as mp
def job(a):
return a * a
def by_multiprocess():
pool1 = mp.Pool()
res = pool1.apply_async(job, (2,))
print(res.get())
if __name__ == '__main__':
by_multiprocess()
输出结果:
4
apply_async与map相比,有两点不同,一是返回值需要用get方法得到,二是每次调用这个方法只能返回1个值。第二点可以用循环弥补:
import multiprocessing as mp
def job(a):
return a * a
def by_multiprocess():
pool1 = mp.Pool()
multi_res = [pool1.apply_async(job, (i,)) for i in range(10)]
print([res.get() for res in multi_res])
if __name__ == '__main__':
by_multiprocess()
输出结果:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
CPU表现
为了让多进程更直观,我们以map方法为例,在多进程运行时观察CPU的表现,代码:
import multiprocessing as mp
def job(a):
b = 0
for i in range(10000):
for j in range(10000):
b += 1
return a*a
def by_multiprocess():
pool1 = mp.Pool()
res = pool1.map(job,range(20))
print('over')
if __name__ == '__main__':
by_multiprocess()
CPU使用情况:
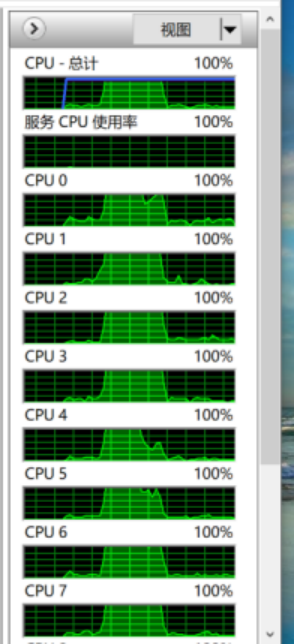
CPU使用情况在任务管理器→性能→打开资源监视器→CPU中。为了让结果明显,我们增加了额外的任务量。
本机有6核,表现为12个CPU,CPU0-CPU11。图中CPU0-CPU7包括图上没出现的其他CPU都出现了高使用率。因为这个代码把任务分配给了每个CPU。
如果只想使用少数CPU,可以设置Pool类属性processes=CPU数目,例如以下代码设置processes=3:
import multiprocessing as mp
def job(a):
b = 0
for i in range(10000):
for j in range(10000):
b += 1
return a*a
def by_multiprocess():
pool1 = mp.Pool(processes = 3)
res = pool1.map(job,range(20))
print('over')
if __name__ == '__main__':
by_multiprocess()
CPU使用情况:

虽然设置CPU数量=3,实际上用到了4个CPU,可能是创建进程也需要额外的CPU。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号