[I.2] 个人作业:软件案例分析
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2025年春季软件工程(罗杰、任健) |
| 这个作业的要求在哪里 | [I.2] 个人作业:软件案例分析 |
| 我在这个课程的目标是 | 学习软件工程知识,通过团队协作开发一个具备实际应用价值的软件,从需求分析、设计、开发到测试和部署,完整经历软件开发生命周期,提高工程实践能力。 |
| 这个作业在哪个具体方面帮助我实现目标 | 通过分析具体的软件案例,为之后的开发提供借鉴意义 |
选题
- 选题类型:开源软件
- 选定软件:nvitop
一、调研与评测
软件评测
基本介绍
nvitop是一款开源的、用于查看NVIDIA GPU状态的交互式监控软件,拥有较为美观的命令行界面和详细的信息显示以及与进程的交互功能
使用流程:
-
安装
nvitop由python开发构建,可以直接通过python包管理器(如pip)安装。
在装有nvitop的python环境中,只需使用nvitop命令即可启动对GPU的监控 -
基本使用
nvitop主要用于没有图形化界面的服务器终端中,直接在命令行中运行nvitop便可启用对NVIDIA GPU实时的监控,如下图所示
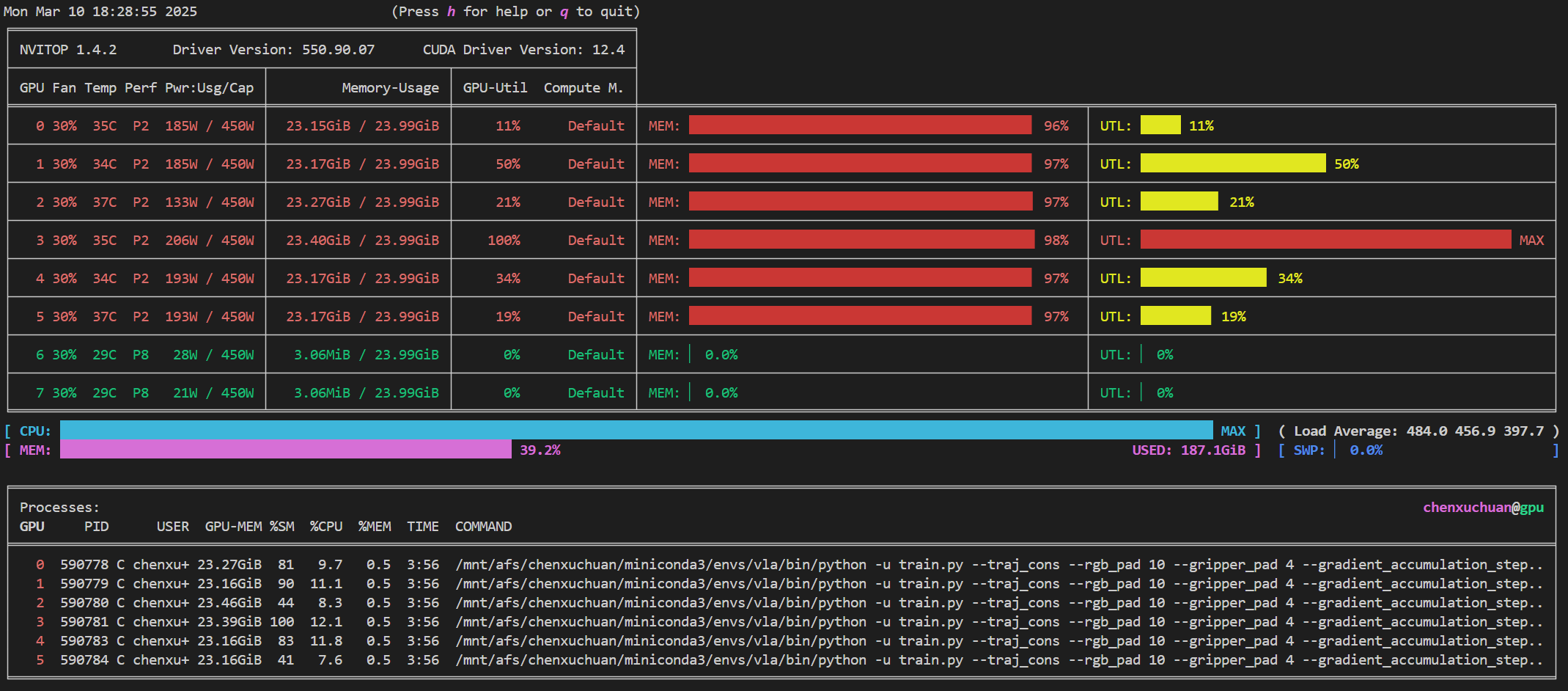
在这个监控页面上,不但显示了GPU的数量、每块GPU的使用率、显存占用、功率、温度等状态,还显示了系统CPU的总使用率和内存的总占用量,还有每块GPU上运行的进程信息。这些信息会实时变化。
同时,如果只是需要查看当前状态而不需要实时更新,则可以使用nvitop -1的命令获取当前这一时刻的GPU状况。
如果想体验更美观的界面,可以加上--colorful选项,输入nvitop --colorful,会得到更美观的界面:

同时,nvitop展示的界面能够根据终端窗口的大小,自动调整展示信息的详细程度。
- 与进程的交互
在监控GPU的使用时,我们还可以直接通过nvitop的监视界面与占用GPU的进程进行交互,以便管理GPU资源。
如图,选中一个进程(如占用0号GPU的进程603389)
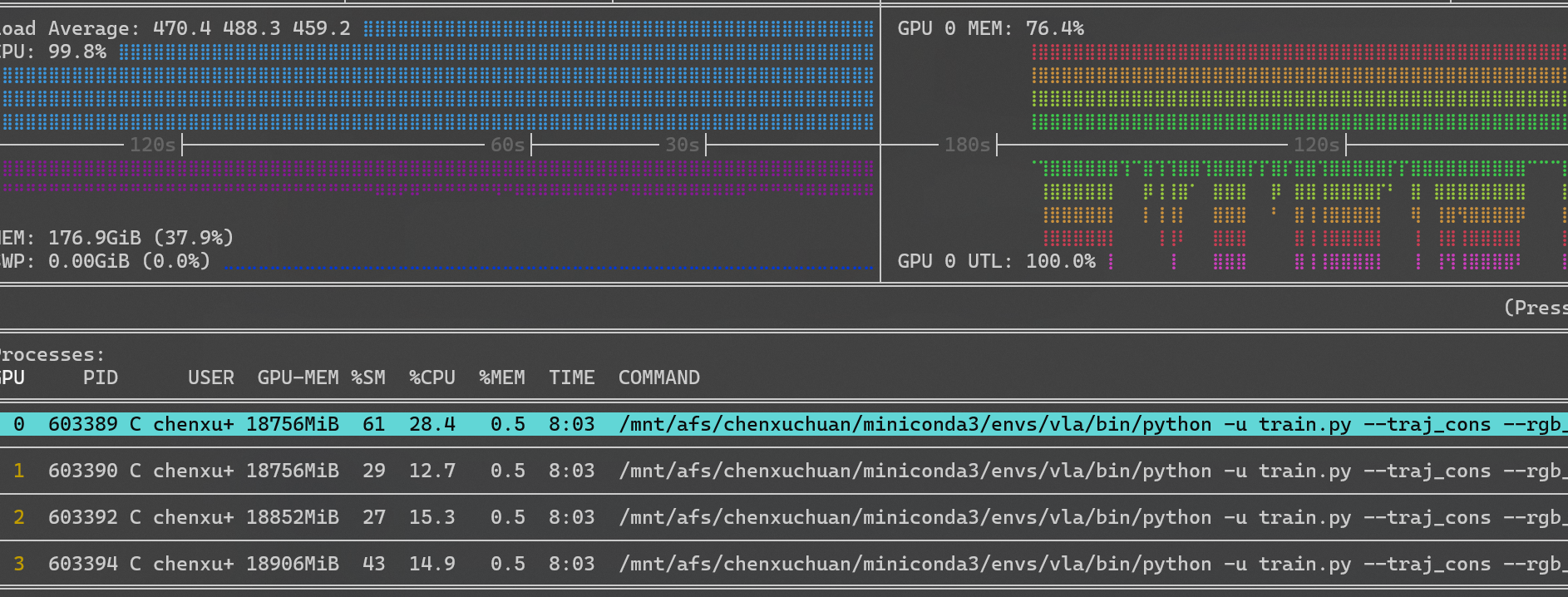
然后,便可以与该进程进行交互。
例如按e显示该进程的环境变量:
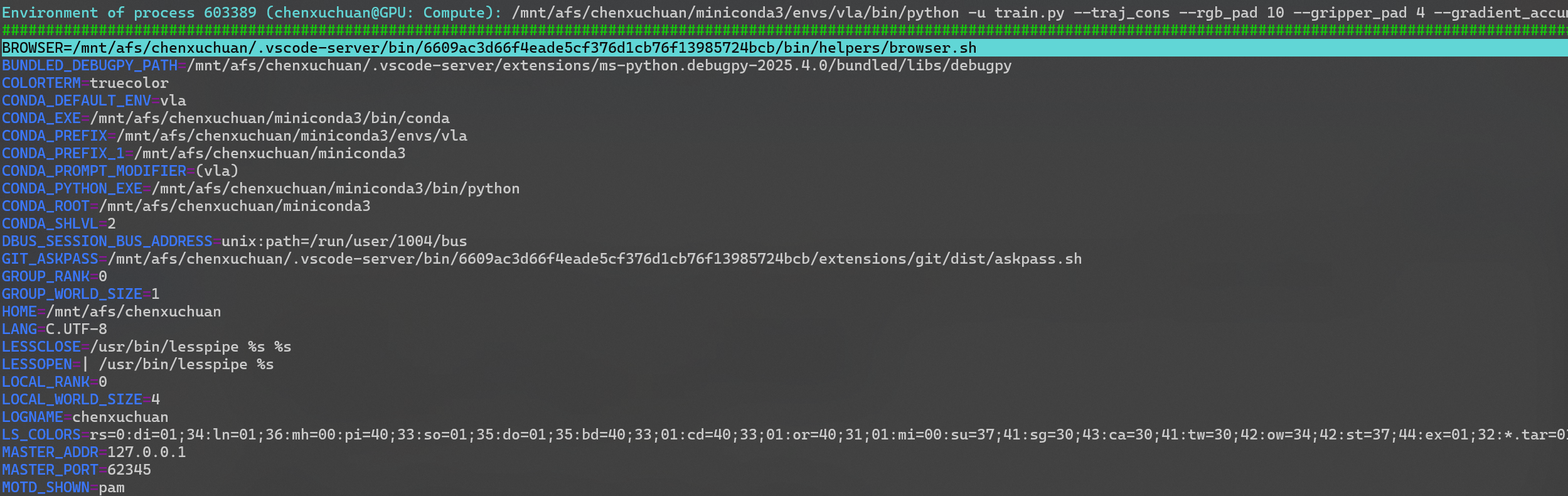
按t显示进程树:

或者按k,向该进程发送终止信号:
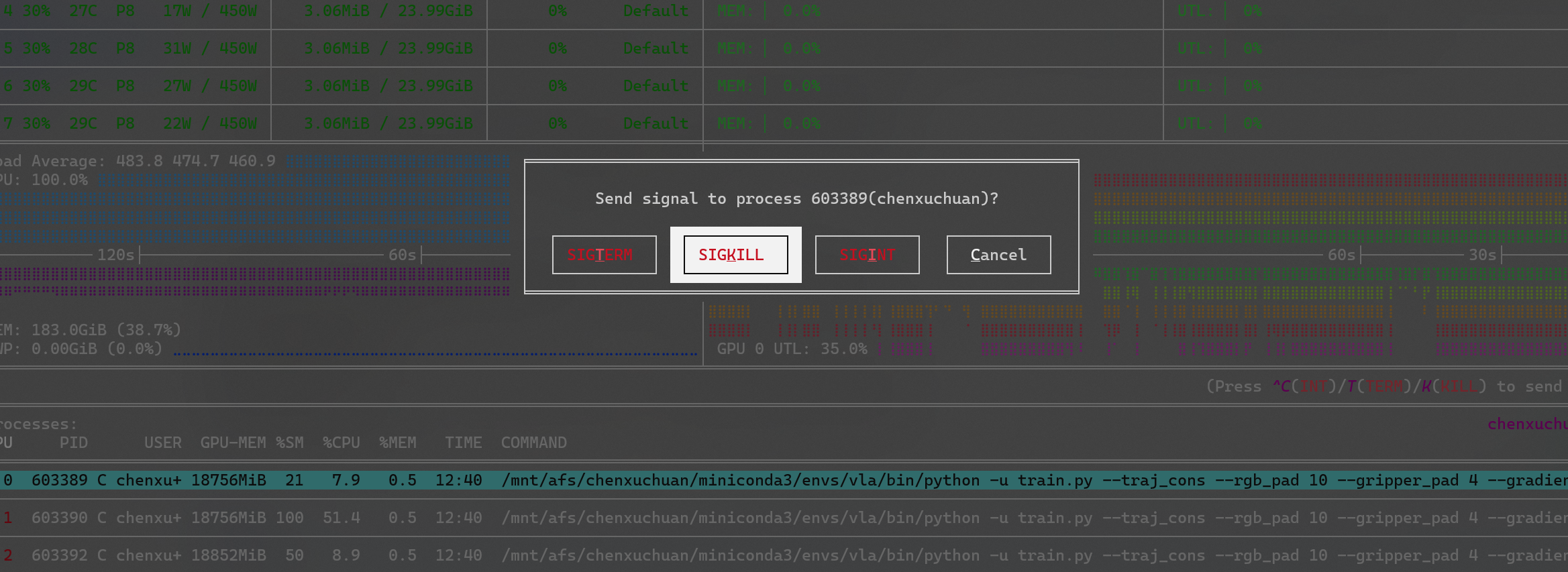
- API
nvitop不仅可以在命令行中作为监控控制台,还可以作为API嵌入python程序,通过在python程序中调用来获得设备信息。
例如下面的python程序中就利用了nvitop的信息来选择空闲显存大于8G的显卡序号
软件解决的用户需求
- 在使用NVIDIA GPU进行模型训练或推理时,需要监控GPU的使用情况
- 在开发使用GPU的应用程序时,需要获取GPU的各项信息
软件在数据量/界面/功能/准确度/用户体验上各有什么优缺点?
数据量
nvitop不需要任何附加数据,只从底层的GPU接口读取信息并显示
界面
优点:十分美观,能够实时渲染,重要的信息优先显示,其他信息折叠显示,根据窗口大小自动调整不同信息的显示方式。
缺点:有最小的窗口大小限制,不适合在手机的终端窗口上查看。
功能
优点:GPU状态信息显示齐全,比NVIDIA官方的nvidia-smi显示的信息还要详细,且支持在终端中与进程直接交互,方便用户查看进程详情或向进程发送信号;还支持在python程序中调用
缺点:没有更加贴合当前深度学习的使用场景,实现分布式训练任务的多进程统一管理
准确度
优点:能够十分准确地读出GPU设备型号、参数,以及当前的处理器使用量、温度、显存占用量等参数,而且能够实时更新
缺点:更新频率为1Hz,较慢
用户体验
优点:在命令行中也能基于用户贴近图形化界面的操作体验,在支持鼠标的终端中可以直接使用鼠标进行操作;不同的信息以及不同的使用率数值都用不同颜色加以区分,可读性很好;在多种大小的窗口中都能详略得当地显示必要的信息。
缺点:缺少自定义显示设置的选项。
改进意见
- 加入对主流深度学习框架(如pytorch)的支持,识别训练任务,以进行统一管理
- 加入自定义布局设置
用户调研
我采访了一位nvitop的资深用户,该位同学由于在科研中经常需要监控模型训练时的GPU使用情况,因此对GPU监控软件较为熟悉,有丰富的使用经验与见解
使用需求

同类产品比较

bug

改进建议

评分

评测结论:
a) 非常不推荐
b) 不推荐
c) 一般
d) 好,不错
e) 非常推荐
结论:e) 非常推荐
Bug分析和提交
Bug 1:在docker等虚拟化容器中,无法显示占用GPU的进程
-
测试环境:docker container,Ubuntu 22.04镜像,python3.9
-
可复现性:必然发生。在docker的环境中安装nvitop,运行一个使用GPU的程序(如训练模型),再启动nvitop,则能看到GPU被占用但无对应的进程
-
Bug具体情况描述:在docker环境中使用nvitop,可以读出GPU的使用量等状态参数,但无法显示对应进程信息,如下图所示
![]()
-
Bug分析:
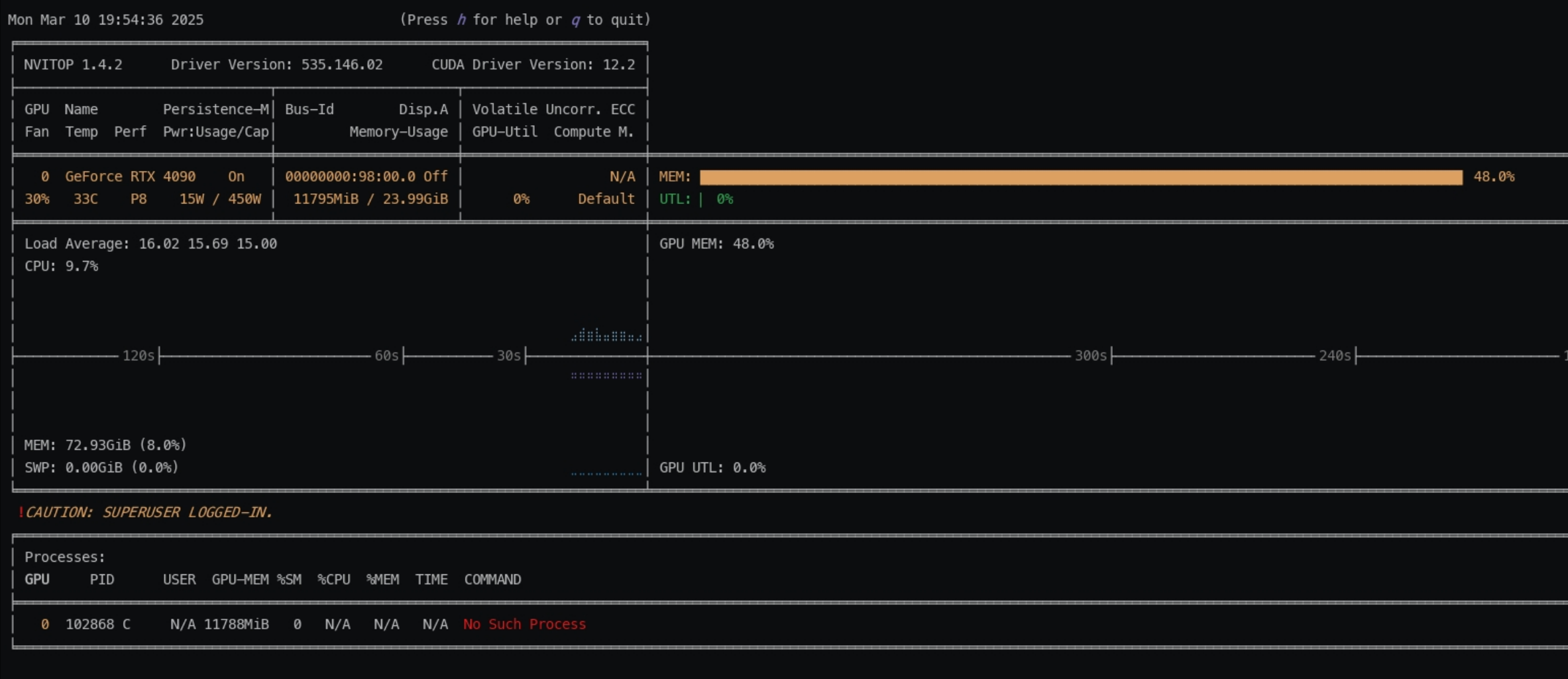
详细的 GPU 进程信息(比如每个进程具体的 PID、占用资源等)往往依赖于主机的进程表和系统级别的信息,因此,nvitop在docker环境中运行可能存在以下几个问题:
-
默认情况下,容器拥有独立的PID命名空间,只能看到容器内部运行的进程,而无法访问主机上运行的进程。由于占用GPU的进程信息来自主机的进程表,容器内部的nvitop无法获取到这些信息。
-
即使通过NVIDIA Container Toolkit将GPU设备挂载到容器中,容器内部的工具(如nvidia-smi或nvitop)在没有额外配置的情况下,通常只会获取到经过隔离后的有限信息。
-
部分监控工具在设计时默认在宿主机环境下运行,依赖完整的系统信息。在容器内运行时,系统信息不全导致了GPU进程的详细信息显示不全的问题
Bug的严重性:中等。无法获取到进程但仍能显示GPU占用情况,主要功能仍然正常,但无法与具体进程进行交互了
Bug可能来源:开发人员可能未在docker虚拟环境中对nvitop进行测试。除此之外,在docker内运行的程序(nvitop)访问host的进程信息也确实存在困难,尽管作者提供了docker run --pid=host的修复方法,但更多时候用户无法更改docker的启动设置,因此难以解决此bug。
- Bug改进建议:通过htop查看对应pid的进程的详细信息。
Bug 2: 某些终端中使用--colorful时,资源占用条显示错乱
-
测试环境:Ubuntu 22.04, python3.10
-
可复现性:在该终端中必然出现,但在其他终端中正常。
-
Bug具体情况描述:在该终端中,使用
nvitop --colorful,出现下图所示的占用条显示错乱的情况:
![]()
-
Bug分析:
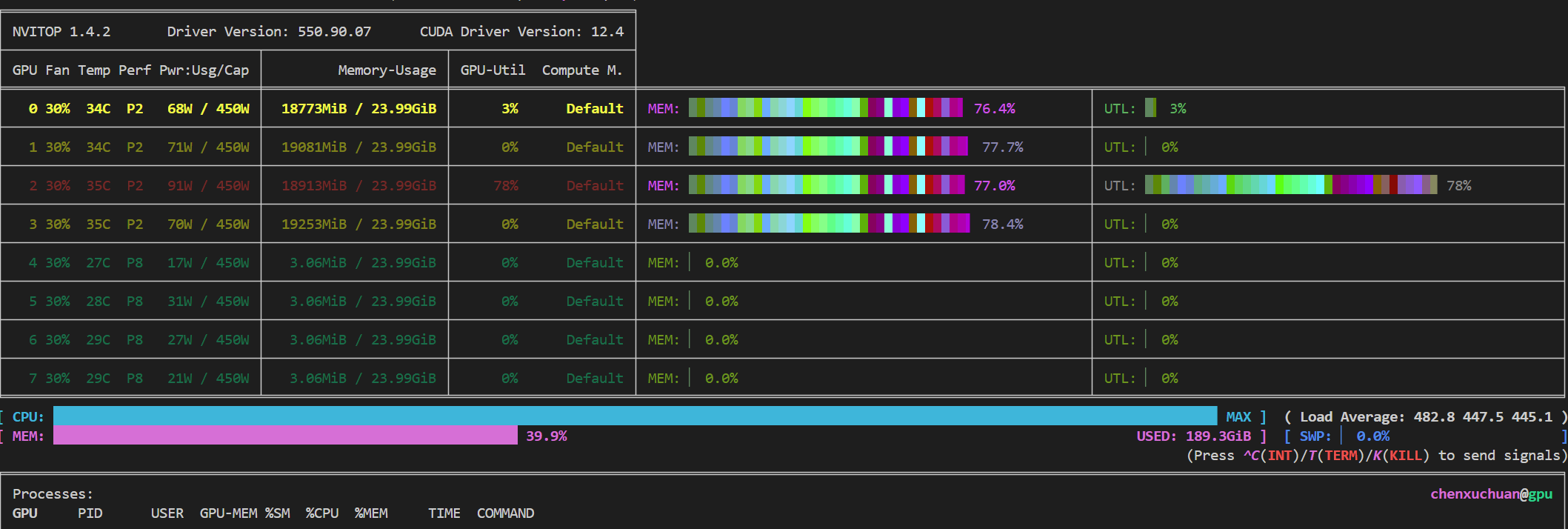
nvitop源代码(nvitop/api/termcolor.py)中使用了ANSI转义码("\033...")来输出自定义RGB颜色。如果使用的终端或终端模拟器不完全支持24位颜色,可能会导致颜色显示异常,而显示效果可能变成一些不可预期的混合色。另外,nvitop源码(nvitop/tui/library/libcurses.py)中使用了curses库来管理颜色初始化、颜色对的生成以及属性设置,如果终端环境不支持该库自定义颜色(例如仅支持256色而非真彩色)则会导致原本--colorful下由绿到红的渐变色块变为混乱色块
Bug的严重性:轻微。--colorful下的颜色显示异常不影响普通模式的颜色显示,在普通模式下仍然可以正常使用。
Bug可能来源:作者可能没有对多种颜色设置的终端做适配。
- Bug改进建议:增加对多种颜色设置终端的支持。
二、分析
1. 工作量分析
该软件主要分为后端:读取底层硬件与系统信息,以及前端:TUI终端界面显示。如果有6个计算机系大学毕业生,可参考底层硬件或系统的接口文档进行开发,加上进行测试与兼容性适配的时间,大约需要1-2个月即可完成。
2. 软件质量分析
同类软件比较
除nvitop外,目前主流的GPU监控软件有NVIDIA官方的监控工具nvidia-smi与开源的nvtop。
与nvitop相比,nvidia-smi只有最基本的查看GPU当前状态功能,如下所示
nvidia-smi的界面较为原始,没有nvitop进度条式的使用量显示,而且没有实时更新的功能,也无法与进程进行交互
nvtop则比较接近nvitop,拥有TUI界面,以及详细的GPU和系统状况,可以实时更新。nvtop最大的优点在于它不仅支持NVIDIA的GPU,也支持AMD、华为昇腾等其他厂商的GPU:
但缺点在于界面美观度和可读性不及nvitop,而且与进程的交互有限
由此,个人对它们的排名为nvitop > nvtop > nvidia-smi
该软件团队在软件工程方面可以提高的一个重要方面:对不同用户环境进行充分的适配性测试
三、建议和规划
市场现状
1. 市场概况
该软件主要面向在开发与生产环境中使用GPU的人群,该市场覆盖面较广,直接的用户是高校、企业和科研院所中AI、图形相关方向的实验室,潜在用户有图形图像领域从业者、游戏玩家等
2. 竞争产品
目前与nvitop构成竞争关系的有nvtop,与NVIDIA官方的nvidia-smi尚不构成竞争关系
3. 产品定位
nvitop优势在于美观、易操作的界面以及可交互性设计,劣势在于需要依托python环境运行;而nvtop优势在于无需python环境且支持其他厂商的GPU,劣势在于界面设计不够吸引用户
目前使用GPU主要用户还是以NVIDIA的卡为主,尽管nvitop从知名度(star数量)上不如nvtop,但更新频率比nvtop更快,它们在NVIDIA GPU的监视器领域不分伯仲。
市场与产品生态
1. 核心用户群体
-
深度学习研究人员:需要在GPU上训练大型模型,对GPU资源的使用情况高度关注。
-
系统管理员:负责维护包含多块GPU的服务器或数据中心,需要实时监控GPU的健康状态和使用效率。
-
游戏开发者:在开发和优化游戏时,需要了解GPU的性能表现,以确保游戏的流畅运行。
典型用户画像:
-
学历:通常具有计算机科学、电子工程或相关领域的本科及以上学历。
-
年龄:多为25至40岁之间的专业人士。
-
专业:计算机科学、人工智能、数据科学、信息技术等。
-
爱好:对技术创新、编程、性能优化和新兴科技感兴趣。
-
收入:根据地区和经验水平,年收入范围可能在中等到高等水平。
用户需求分析
-
表面需求:实时监控GPU的使用情况,管理和优化GPU资源分配,确保系统稳定运行。
-
潜在需求:通过深入分析GPU使用数据,优化应用性能,降低运营成本,提高工作效率。
2. 用户群体之间的关系及生态构建
这些用户群体之间存在密切的联系。例如,深度学习研究人员和游戏开发者都依赖系统管理员提供的高性能计算环境。这种协作关系可以促进知识共享和最佳实践的传播,形成一个以GPU性能优化为核心的用户生态系统。
3. 产品的子产品及相关产品生态
nvitop的功能可以扩展到其他相关领域,例如:
-
CUDA设备选择工具:帮助用户在多GPU环境中选择合适的设备。
-
机器学习框架回调函数:与TensorFlow或PyTorch等框架集成,实时监控训练过程中的GPU使用情况。
-
TensorBoard集成:将GPU使用数据可视化,方便分析和调试。
这些子产品之间的协同作用,可以构建一个完整的产品生态系统,满足用户在GPU资源管理和性能优化方面的多样化需求。
产品规划
1. 新功能设计
在现有 nvitop 软件的基础上,新增以下功能:
-
历史数据记录与分析:用户需要了解 GPU 使用的长期趋势,以进行资源规划和性能优化。因此,可以在nvitop中记录 GPU 使用情况的历史数据,提供趋势分析和性能报告。通过集中监控和历史分析,用户可以更有效地管理 GPU 资源。
-
多节点集群监控:在大型计算集群中,集中监控有助于提高管理效率,减少运维成本。通过支持对多台服务器的 GPU 资源进行集中监控,使用户运维成本降低。
-
自定义告警系统:及时的告警通知可以帮助用户迅速响应异常情况,保障系统稳定性。用户可设置 GPU 使用的阈值,当超过阈值时,系统会发送告警通知。
创新点:
-
集成化解决方案:将实时监控、历史分析、集群管理和告警系统集成到一个平台中,提供全方位的 GPU 管理功能。
-
用户自定义:允许用户根据自身需求设置监控指标和告警阈值,增强产品的灵活性和适用性。
NABCD 分析:
-
N(Need,需求):用户需要更全面的 GPU 监控工具,以满足复杂的计算环境和资源管理需求。
-
A(Approach,做法):在现有 nvitop 的基础上,新增历史数据记录、多节点监控和自定义告警功能,提升产品的功能深度和广度。
-
B(Benefit,好处):用户可以通过新功能实现更高效的资源管理、性能优化和问题预防,降低运维成本。
-
C(Competitors,竞争):与其他 GPU 监控工具相比,nvitop 的新功能提供了更全面的解决方案,增强了产品的市场竞争力。
-
D(Delivery,推广):通过技术博客、行业论坛和合作伙伴关系等渠道,推广新版本的功能优势,吸引目标用户群体。
2. 项目团队角色配置:
项目经理(1人):负责整体项目规划、进度控制和团队协调。
后端开发工程师(2人):负责对接底层设备接口,实现历史数据记录、多节点监控等核心功能,提供前端可以调用的接口。
前端开发工程师(1人):负责TUI界面美工设计与实现,确保用户体验友好。
测试工程师(1人):负责制定测试计划,执行功能测试和性能测试,确保软件质量。
运维工程师(1人):负责部署环境搭建、监控系统配置,以及发布后的维护工作。
3. 时间规划:
第1-2周:需求分析与设计,明确功能需求和技术方案,约定前后端接口协议。
第3-10周:先并行进行后端与前端开发,完成各模块主要功能,然后进行对接,实现历史记录、多GPU集中管理以及资源告警等主要功能
第11-13周:测试阶段,进行全部功能的测试、性能测试和安全测试,同时修复发现的问题。
第14-15周:部署与上线准备,编写部署文档,进行预发布测试。
第16周:正式发布新版本,启动推广计划。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号