[Python] 爬虫系统与数据处理实战 Part.10 网页排重、自动化分类、实体识别、搜索引擎
线性回归
逻辑回归
SVM
单层感知缺陷
神经网络
激活函数
学习率
欠拟合,过拟合
文本分类
- 长文本:SVM
- 短文本:CNN
关键词提取:TF-IDF
实体识别:NER(named entity recognition)
- 人工智能非常依赖于各种先验知识,依赖于系统方案的设立
- 数据源:爬虫对人工智能非常重要
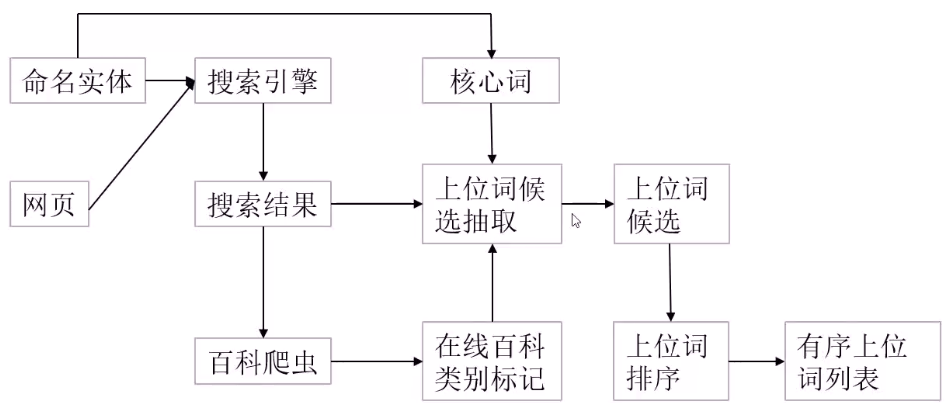
PyGoose:自动抽取图片、文本
- baidu 爬虫 -> 抽取、快照 url -> 下载目标网页 -> pygoose 抽取 -> 分词 -> 统计词频
验证码识别
- Pilow:图像处理
- Tesseract-Ocr:图片识别
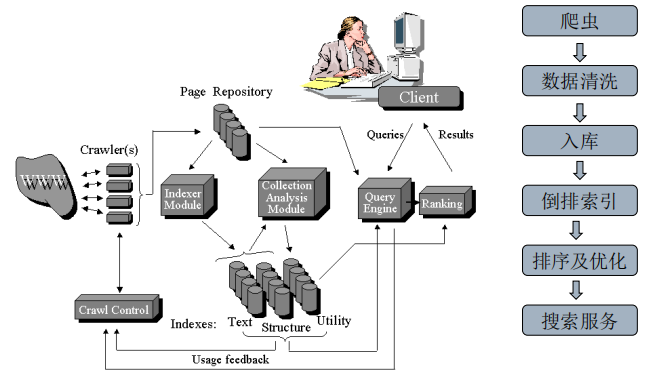
搜索引擎
倒排索引
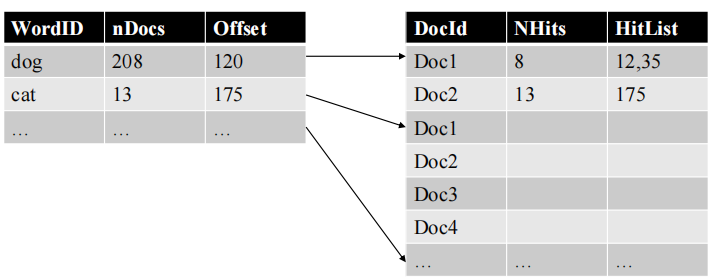

搜索过程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号