[Python] 爬虫系统与数据处理实战 Part.6 微博
爬取工具
- chromedriver
- Selenium
- PhantomJS:基于nodejs,无界面服务器,适合大规模爬虫集群部署
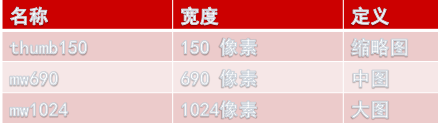
图片
- http://wx2.sinaimg.cn/thumb150/4b7a8989ly1fcws2sryvrj22p81sub2a.jpg
- re.findall('/[^/]+)$',image.get_attribute('src')):找到最后一个/,得到它后面的所有内容
- http://存储域名/分辨率/文件名
翻页
- scrollTo
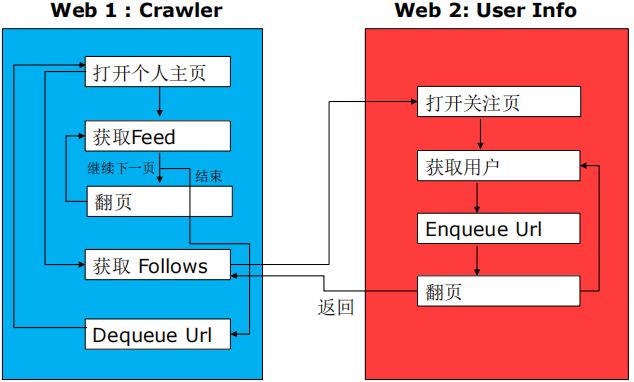
微博抓取框架
- crawler:抓取发过的微博
- user info:抓取关注的用户
weibo.py


1 # -*- coding: utf-8 -*- 2 import hashlib 3 import threading 4 from collections import deque 5 6 from selenium import webdriver 7 import re 8 from lxml import etree 9 import time 10 from pybloomfilter import BloomFilter 11 12 from selenium.webdriver.common.desired_capabilities import DesiredCapabilities 13 14 user_agent = ( 15 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) " + 16 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.57 Safari/537.36" 17 ) 18 19 # 进入浏览器设置 20 options = webdriver.ChromeOptions() 21 # 设置中文 22 options.add_argument('lang=zh_CN.UTF-8') 23 24 # ---------- Important ---------------- 25 # 设置为 headless 模式,调试的时候可以去掉 26 # ------------------------------------- 27 #options.add_argument("--headless") 28 29 # 更换头部 30 # options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"') 31 feeds_crawler = webdriver.Chrome(chrome_options=options) 32 33 feeds_crawler.set_window_size(1920, 1200) # optional 34 35 36 user_crawler = webdriver.Chrome(chrome_options=options) 37 user_crawler.set_window_size(1920, 1200) # optional 38 39 domain = 'weibo.com' 40 url_home = "https://passport.weibo.cn/signin/login" 41 42 download_bf = BloomFilter(1024*1024*16, 0.01) 43 cur_queue = deque() 44 45 # feeds_crawler.find_element_by_class_name('WB_detail') 46 # time = feeds_crawler.find_elements_by_xpath('//div[@class="WB_detail"]/div[@class="WB_from S_txt2"]/a[0]').text 47 48 seed_user = 'http://weibo.com/yaochen' 49 50 min_mblogs_allowed = 100 51 max_follow_fans_ratio_allowed = 3 52 53 def full_url(url): 54 if url.startswith('//'): 55 return 'https:' + url 56 elif url.startswith('/'): 57 return 'https://' + domain + url 58 return url 59 60 def extract_user(users): 61 print('extract user') 62 for i in range(0,20): 63 for user_element in user_crawler.find_elements_by_xpath('//*[contains(@class, "follow_item")]'): 64 tried = 0 65 while tried < 3: 66 try: 67 user = {} 68 user['follows'] = re.findall('(\d+)', user_element.find_element_by_xpath('.//div[@class="info_connect"]/span').text)[0] 69 user['follows_link'] = user_element.find_element_by_xpath('.//div[@class="info_connect"]/span//a').get_attribute('href') 70 user['fans'] = re.findall('(\d+)', user_element.find_elements_by_xpath('.//div[@class="info_connect"]/span')[1].text)[0] 71 user['fans_link'] = user_element.find_elements_by_xpath('.//div[@class="info_connect"]/span//a')[1].get_attribute('href') 72 user['mblogs'] = re.findall('(\d+)', user_element.find_elements_by_xpath('.//div[@class="info_connect"]/span')[2].text)[0] 73 user_link = user_element.find_element_by_xpath('.//div[contains(@class,"info_name")]/a') 74 user['link'] = re.findall('(.+)\?', user_link.get_attribute('href'))[0] 75 if user['link'][:4] != 'http': 76 user['link'] = domain + user['link'] 77 user['name'] = user_link.text 78 user['icon'] = re.findall('/([^/]+)$', user_element.find_element_by_xpath('.//dt[@class="mod_pic"]/a/img').get_attribute('src'))[0] 79 # name = user_element.find_element_by_xpath('.//a[@class="S_txt1"]') 80 81 print('--------------------') 82 print(user['name'] + ' follows: ' + user['follows'] + ' blogs:' + user['mblogs']) 83 print(user['link']) 84 85 # 如果微博数量少于阈值或者关注数量与粉丝数量比值超过阈值,则跳过 86 if int(user['mblogs']) < min_mblogs_allowed or int(user['follows'])/int(user['fans']) > max_follow_fans_ratio_allowed: 87 break 88 89 enqueueUrl(user['link']) 90 users.append(user) 91 break 92 except Exception: 93 time.sleep(1) 94 tried += 1 95 if go_next_page(user_crawler) is False: 96 return users 97 98 return users 99 100 def extract_feed(feeds): 101 for i in range(0,20): 102 scroll_to_bottom() 103 for element in feeds_crawler.find_elements_by_class_name('WB_detail'): 104 tried = 0 105 while tried < 3: 106 try: 107 feed = {} 108 feed['time'] = element.find_element_by_xpath('.//div[@class="WB_from S_txt2"]').text 109 feed['content'] = element.find_element_by_class_name('WB_text').text 110 feed['image_names'] = [] 111 for image in element.find_elements_by_xpath('.//li[contains(@class,"WB_pic")]/img'): 112 feed['image_names'].append(re.findall('/([^/]+)$', image.get_attribute('src'))) 113 feeds.append(feed) 114 print('--------------------') 115 print(feed['time']) 116 print(feed['content']) 117 break 118 except Exception: 119 tried += 1 120 time.sleep(1) 121 if go_next_page(feeds_crawler) is False: 122 return feeds 123 124 def scroll_to_bottom(): 125 # 最多尝试 20 次滚屏 126 print( 'scroll down') 127 for i in range(0,50): 128 # print('scrolling for the %d time' % (i)) 129 feeds_crawler.execute_script('window.scrollTo(0, document.body.scrollHeight)') 130 html = feeds_crawler.page_source 131 tr = etree.HTML(html) 132 next_page_url = tr.xpath('//a[contains(@class,"page next")]') 133 if len(next_page_url) > 0: 134 return next_page_url[0].get('href') 135 if len(re.findall('点击重新载入', html)) > 0: 136 print('scrolling failed, reload it') 137 feeds_crawler.find_element_by_link_text('点击重新载入').click() 138 time.sleep(1) 139 140 def go_next_page(cur_driver): 141 try: 142 next_page = cur_driver.find_element_by_xpath('//a[contains(@class, "page next")]').get_attribute('href') 143 print('next page is ' + next_page) 144 cur_driver.get(full_url(next_page)) 145 time.sleep(3) 146 return True 147 except Exception: 148 print('next page is not found') 149 return False 150 151 def fetch_user(user_link): 152 print('downloading ' + user_link) 153 feeds_crawler.get(user_link) 154 time.sleep(5) 155 156 # 提取用户姓名 157 account_name = get_element_by_xpath(feeds_crawler, '//h1')[0].text 158 159 photo = get_element_by_xpath(feeds_crawler, '//p[@class="photo_wrap"]/img')[0].get('src') 160 161 account_photo = re.findall('/([^/]+)$', photo) 162 163 # 提取他的关注主页 164 follows_link = get_element_by_xpath(feeds_crawler, '//a[@class="t_link S_txt1"]')[0].get('href') 165 166 print('account: ' + account_name) 167 print('follows link is ' + follows_link) 168 169 user_crawler.get( full_url(follows_link) ) 170 171 feeds = [] 172 users = [] 173 174 t_feeds = threading.Thread(target=extract_feed, name=None, args=(feeds,)) 175 # t_users = threading.Thread(target=extract_user, name=None, args=(users,)) 176 177 t_feeds.setDaemon(True) 178 # t_users.setDaemon(True) 179 180 t_feeds.start() 181 # t_users.start() 182 183 t_feeds.join() 184 # t_users.join() 185 186 def get_element_by_xpath(cur_driver, path): 187 tried = 0 188 while tried < 6: 189 html = cur_driver.page_source 190 tr = etree.HTML(html) 191 elements = tr.xpath(path) 192 if len(elements) == 0: 193 time.sleep(1) 194 tried += 1 195 continue 196 return elements 197 198 def login(username, password): 199 print('Login') 200 feeds_crawler.get(full_url(url_home)) 201 user_crawler.get(full_url(url_home)) 202 time.sleep(8) 203 print('find click button to login') 204 feeds_crawler.find_element_by_id('loginName').send_keys(username) 205 feeds_crawler.find_element_by_id('loginPassword').send_keys(password) 206 # 执行 click() 207 feeds_crawler.find_element_by_id('loginAction').click() 208 # 也可以使用 execute_script 来执行一段 javascript 209 # feeds_crawler.execute_script('document.getElementsByClassName("W_btn_a btn_32px")[0].click()') 210 # 211 user_crawler.find_element_by_id('loginName').send_keys(username) 212 user_crawler.find_element_by_id('loginPassword').send_keys(password) 213 # # 执行 click() 214 user_crawler.find_element_by_id('loginAction').click() 215 # for cookie in feeds_crawler.get_cookies(): 216 # user_crawler.add_cookie(cookie) 217 218 def enqueueUrl(url): 219 try: 220 md5v = hashlib.md5(url.encode('utf8')).hexdigest() 221 if md5v not in download_bf: 222 print(url + ' is added to queue') 223 cur_queue.append(url) 224 download_bf.add(md5v) 225 # else: 226 # print('Skip %s' % (url)) 227 except ValueError: 228 pass 229 230 def dequeuUrl(): 231 return cur_queue.popleft() 232 233 def crawl(): 234 while True: 235 url = dequeuUrl() 236 fetch_user(url) 237 238 if __name__ == '__main__': 239 try: 240 enqueueUrl(seed_user) 241 login('18600663368', 'Xi@oxiang66') 242 crawl() 243 finally: 244 feeds_crawler.close() 245 user_crawler.close()
微博接口
- https://m.weibo.cn/
- 抓取效率高,但要控制频率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号