[DB] Hive
简介
- 基于HDFS的数据仓库工具
- 基于HDFS上的数据分析引擎
- 2.x 前:SQL -----> Hive ----> MapReduce
- 2.x 后:推荐执行引擎为 Spark
- 支持SQL子集
架构
- 执行方式:CLI、JDBC、HWI(推荐HUE)
- Hive元信息:表名、列名、列的类型、分区、桶,存储在MySQL中
- 读取MySQL得到Hive元信息
- 数据在HDFS中

安装
- 嵌入模式
- 不需要MySQL,使用Hive自带的Derby数据库存储元信息(Derby较小,嵌入到Hive中)
-
- 只支持一个连接,用于开发和测试
- 本地模式
- 需要MySQL,Hive和MySQL在一起
- 连接驱动:mysql-connector-java-5.1.43-bin
- 远程模式
- 需要MySQL,Hive和MySQL不在一起
- 在 hive-site.xml 中写入mysql地址
- mysql中TBLS存储Hive表信息,COLUMNS_2保存列的信息
文件存储
分类
- 列式存储:每个字段类型相同,数据压缩度高
- 行式存储:查询快
Hive
- TEXTFILE:行存储,默认格式,数据不压缩,磁盘开销大
- ORC:列存储,一个ORC文件分为若干Stripe,一个Stripe分为indexData(列索引),rowData(数据),StripFooter(元数据信息),默认压缩方式zlib
- PARQUET:列存储,面向分析型业务,以二进制方式存储
性能分析
- 压缩比:
- 查询速度
数据模型
- 内部表:类似MySQL中的表


-
- 导入数据:load(剪切)
- 静默模式:hive -S(不打印日志)
- 分区表:建立分区,提高效率
- 一个分区对应一个HDFS文件



1 create table emp_part 2 (empno int, 3 ename string, 4 job string, 5 mgr int, 6 hiredate string, 7 sal int, 8 comm int 9 )partitioned by (deptno int) 10 row format delimited fields terminated by ',';
-
- select * from emp_part where deptno=10;
- 打印执行计划:explain select * from emp_part where deptno=10;
- 外部表:只定义表结构,数据保存在HDFS的某目录下
- 桶表:类似Hash分区,对要插入的数据进行hash运算再插入,查询效率提高,插入效率降低
- 视图:
- 是一个虚表,查询操作和普通表一样,但不存储数据,数据来自底层依赖的基表
- 作用:简化复杂的查询(不提高效率)
执行
- 执行HQL,HQL是SQL的子集
- 转换为MapReduce程序执行
- 使用 sqoop 导入 mysql 的数据,或将Hive的数据导出到mysql
JDBC查询
- 启动 hive thrift 服务
- hive --server hiveserver2
- 将hive lib下的jar包下载到本地,添加依赖
JDBCUtils.java
1 package jdbc; 2 3 import java.sql.Connection; 4 import java.sql.DriverManager; 5 import java.sql.ResultSet; 6 import java.sql.SQLException; 7 import java.sql.Statement; 8 9 /* 10 * 工具类: 11 * 1、获取数据库Hive链接 12 * 2、释放资源 13 */ 14 public class JDBCUtils { 15 16 //Hive数据库的驱动 17 private static String driver = "org.apache.hive.jdbc.HiveDriver"; 18 19 //Hive位置 20 private static String url = "jdbc:hive2://192.168.174.111:7777/default"; 21 22 //注册驱动 23 static{ 24 try { 25 Class.forName(driver); 26 } catch (ClassNotFoundException e) { 27 e.printStackTrace(); 28 throw new ExceptionInInitializerError(e); 29 } 30 } 31 32 //获取链接 33 public static Connection getConnection(){ 34 try { 35 return DriverManager.getConnection(url); 36 } catch (SQLException e) { 37 e.printStackTrace(); 38 } 39 return null; 40 } 41 42 public static void release(Connection conn,Statement st,ResultSet rs){ 43 if(rs != null){ 44 try { 45 rs.close(); 46 } catch (SQLException e) { 47 e.printStackTrace(); 48 }finally{ 49 rs = null; 50 } 51 } 52 53 if(st != null){ 54 try { 55 st.close(); 56 } catch (SQLException e) { 57 e.printStackTrace(); 58 }finally{ 59 st = null; 60 } 61 } 62 63 if(conn != null){ 64 try { 65 conn.close(); 66 } catch (SQLException e) { 67 e.printStackTrace(); 68 }finally{ 69 conn = null; 70 } 71 } 72 } 73 }
TestHive.java
1 package jdbc; 2 3 import java.sql.Connection; 4 import java.sql.ResultSet; 5 import java.sql.Statement; 6 7 public class TestHive { 8 9 public static void main(String[] args) { 10 //查询: select * from emp1; 11 Connection conn = null; 12 Statement st = null; 13 ResultSet rs = null; 14 try{ 15 conn = JDBCUtils.getConnection(); 16 st = conn.createStatement(); 17 18 //执行SQL 19 rs = st.executeQuery("select * from emp1"); 20 while(rs.next()){ 21 String ename = rs.getString("ename"); 22 System.out.println(ename); 23 } 24 }catch(Exception ex){ 25 ex.printStackTrace(); 26 }finally{ 27 //释放资源 28 JDBCUtils.release(conn, st, rs); 29 } 30 } 31 }
自定义函数
- UDF:User Define Function,封装业务逻辑,本质是java程序
MyConcatString
1 package demo.udf; 2 3 import org.apache.hadoop.hive.ql.exec.UDF; 4 5 public class MyConcatString extends UDF{ 6 public String evaluate(String a,String b) { 7 return a+"**************"+b; 8 } 9 }
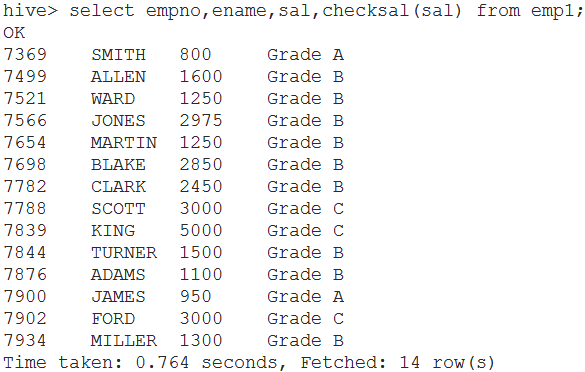
CheckSalaryGrade
1 package demo.udf; 2 3 import org.apache.hadoop.hive.ql.exec.UDF; 4 5 public class CheckSalaryGrade extends UDF{ 6 public String evaluate(String salary) { 7 int sal = Integer.parseInt(salary); 8 if(sal < 1000) return "Grade A"; 9 else if(sal>=1000 && sal<3000) return "Grade B"; 10 else return "Grade C"; 11 } 12 }
- 把package打包为jar包,上传到/root/tmp
- 部署jar包
- 把jar包加入Hive的Classpath
- add jar /root/tmp/MyUDF.jar;
- 为自定义函数创建别名
- create temporary tunction myconcat as 'udf.MyConcatString';
- create temporary tunction checksal as 'udf.CheckSalaryGrade';
- 把jar包加入Hive的Classpath

命令
- 启动:bin/hive
- 查看库:show databases;
- 创建库:create database db_hive;
- 建表:create table school(name string,age int);
- 插入数据:insert into school(name,age) values("liubei",20);
- 查看数据:select * from school;
- 删除表:drop table [table name];
- 删除表中数据:truncate table [table name];
- 按分区删除数据:alter table table_name drop partition (partition_name='分区名')
参考
hive报错
https://blog.csdn.net/qq_40048866/article/details/90041277
https://www.cnblogs.com/lijinze-tsinghua/p/8563054.html
https://blog.csdn.net/SunnyYoona/article/details/51648871
beeline
https://www.cnblogs.com/lenmom/p/11218807.html
https://blog.csdn.net/leanaoo/article/details/83351240
Hive set
https://meihuakaile.github.io/2018/10/19/hive-set%E8%AE%BE%E7%BD%AE/
存储格式
https://www.cnblogs.com/wuxiaolong4/p/11809291.html
https://www.cnblogs.com/wujin/p/6208734.html
应用场景
https://zhuanlan.zhihu.com/p/297769662
Hadoop和数据仓库关系
https://blog.csdn.net/qq_42580464/article/details/80953447
http://www.kokojia.com/article/27501.html
https://www.cnblogs.com/zzjhn/p/10563148.html
http://database.ctocio.com.cn/sjk/2020/0403/15462.html
https://www.zhihu.com/question/19777504
hive分区
http://lxw1234.com/archives/2015/06/284.htm
https://blog.csdn.net/qq_36743482/article/details/78418343
https://blog.csdn.net/TylerPY/article/details/101313177
hive动态分区
https://www.cnblogs.com/sunpengblog/p/10396442.html
load数据
https://blog.csdn.net/qq_24309787/article/details/82690198
https://programskills.blog.csdn.net/article/details/89605107

 浙公网安备 33010602011771号
浙公网安备 33010602011771号