[DB] Redis
为什么用Redis
- 是什么
- 一个小程序
- 缓存 & 数据库
- 单线程worker
- 新版本:IO threads
- epoll:多路复用
- 与Memcache区别
- 支持持久化:RDB快照、AOF日志
- 丰富的数据类型
- 速度
- 硬盘:寻址时间ms,带宽(吞吐)百兆~G/s(固态硬盘pci-e nvme)
- 内存:寻址时间ns,比硬盘快10w倍
- 文件
- 全量扫描(高IO),过大(T级)时,查询会变慢
- 数据库
- 对数据进行规划,分页存储
- 为1kb的数组建立索引,若将数组分成4bit的数据块,索引大小为1byte
- 索引大小可设置,窗口越小,索引越大
- 索引也是数据,存在磁盘中
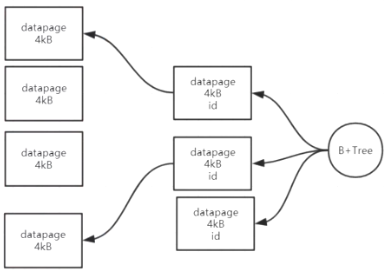
- B+树,树干在内存,索引磁盘
- datapage->索引->B+树
- 读取数据:先扫描B+树,读取相应索引到内存扫描,再读取相应datapage到内存扫描
- 表很大时,增删改(写)查(读)中,写操作会变慢
- 读操作单线程不受影响,但并发很大或查询复杂时会受影响(分布式、微服务解决并发问题)
- 把数据全部放到内存,且支持sql查询
- SAP HANA:关系型数据库(内存中运行),内存2T(erp+hana+2T服务器=¥2E)
- 数据在内存中比在硬盘中小:如有1000个user对象,住址字段是“Beijing”,JVM中只有一个“Beijing”字段,但序列化到磁盘后有1000个(内存指针实现了数据复用)
- 公司全部数据存在哪?
- 折中方案:将全量数据中频繁使用的数据放到内存中,其他放在硬盘数据库中
- 内存型数据库:redis、memcache
- 为什么是key-value型?内存中只有部分数据,无法按SQL的范式进行设计(空间换时间)
- 关系型数据库中的约束(范式)设计减少了数据冗余
- key-value的使用者只需关注每条记录自身,而不需查看其他记录
- worker 单线程,6.x io threads 多线程(多线程读取,单线程处理)
- Value类型:String、list、set、hash,每种类型有自己的本地方法
- 先用json把所有对象序列化为字符串,再存到memcache
事务
- 不是真正的事务,是一种模拟
- 本质:将一组操作放入队列中,一次执行(批处理)
- Oracle中事物的本质:将事务的DML操作写入日志

锁
- 执行事务操作时,如果监视的值发生了变化,则提交失败
- exec后,返回(nil),表示提交失败
消息
- 消息类型
- Queue:队列,点对点
- Topic:主题,广播 / 群发
- 常用消息系统
- Redis:只支持Topic
- Kafka:只支持Topic,需要Zookeeper支持
- JMS(Java Messaging Service):支持Queue和Topic
- Reids消息机制
- publish:发布消息
- subscribe:订阅消息
- psubscribe:使用通配符来订阅消息
持久化
- 本质上是一种备份和恢复
- RDB:默认
- 可看成一种快照,每隔一段时间将内存中数据保存到硬盘(dump.rdb)
- 配置参数:redis.conf
- 优点:恢复快
- 缺点:两次RDB之间,可能发生数据丢失
- AOF:记录日志(append only file)
- 配置参数
- appendonly yes
- bin/redis-server conf/redis.conf
- 日志重写
- 将过程日志改为最终状态记录(最终一致性),减小日志文件占用空间
- 使用压力测试模拟,模拟10万次操作,可观察到日志文件先变大后变小
- bin/redis-benchmark -n 100000

- 参数设置
- no-appendfsync-on-rewrite no :执行重写的时候,不写入新的日志
- auto-aof-rewrite-percentage 100 :当AOF文件比上次的大小超过了100%,执行重写
- auto-aof-rewrite-min-size 64mb :当AOF日志文件达到了64M,执行重写
- RDB和AOF同时存在时,优先读取AOF进行恢复(持久性保证更好)
主从复制
- 主从复制集群
- 作用
- 主从复制,主从备份,防止主节点宕机
- 任务分离,分摊主节点压力(如朋友圈读比写压力大很多)
- 读写分离,主节点写入,从节点读取
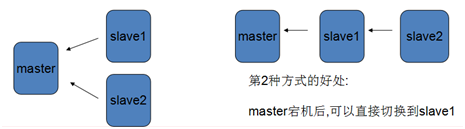
- 架构
- 星型模型:效率较高,HA复杂
- 线型模型:效率较低,HA简单
- 作用
- 分片
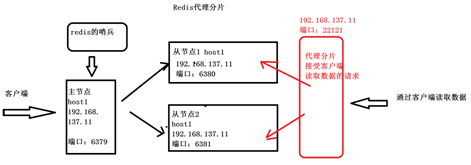
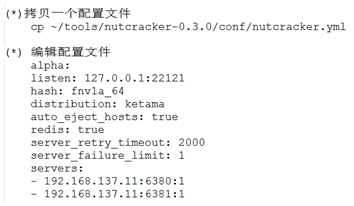
- 使用第三方软件Twemproxy实现负载均衡
- Twemproxy作为代理接收来自多个程序的访问,按照路由规则转发给Redis服务器再返回
- 配置
- 主节点
- 关闭RDB和AOF(任务分离)
- bind 0.0.0.0(允许所有网段IP连接)
- 查看主从关系:info replication
- 从节点
- replicaof localhost 6379
- 开启rdb和aof
- bin/redis-cli -p 6380
- 默认从节点只读
- 第一次同步RDB(较大),后面同步AOF
- 一次不要启动太多从节点
- 主节点

HA(哨兵)
- 2.4后开始有
- 配置文件:sentinel.conf
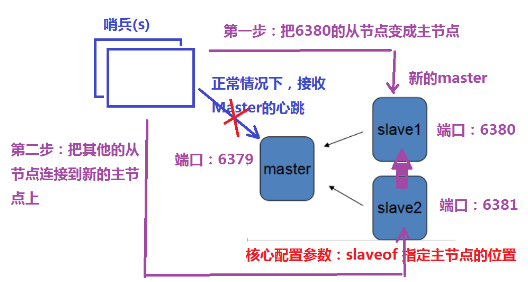


- +try-failover master mymaster 192.168.174.111 6379
- switch-master mymaster 192.168.174.111 6379 127.0.0.1 6381
- +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6381
原理
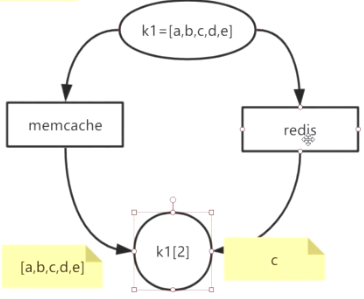
- memcache和redis:都是k-v,但redis的value有类型,以及基于类型的方法
- memcache的k,v都是string类型,数据向计算移动
- redis实现了计算向数据移动,减少IO量
安装
- 在Redis官网进入下载页面,复制下载链接
- 进入linux命令行,创建目录
- wget 下载链接
- tar xf 压缩包文件
- 进入redis目录
- vi READMI.md
- make:编译源码
- make PREFIX=安装路径 install:安装
- yum install gcc -y:安装gcc(如果没有的话)
- make distclean:清理
- vi ~/.bash_profile:添加环境变量
- REDIS_HOME=/root/training/redis-5.0.8
- export REDIS_HOME
- PATH=$REDIS_HOME/bin:$PATH
- export PATH
- source /etc/profile:环境变量生效
- cd utils
- sudo ./install_server.sh:开启服务,设置端口号,配置文件,日志文件,持久化目录
- service redis_6379 status:查看redis进程状态
- ps -fe | grep redis:查看所有redis进程状态
- 核心配置文件:redis.conf(从安装文件拷贝到安装目录)
- 设置后台运行:daemonize no

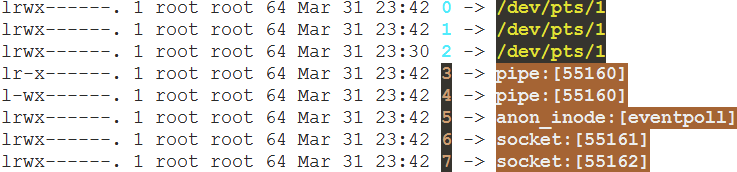
- strace -ff -o ~/stracedir/ooxx ./redis-server:追踪线程文件

- cd /proc/task/8625

- cd /proc/8625/fd
- redis-cli
- >bgsave:记录日志
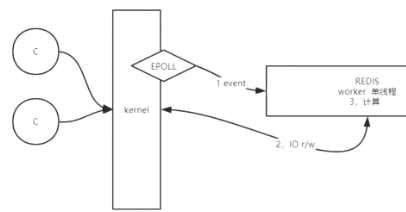
- 业务处理是单线程的
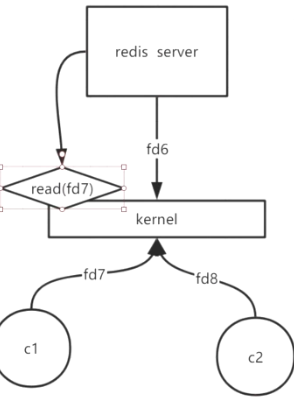
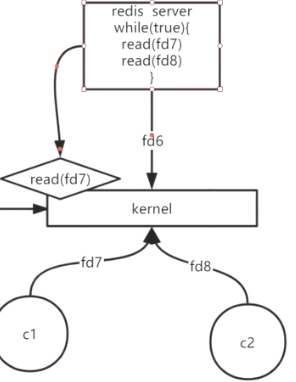
- 一个线程如何处理多个客户端请求
- BIO->NIO->epoll(多路复用)
- yum install man man-pages
- fcntl(可设置非阻塞)
- 用户很多时(如1000个),轮询的代价太大(用户态 / 内核态切换1000次)
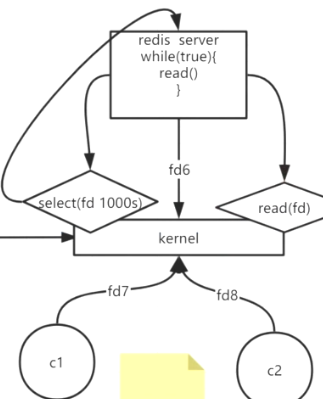
- select(多路复用,同步非阻塞,用户态 / 内核态切换1次,拷贝1000个fd到内核,内核遍历1000次,然后告诉redis需要读哪个用户)
- 缺点在于redis->kernel传参太多,且内核遍历次数太多
- 多路复用器:在内核中,如select、poll、epoll,告诉redis有没有数据到达,再由redis自己去读取
- 单线程不足:只能工作在一个CPU上,不能发挥硬件资源
- IO thread 事务性:保证一个client的一个connection中发送的指令是有顺序的
- 不需使用分布式锁/事务
- 类似:kafka k,v 消息构建
- 6.x之后,io threads多线程(io读写),无论哪个版本,工作线程就一个
BIO NIO select/poll

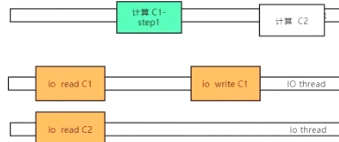
使用
- 方法一
- redis-cli
- 方法二
- nc localhost 6379
- 方法三
- exec 8<> /dev/tcp/localhost/6379
- echo -e 'keys *' >& 8
- cat <& 8
- 常用命令
- flushall:清除所有内容
- help @String:查看String的使用方法
- 5种value类型
- String
- 字符串
- strlen:字节个数
- 二进制安全:客户端根据自身编码方式发送byte数组
- hbase、zookeeper、kafka
- 数值
- incr
- decr
- 单线程原子
- 秒杀限流
- 二进制bitmap
- setbit k1 1 1
- 从左向右,自动扩容
- 场景1:统计用户任意时间窗口内登录几次(如一年内)
- setbit sean 3 1:sean在第4天登录了
- setbit sean 364 1:sean在第365天登录了
- bitcount sean 0 -1:统计一共登录了几次
- strlen sean:用了多大空间
- 场景2:统计一段时间内有多少人登录
- setbit 20200101 7 1
- setbit 20200101 3 1
- setbit 20200102 3 1
- bitop or res 20200101 20200102
- bitcount res 0 -1



- list
- 模拟栈、队列、数组
- 操作
- lpush k1 a b c d:左侧插入数据
- lrange k1 0 -1:查看范围内元素
- rpush k1 x y z:右侧插入数据
- ltrim k1 0 -1:删除区间之外的元素
- hash
- 场景:详情页 / 聚合,数据来自不同的库
- set
- 无序,去重
- 操作
- sadd k1 ooxx xxoo oxox ooxx:添加元素
- smembers k1:显示元素
- srandmember k1 3:不重复地取出3个元素
- srandmember k1 -8:可重复地取出8个元素
- sunion k1 k2:k1 k2 并集
- sinter k1 k2:k1 k2 交集
- sdiff k1 k2:
- 场景
- 随机事件:抽奖
- 集合运算:单线程串行,成本较大,通常会独立到一个redis实例
- sorted_set
- 有序,去重,动态维护顺序,底层是跳表(skiplist)
- 操作
- zadd k1 3.1 apple 2.5 orange 7 banana:插入数据
- zrange k1 0 -1 withscores:按分值排序
- zrange k1 0 1:取出前两名
- 场景
- 排行榜
- 动态翻页

参考
数据库知识网站
redis主从设置

 浙公网安备 33010602011771号
浙公网安备 33010602011771号