[DB] hadoop 集群安装
学习要点
- 体系架构、原理
- 多做练习、试验
装虚拟机
- 网络模式:仅主机模式
- software selection:development tools, GUI
- network & host name:host name,打开网卡开关,开机启动网卡,手动分配ip
- installation destination:磁盘大小
- kdump, security policy:关掉
- root:设置密码
- reboot
- 许可协议:接受(1->2->q->yes)
- 下一步,关掉没用的
- 随便起个用户名,不设置密码
远程登录
- putty / xshell
linux配置
- 关闭防火墙(永久)
- systemctl stop firewalld.service
- systemctl disable firewalld.service
- systemctl status firewalld.service:查看防火墙状态
- 设置主机名和ip对应关系
- vi /etc/hosts ip+主机名
- /tmp 目录
- 重启后删除数据
- HDFS默认的数据保存目录,需更改
文件目录
- 隐藏文件 /root/.bash_profile 存放环境变量
- 隐藏目录 /root/.ssh 配置免密码登录(Hadoop和Spark)
常用操作
- 查看后台进程
- ps -ef | grep redis-server:查看redis-server进程
- 杀死进程
- kill -9 进程号:强制杀死
- kill -3 进程号:Java进程,打印Java进程的Thread Dump
安装JDK
- 解压安装
- tar -zxvf jdk-8u144-linux-x64.tar.gz -C /root/training
- /root/training/jdk1.8.0_144
- 设置环境变量
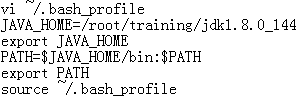
安装Hadoop
- 解压安装
- tar -zxvf hadoop-2.7.3.tar.gz -C ~/training/
- 安装tree命令
- rpm -ivh tree-1.6.0-10.el7.x86_64.rpm
- tree hadoop-2.7.3/ -d -L 3:查看hadoop的3层目录
- 设置环境变量


本地模式
- 没有HDFS,只能测试MapReduce程序(不是运行在Yarn中,作为独立Java程序运行)
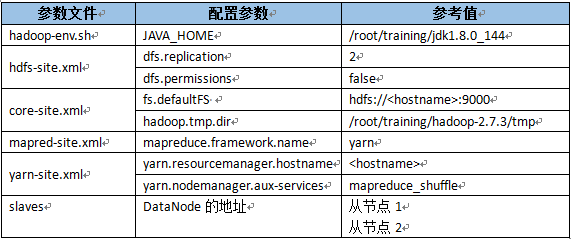
- 修改配置文件
- vi hadoop-env.sh
- export JAVA_HOME=/root/training/jdk1.8.0_144
- MapReduce例子
- cd ~/training/hadoop-2.7.3/share/hadoop/mapreduce/
- hadoop jar hadoop-mapreduce-examples-2.7.3.jar wowordcount /root/temp/input/data.txt /root/temp/output/wc
伪分布模式
- 单机模拟分布式环境,具备Hadoop所有功能
- HDFS:NameNode + DataNode + SecondaryNameNode
- Yarn:ResourceManager + NodeManager
- 修改配置文件
- hadoop-env.sh(同上)
- hdfs-site.xml


1 <property> 2 <name>dfs.replication</name> 3 <value>1</value> 4 </property> 5 <property> 6 <name>dfs.permission</name> 7 <value>false</value> 8 </property>
-
- core-site.xml
1 <property> 2 <name>fs.defaultFS</name> 3 <value>hdfs://bigdata111:9000</value> 4 </property> 5 <property> 6 <name>hadoop.tmp.dir</name> 7 <value>/root/training/hadoop-2.7.3/tmp</value> 8 </property>
- mapred-site.xml(mv mapred-site.xml.template mapred-site.xml)
1 <property> 2 <name>mapreduce.framework.name</name> 3 <value>yarn</value> 4 </property>
- yarn-site.xml
1 <property> 2 <name>yarn.resourcemanager.hostname</name> 3 <value>bigdata111</value> 4 </property> 5 <property> 6 <name>yarn.nodemanager.aux-services</name> 7 <value>mapreduce_shuffle</value> 8 </property>
- 对HDFS的NameNode进行格式化
- 创建 /root/training/hadoop-2.7.3/tmp
- hdfs namenode -format
- Storage directory /root/training/hadoop-2.7.3/tmp/dfs/name has been successfully formatted
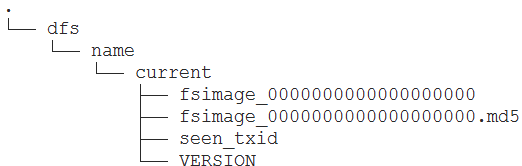

- 启动
- HDFS:start-dfs.sh
- Yarn:start-yarn.sh
- start-all.sh
- jps:查看进程
- 通过Web Console访问
- Yarn:8088
- hdfs:50070
- SSH免密码登录
- 对称加密:加密解密同ls .一个文件
- 不对称加密:加密解密两个文件(公钥私钥;谁登录谁生成)
- 配置
- ssh-keygen -t rsa:生成密钥对(RSA算法,一路回车)
![]()
-
-
- ssh-copy-id -i .ssh/id_rsa.pub root@bigdata111
-
![]()
-
- 认证:
- B随机产生一个字符串,用A的公钥加密后发回给A
- A收到B发来的字符串,用私钥解密后发回给B
- B对比两个字符串是否一样
- ssh bigdata111
- 认证:
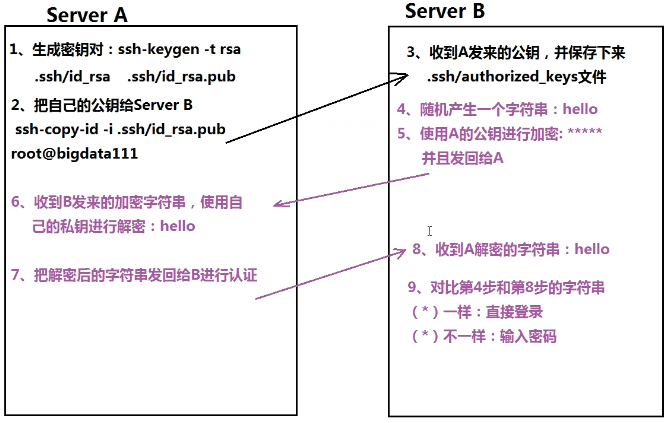
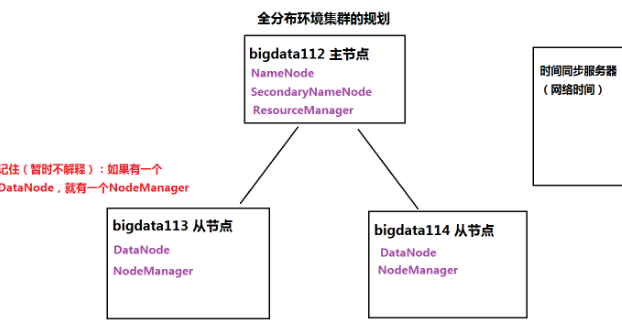
全分布模式
- 至少3台机器
- 主节点bigdata112,从节点bigdata113、bigdata114
- 安装Linux、JDK、关闭防火墙
- 配置免密码登录(两两之间)
- ssh-copy-id -i .ssh/id_rsa.pub root@bigdata112
- ssh-copy-id -i .ssh/id_rsa.pub root@bigdata113
- ssh-copy-id -i .ssh/id_rsa.pub root@bigdata114
- 保证集群时间同步(三台机器同时执行)
- date -s 2022-06-16
- 在主节点上安装hadoop,修改配置文件
- 格式化namenode
- hdfs namenode -format
- 将安装好的目录复制到从节点上
- scp -r hadoop-2.7.3/ root@bigdata113:/root/training
- scp -r hadoop-2.7.3/ root@bigdata114:/root/training
- 在主节点上启动集群,执行程序
HA模式
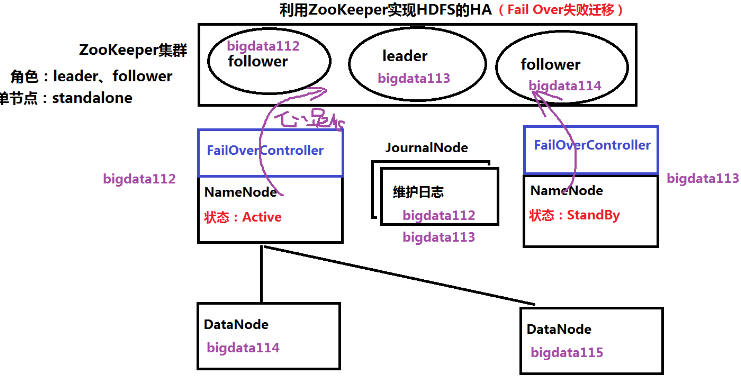
- 集群功能:Fail Over(失败迁移)、Load Balance(负载均衡)
- 实现失败迁移
- 两个NameNode,一个Active,一个StandBy
- 客户端连接ZK获取主节点信息
- NameNode通过FailOverController向ZK发送状态信息
- JournalNode(至少两个)管理NameNode的日志,通过日志恢复元信息
- 一个NameNode挂掉后,通过ZK进行切换
- 理论上需要9台机器:ZK(3)+JournalNode(2)+NameNode(2)+DataNode(2)
- 简化后需要4台
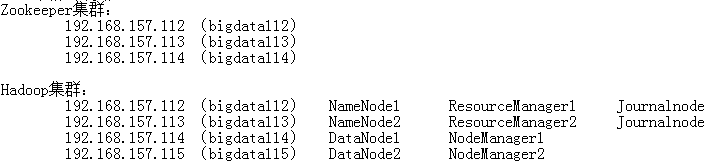
- 在bigdata112上安装ZK,配置好后复制到bigdata113、bigdata114
- 在bigdata112上安装hadoop,配置好后复制到bigdata113、bigdata114、bigdata115
- 在 hdfs-site.xml 中配置隔离机制,否则会导致脑裂
- 脑裂:HA环境中,同一时刻,HDFS中存在多个Active的NameNode,DataNode不知道听谁指挥
- 为何脑裂:网络问题,心跳信息没有成功发送到ZK,ZK切换NameNode
- 如何隔离:切换NameNode前,先Kill掉其他NameNode
- 在 hdfs-site.xml 中配置隔离机制,否则会导致脑裂
- 启动ZK集群
- 启动bigdata112、bigdata113 的 journalNode
- 在bigdata112上格式化HDFS
- hdfs namenode -format
- 将/root/training/hadoop-2.7.3/tmp拷贝到bigdata113的/root/training/hadoop-2.7.3/tmp下(保证两个NameNode维护信息一致)
- hdfs zkfc -formatZK
- 在bigdata112上启动Hadoop集群(bigdata113上的ResourceManager需要单独启动)

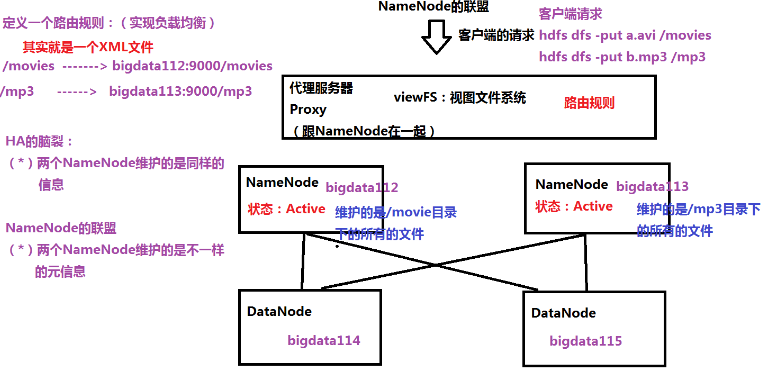
HDFS联盟
- 实现负载均衡
- 分摊客户端压力
- 缓存更多元信息
- 两个NameNode都是Active
- 两个NameNode维护的是不一样的元信息
- 每个DataNode向不同的NameNode注册
- 通过集群前端的代理服务器根据路由规则转发客户端请求
- 代理服务器和NameNode在一起
- 搭建
- 集群规划
- NameNode:bigdata112 bigdata113
- DataNode:bigdata114 bigdata115
- 在bigdata112上安装hadoop
- 配置路由规则(viewFS),修改core-site.xml文件
- 复制到bigdata113、bigdata114、bigdata115
- 在NameNode(bigdata112、bigdata113)上格式化
- 根据路由规则,在每个NameNode上创建目录
- 操作HDFS
- 看到的是viewFS定义的路由规则
- 集群规划
集群脚本
- 配置文件
deploy.conf
1 #集群角色规划 2 node01,master,all,hadoop,hive 3 node02,slave,all,hadoop,hive 4 node03,slave,all,hadoop,hive
- 集群分发脚本
- 授权脚本:chmod u+x runRemoteCmd.sh
deploy.sh
1 #!/bin/bash 2 if [ $# -lt 3 ] 3 then 4 echo "Usage:./deploy.sh srcFile(or Dir) descFile(or Dir) MachineTag" 5 echo "Usage:./deploy.sh srcFile(or Dir) descFile(or Dir) MachineTag confFile" 6 exit 7 fi 8 9 src=$1 10 dest=$2 11 tag=$3 12 13 if [ 'b'$4'b' == 'bb' ] 14 then 15 confFile=/root/tools/deploy.conf 16 else 17 confFile=$4 18 fi 19 if [ -f $confFile ] 20 then 21 if [ -f $src ] 22 then 23 for server in `cat $confFile | grep -v '^#' | grep ','$tag',' | awk -F',' '{print $1}'` 24 do 25 scp $src $server":"$dest 26 done 27 elif [ -d $src ] 28 then 29 for server in `cat $confFile | grep -v '^#' | grep ','$tag',' | awk -F',' '{print $1}'` 30 do 31 scp -r $src $server":"$dest 32 done 33 else 34 echo "Error:No source file exist" 35 fi 36 else 37 echo "Error:Please assign config file" 38 fi
- 命令同步脚本
runRemoteCmd.sh
1 #!/bin/bash 2 if [ $# -lt 2 ] 3 then 4 echo "Usage:./runRemoteCmd.sh Command MachineTag" 5 echo "Usage:./runRemoteCmd.sh Command MachineTag confFile" 6 exit 7 fi 8 9 cmd=$1 10 tag=$2 11 12 if [ 'b'$3'b' == 'bb' ] 13 then 14 confFile=/root/tools/deploy.conf 15 else 16 confFile=$3 17 fi 18 if [ -f $confFile ] 19 then 20 for server in `cat $confFile | grep -v '^#' | grep ','$tag',' | awk -F',' '{print $1}'` 21 do 22 echo "*************$server***************" 23 ssh $server "source /etc/profile; $cmd" 24 done 25 else 26 echo "Error:Please assign config file" 27 fi

- 安装jdk
- 创建软连接(快捷方式):ln -s jdk1.8.0_51 jdk
- 环境变量
- .bashrc:用户级
- /etc/profile:全局
时间同步
- CentOS7用ntpdate
- CentOS8用chrony
- 查看版本:cat /etc/*release
参考
厦大公开课
https://dblab.xmu.edu.cn/post/8197/
集群脚本课程
https://edu.csdn.net/course/play/11032/239269
linux shell 参数传递
https://www.runoob.com/linux/linux-shell-passing-arguments.html
chrony服务安装与配置
https://baijiahao.baidu.com/s?id=1655260653687604326&wfr=spider&for=pc
修改阿里云id
https://blog.csdn.net/dianyeyu0359/article/details/102335754
linux空格问题
https://blog.csdn.net/dreamerway/article/details/20449381
kafka自动化脚本部署
https://blog.csdn.net/sinat_32176947/article/details/79690653
大数据环境安装
https://www.jianshu.com/p/a4a0e7e4e4b7

 浙公网安备 33010602011771号
浙公网安备 33010602011771号