【机器学习】作业7: 随机森林
标签(空格分隔): 机器学习
星期二 BlackJack,机器学习
星期三 算法
星期四 RPC,机器学习
星期五 数值
这周好爆炸
(随便吐槽吐槽)
鉴于决策树容易过拟合的缺点,随机森林采用多个决策树的投票机制来改善决策树,我们假设随机森林使用了m棵决策树,那么就需要产生m个一定数量的样本集来训练每一棵树,如果用全样本去训练m棵决策树显然是不可取的,全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的
产生n个样本的方法采用Bootstraping法,这是一种有放回的抽样方法,产生n个样本
而最终结果采用Bagging的策略来获得,即多数投票机制
随机森林的生成方法:
1. 从样本集中通过重采样的方式产生n个样本
2. 假设样本特征数目为a,对n个样本选择a中的k个特征,用建立决策树的方式获得最佳分割点
3. 重复m次,产生m棵决策树
4. 多数投票机制来进行预测
随机森林的思想非常简单,使用很多颗决策树来做预测,然后投票,取票数最多的结果作为输出
那个,看见彭先生和华主席都调库调了决策树,然后自己实现森林。。
这个,API调用小练习嘛,决策树很难写,决策树之后的逻辑很简单
既然都有库,而且就算自己写,决策树自己写我认输,决策树之后就是for循环小练习,我决定不再重复造轮子(偷懒)
突然想起,随机森林应该是我非常熟悉的一个算法,这学期开始数学建模比赛用过,上学期数据挖掘课上也用过。
既然如此,我就不再找其他数据了,再跑一遍交吧= =
栗子
手写数字识别


当时使用了kNN, SVC, DT, GaussianNB, MultinomialNB, BernoulliNB 几种算法
仿照课件代码,自己手动实现kNN算法
myKNN.py
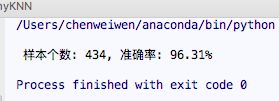
调用sklearn中的各种算法,如下
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import BernoulliNB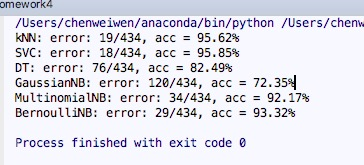
当我们把算法换成随机森林之后
clf = RandomForestClassifier(n_estimators = = 100, max_depth =None ,
min_samples_split = = 2, random_state = = 0,max_features = = 21)准确率达到了 98%
随手打开两个识别错的文件


这个数字写的,真是抽象

代码
前期实验
def handwritingClassTest():
trainingMat, hwLabels = load_trainingData()
testMat, goldLabels = load_testData()
mTest = len(testMat)
# get algorithm from skLearn
ensemble = ['kNN', 'SVC', 'DT', 'GaussianNB','MultinomialNB', 'BernoulliNB','RFC']
for a in ensemble:
print a + ':',
if a == 'kNN': clf = KNeighborsClassifier(algorithm='kd_tree',n_neighbors=5)
if a == 'SVC': clf = SVC(C=0.01, kernel='linear')
if a == 'DT': clf = DecisionTreeClassifier(criterion='entropy', random_state=0)
if a == 'GaussianNB': clf = GaussianNB()
if a == 'MultinomialNB': clf = MultinomialNB()
if a == 'BernoulliNB': clf = BernoulliNB()
if a == 'RFC': clf = RandomForestClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0, max_features=21)
clf.fit(trainingMat, hwLabels)
classifierResult = clf.predict(testMat)
err_cnt = 0.0
for i in range(mTest):
if (classifierResult[i]) != goldLabels[i]:
err_cnt += 1.0
acc = 1 - (err_cnt/float(mTest))
st = 'error: %d/%d, acc = %2.2f%%' % (err_cnt,mTest,acc*100)
print st
最终提交版本随机森林
# -*-coding:utf-8-*-]
from numpy import *
from os import listdir
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
def img2vect(filename):
res = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
res[0,32*i + j] = int(lineStr[j])
return res
def load_trainingData():
hwLabels = []
trainingFileList = listdir('data/trainingDigits/')
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0]
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vect('data/trainingDigits/%s' % fileNameStr)
return trainingMat, hwLabels
def load_testData():
testFileList = listdir('data/testDigits7')
print testFileList
goldLabels = []
mTest = len(testFileList)
testMat = zeros((mTest,1024))
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0]
# classNumStr = int(fileStr.split('_')[0])
testMat[i,:] = img2vect('data/testDigits7/%s' % fileNameStr)
goldLabels.append(fileStr)
return testMat, goldLabels
def handwritingClass():
trainingMat, hwLabels = load_trainingData()
testMat, goldLabels = load_testData()
mTest = len(testMat)
# clf = KNeighborsClassifier(algorithm='kd_tree', n_neighbors=5)
clf = RandomForestClassifier(n_estimators=100, max_depth=None, min_samples_split=2, random_state=0,max_features=21)
clf.fit(trainingMat, hwLabels)
classifierResult = clf.predict(testMat)
out_file = open('out.txt','w')
for i in range(mTest):
st = '%s\t%d\n' % (goldLabels[i], classifierResult[i])
out_file.write(st)
if __name__ == '__main__':
handwritingClass()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号