【分布式系统】HBase实验
标签(空格分隔): 分布式系统
![]()
华东师范大学 计算机科学与软件工程学院



一、前言
在实现过程中,我们实现了windows环境下的伪分布式的环境搭建以及分布在三台腾讯云服务器下的完全分布式。并使用JAVA成功连接,将Adult(大约3W条数据)成功插入了伪分布式hbase以及完全分布式的hbase。
完全分布式结果可以在118.25.18.17:16010查看
二、伪分布式
1. 环境搭建
o 下载各种文件
下载Hadoop-2.9.0、Hadoop-common-2.2.0、Hbase-1.2.6。JDK使用电脑中本身安装的JDK-1.8.0_111。
Hadoop下载地址
Hadoop-common下载地址
Hbase下载地址
o 环境配置
为了方便配置,又加上Hadoop无法识别带空格的路径,将下载好的 3个压缩包分别解压到OpenSource文件夹,并且将安装在D:\Program Files\Java中的JDK文件夹拷贝一份到OpenSource中用于后续配置。
o 覆盖文件
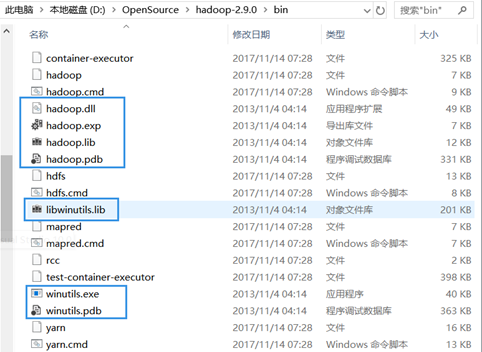
打开目录D:\OpenSource\hadoop-common-2.2.0-bin-master\bin复制被蓝框框出的7个文件且只复制这7个文件。
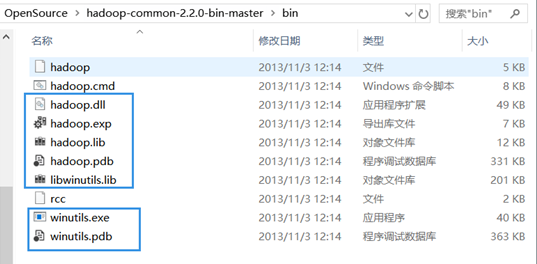
打开目录D:\OpenSource\hadoop-2.7.2\bin粘贴刚复制的7个文件
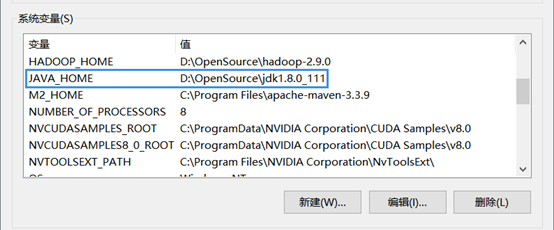
o 安装JDK并配置环境
JAVA_HOME环境变量
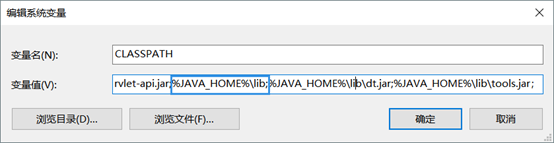
CLASSPATH环境变量
Path环境变量
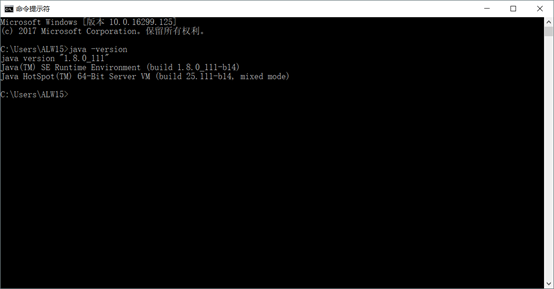
检测是否成功:令行输入java -version,返回如果成功,”java version “1.8.0_92”“即成功
o 配置Hadoop
如图找到hadoop-env.cmd
在末尾添上

在 core-site.xml 文件末尾添上

在 hdfs-site.xml 文件末尾添上

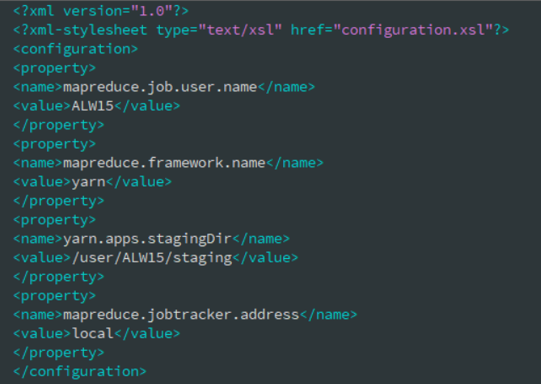
新建 mapred-site.xml 文件
o 启动 Hadoop
以管理员身份运行 CMD 命令提示符
切换到 hadoop 目录 :D:\OpenSource\hadoop-2.9.0\etc\hadoop
运行 hadoop-env.cmd 脚本
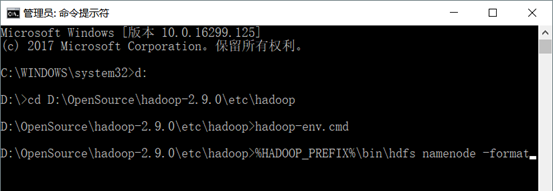
格式化 HDFS 文件系统 :运行%HADOOP_PREFIX%\bin\hdfs namenode -format 指令(之前已经运行过该指令,不重复格式化)
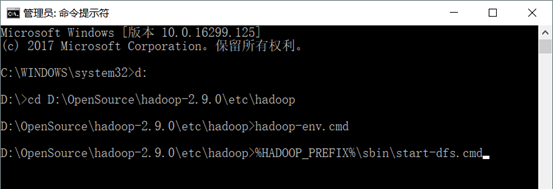
启动 HDFS :运行%HADOOP_PREFIX%\sbin\start-dfs.cmd 指令
停止 Hadoop :运行%HADOOP_PREFIX%\sbin\stop-all.cmd指令
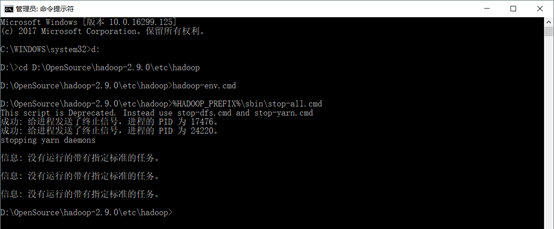
o 配置 Hbase
编辑 hbase-site.xml
编辑 hbase-env.cmd

o 启动 Hbase
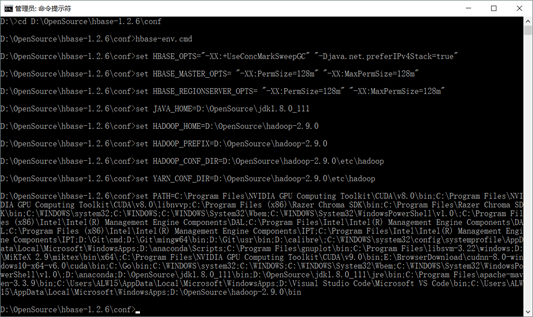
首先保证 hadoop 是启动的状态 以管理员方式启动 CMD 命令提示符 进入 D:\OpenSource\hbase-1.1.5\conf目录 首先执行 hbase-env.cmd
然后进入 bin 目录
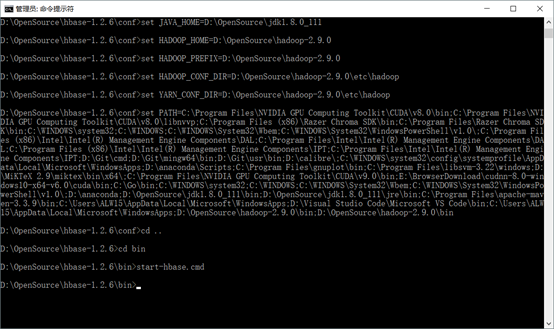
执行 start-hbase.cmd,启动成功会开启 hbase 的窗口
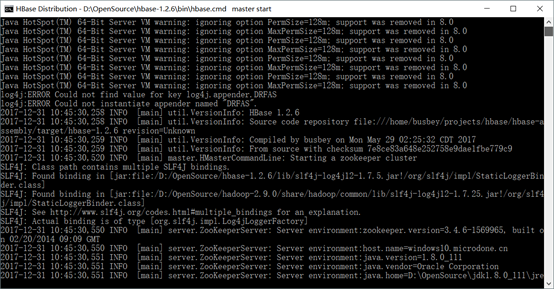
2. 测试结果
o Hbase Shell
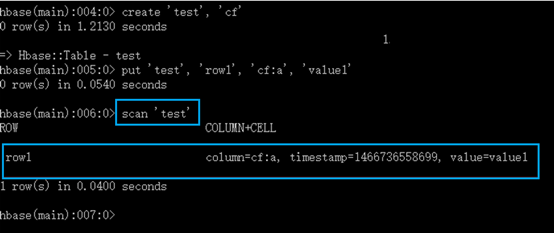
用 shell 连接 HBase

Scan 表
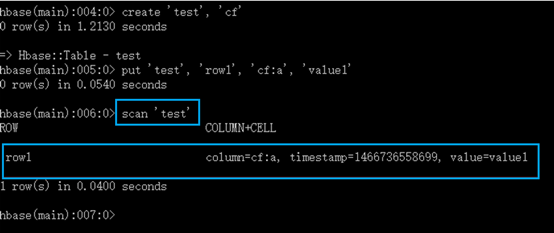
Get 一行
删除表
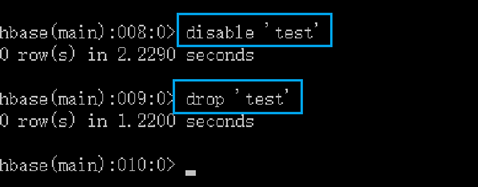
关闭 shell

停止 Hbase

o 用java API访问
三、完全分布式
这里的顺序与上一章不同,先写的配好环境后的一通操作,然后才写艰难的配环境过程,真实分布式的环境花费了至少40个小时 
1. 一通操作
JAVA将Adult数据插入hbase数据库中
o 配置Configuration
System.setProperty("hadoop.home.dir", "D:/OpenSource/hadoop-2.9.0");static Configuation configuration = HBaseConfiguration.create();o 主函数
public static void main(String[] args) throws Exception {
String tableName = "Iris";
System.setProperty("hadoop.home.dir", "D:/OpenSource/hadoop-2.9.0");
String columns[] ={"Sepal.Length","Sepal.Width","Petal.Length","Petal.Width","type"};
createTable(tableName,columns);
ArrayList<String[]> list = ProcessIrisData();
for(int i=0;i<list.size();i++)
{
insertData(tableName,columns,list.get(i));
}
// QueryAll(tableName);
// QueryByRowKey(tableName,"3");
QueryByColumnKey(tableName,"Sepal.Length","5.7");
}设置表的名字为Adult,将列属性设置完毕之后,就可以创建表
然后从文件中将Adult的数据加载到ArrayList中,就可以进行插入操作
o 加载数据函数
public static ArrayList<String[]> ProcessAdultData(){
ArrayList<String[]> resultList = new ArrayList<>();
FileReader fr;
BufferedReader br;
try{
fr = new FileReader("./src/Adult.data");
br = new BufferedReader(fr);
String line;
while((line = br.readLine()) != null){
String[] dataLine = line.split(",");
resultList.add(dataLine);
}
}
catch (FileNotFoundException e){
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return resultList;
}很简单的操作,将数据按列读入,按”,”分割,然后将String[]加入list中
o 建表函数
public static void createTable(String tableName,String[] columns) {
System.out.println("start create table ......");
try {
HBaseAdmin hBaseAdmin = new HBaseAdmin(configuration);
if (hBaseAdmin.tableExists(tableName)) {// 如果存在要创建的表,那么先删除,再创建
hBaseAdmin.disableTable(tableName);
hBaseAdmin.deleteTable(tableName);
System.out.println(tableName + " is exist,detele....");
}
HTableDescriptor tableDescriptor = new HTableDescriptor(tableName);
for (String column:columns){
tableDescriptor.addFamily(new HColumnDescriptor(column));
}
hBaseAdmin.createTable(tableDescriptor);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("end create table ......");
}先检测该表是否存在,如果存在的话disable之后drop,然后再重新create
然后在数据逻辑模型HTableDescriptor中一项一项加入列属性名,就可以创建啦
o 添加数据函数
public static void insertData(String tableName,String[] columns,String[] values) throws Exception{
HTable table = new HTable(configuration,tableName);
Put put = new Put(String.valueOf(++index).getBytes());// 一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
for(int i=0;i<columns.length;i++)
put.add(columns[i].getBytes(), null, values[i].getBytes());// 本行数据的第一列
try {
table.put(put);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("end insert data ......" +index);
}首先得到要处理的数据库
然后开始生成PUT
一个PUT代表一行数据,再NEW一个PUT表示第二行数据,每行一个唯一的ROWKEY,此处rowkey为put构造方法中传入的值
我的rowkey选取的是数字1 –> 数据条数
然后将一条中的每个属性对应的value设置好就可以开始插入了
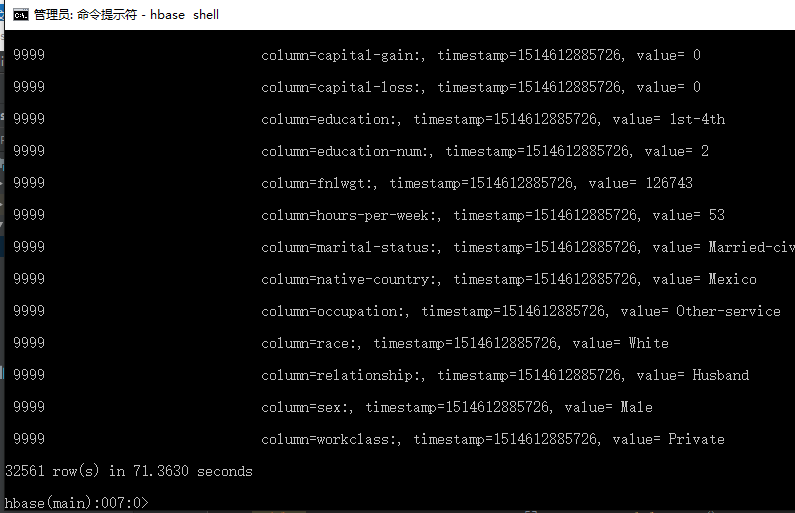
o 结果
hbase shell 输入 scan 'Adult'结果
o 查询所有表内数据函数(以iris为例子)
public static void QueryAll(String tableName) throws Exception{
HTable table = new HTable(configuration, tableName);
try {
ResultScanner rs = table.getScanner(new Scan());
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ "====值:" + new String(keyValue.getValue()));
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
o 删除表函数
public static void dropTable(String tableName) {
try {
HBaseAdmin admin = new HBaseAdmin(configuration);
admin.disableTable(tableName);
admin.deleteTable(tableName);
} catch (MasterNotRunningException e) {
e.printStackTrace();
} catch (ZooKeeperConnectionException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}o 按照rowkey删除表中一行函数
public static void deleteRow(String tablename, String rowkey) {
try {
HTable table = new HTable(configuration, tablename);
List list = new ArrayList();
Delete d1 = new Delete(rowkey.getBytes());
list.add(d1);
table.delete(list);
System.out.println("删除行成功!");
} catch (IOException e) {
e.printStackTrace();
}
}o 按照rowkey搜索
public static void QueryByRowKey(String tableName,String rowkey) throws Exception{
HTable table = new HTable(configuration, tableName);
try {
Get scan = new Get(rowkey.getBytes());// 根据rowkey查询
Result r = table.get(scan);
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ "====值:" + new String(keyValue.getValue()));
}
} catch (IOException e) {
e.printStackTrace();
}
}o 按照colum的key搜索
public static void QueryByColumnKey(String tableName,String column,String key) {
try {
HTable table = new HTable(configuration, tableName);
Filter filter = new SingleColumnValueFilter(Bytes
.toBytes(column), null, CompareFilter.CompareOp.EQUAL, Bytes
.toBytes(key)); // 当列column1的值为aaa时进行查询
Scan s = new Scan();
s.setFilter(filter);
ResultScanner rs = table.getScanner(s);
for (Result r : rs) {
System.out.println("获得到rowkey:" + new String(r.getRow()));
for (KeyValue keyValue : r.raw()) {
System.out.println("列:" + new String(keyValue.getFamily())
+ "====值:" + new String(keyValue.getValue()));
}
}
} catch (Exception e) {
e.printStackTrace();
}
}结果
2. 完全分布式的配置
要完成完全分布式的前提是拥有多台服务器,当然我们可以在本机上搭建三个centos系统,但是这会对本地的内存和磁盘压力过大,于是我们组三人购买了三个腾讯云上的云服务器(centOs7.3)。
master:118.25.18.17

node1: 118.25.22.142

node2: 182.254.140.65

理论上只要在三台机子上都搭建好Java,hadoop和hbase的环境,然后由master节点发起start-all.sh(启动hadoop并拉动node一起启动),发去start-hbase.sh(启动hbase并拉动node一起启动),就能实现完全分布式的状态,并使hbase shell之后实现hbase在多台服务器的运行状况。
然而配完全分布式环境时又遇到了很多问题。
o 用户组问题
当所有用户都用root时,会有安全性问题,于是我在三个云服务器上都新建了hadoop这个用户组,创建新的用户使用hadoop主要是考虑到安全因素,一般配置的时候都是在root下配置的,使用的时候创建新用户使用hadoop,当然你可以用root启动和使用hadoop,但是root权限太大,可能因为某个误操作导致灾难性的后果,所以需要创建新的用户。
o 下载问题
最简单的下载方法是用yum直接install需要的包,比如yum install java1.8* ,但是yum下载的包路径固定且难找,此处推荐使用ftp从本地上传。
o 配置文件
环境变量肯定是重中之重,需要在.bashrc中配好JAVA_HOME,HADOOP_HOME, 并把二者的bin , sbin(如果有)加入到PATH中,方便运行。
然后还有配每台服务器的名字,以及host文件,根据一开始分配的任务分别把三台服务器设置成master, node1, node2, 设置完之后重启生效
然后在三台服务器上都要配置好host文件,但是三者的host是不一样的(巨坑),对于本机而言,应该输入内网ip
比如master机

o ssh免密传输
通过ssh-keygen -t rsa生成密钥并将id_rsa_pub内容写入生成authorized_keys文件,将authorized_keys传输到另两台主机下进行覆盖
o 快速配置
hbase和hadoop的配置和上面伪分布式类似,只是需要更多的编辑步骤,在此不提。
在此处之前master和两个节点除了host和hostname文件以外基本一致,所以我们可以通过镜像文件的方式,现在master端搭好,分享给两个node,此处使用腾讯云的共享云镜像

o 格式化 HDFS 文件系统
bin\hdfs namenode -format但是此处会有大坑:
由于配置时有多次的误操作,我格式化了多次文件系统,而此处只格式化master节点的文件系统,对node没有影响,会导致master和node的clusterId不匹配,导致没法拉起子节点,次问题解决方案稍后提。
o 内存问题
由于买的时10元1GB的廉价机,在装了hbase和hadoop并运行后,内存吃紧
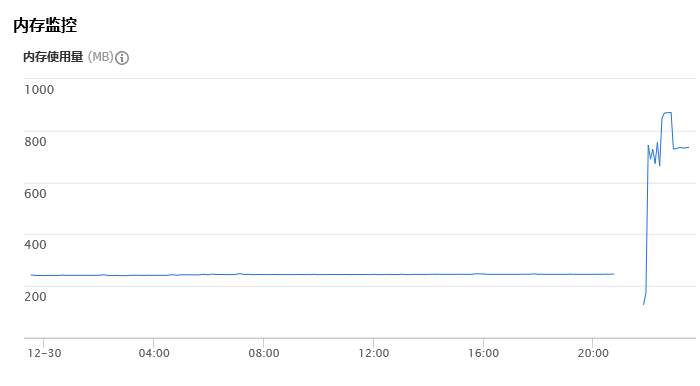
可以发现当运行hbase和hadoop之后,内存利用率飙升至80%以上
OK配置基本完成之后我们就可以跑啦
先执行 start-all.sh启动关于hadoop的master的manager以及namenode,同时会拉动子节点的datanode
在50070端口可以查询到相关信息
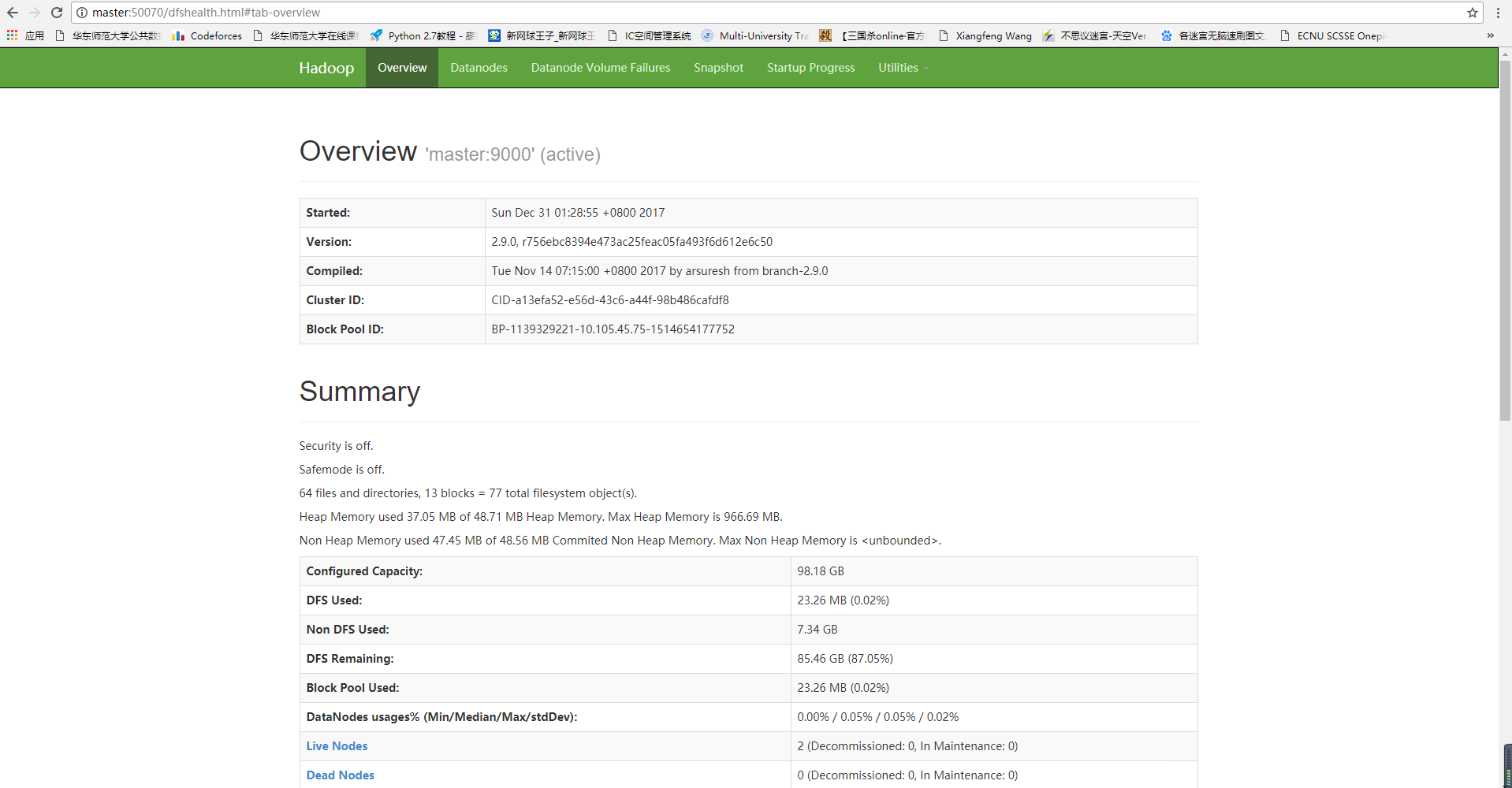
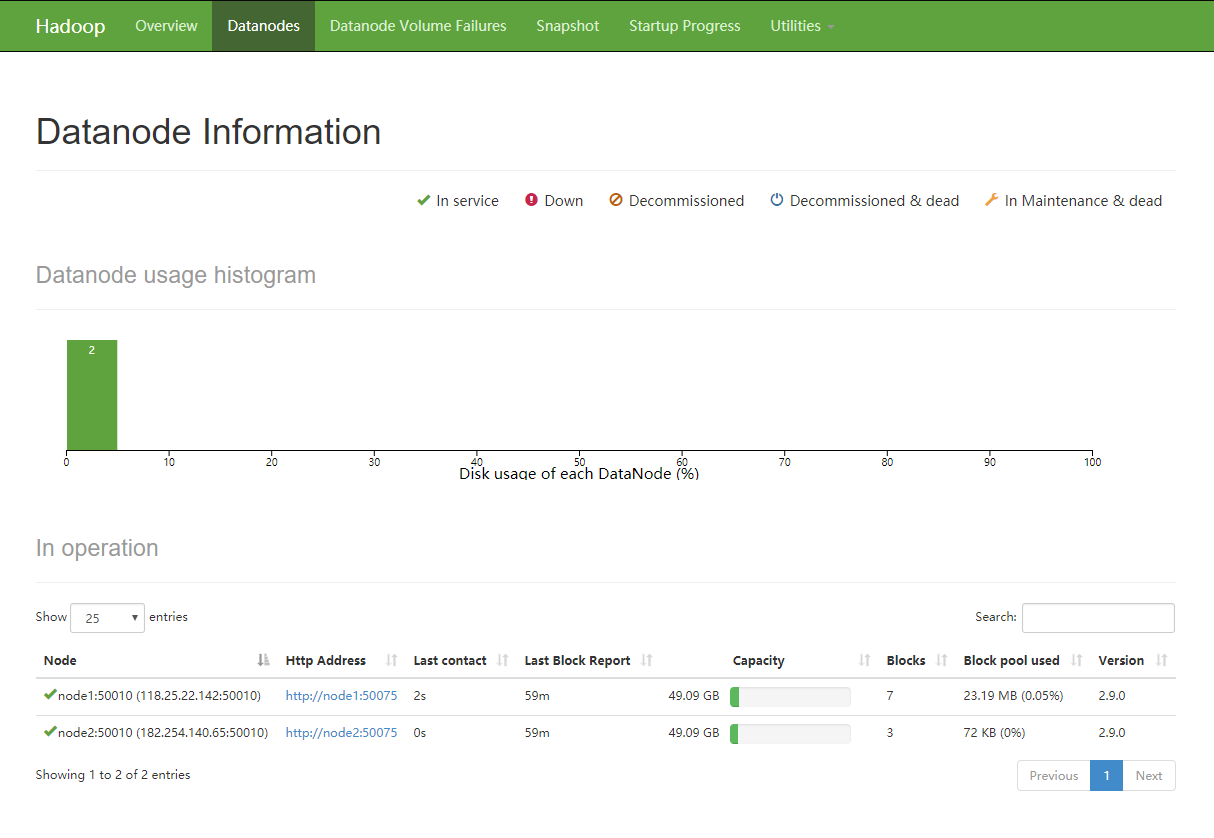
欢迎访问 118.25.18.17:50070 查看我们服务器上hadoop运行情况
然后执行start-hbase.sh启动关于hbase的进程,hbase的运行情况可以在16010端口查看
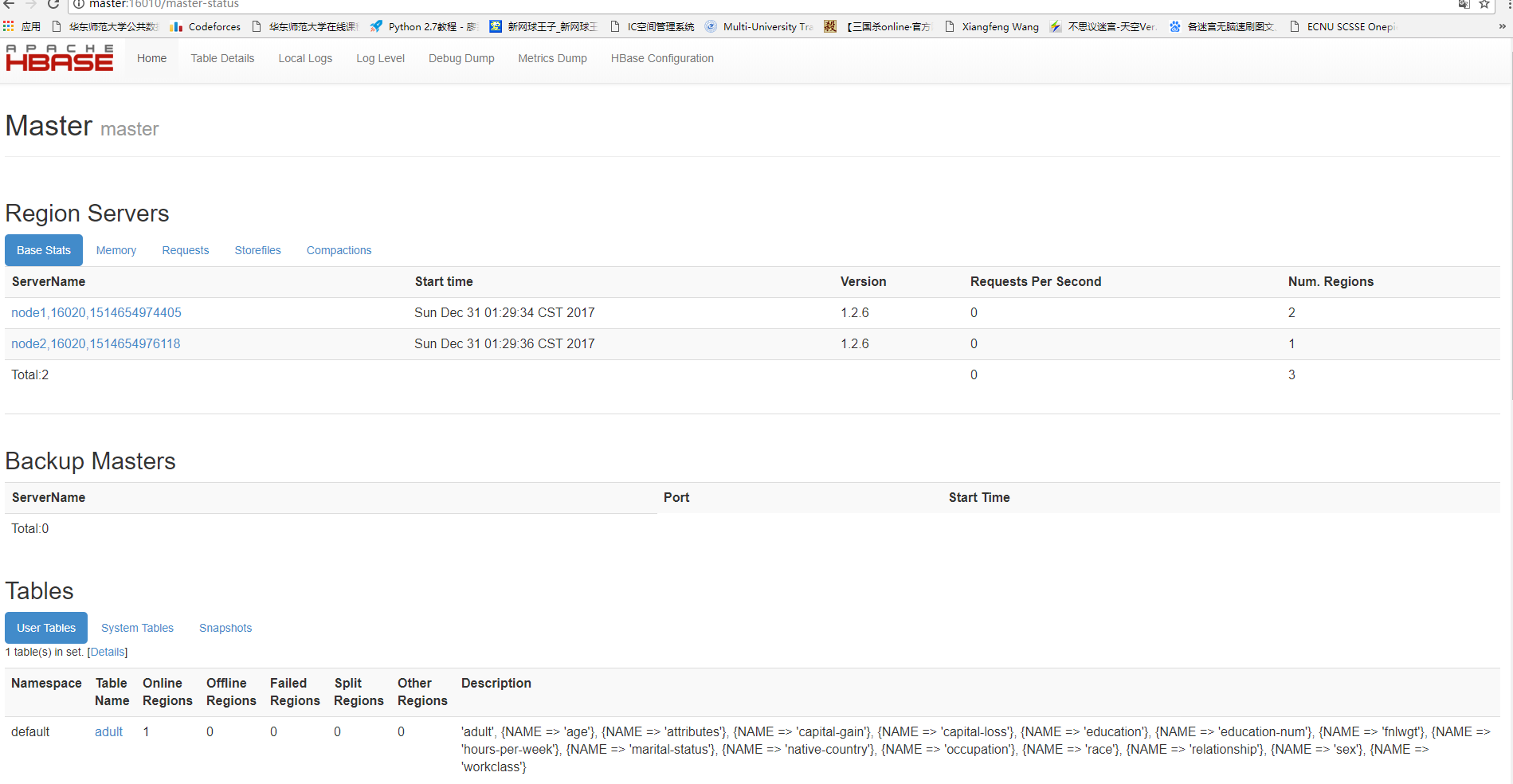
欢迎访问 118.25.18.17:16010 查看我们服务器上hadoop运行情况
hbase现在只有一个adult表,是我用java远程插入的后文再说
此时jps之后可以发现 master和node节点如下
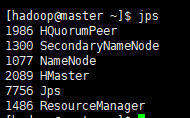
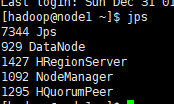
ok成功跑起来啦,我们可以用hbase shell拉动shell进程
写一些简单的sql语句
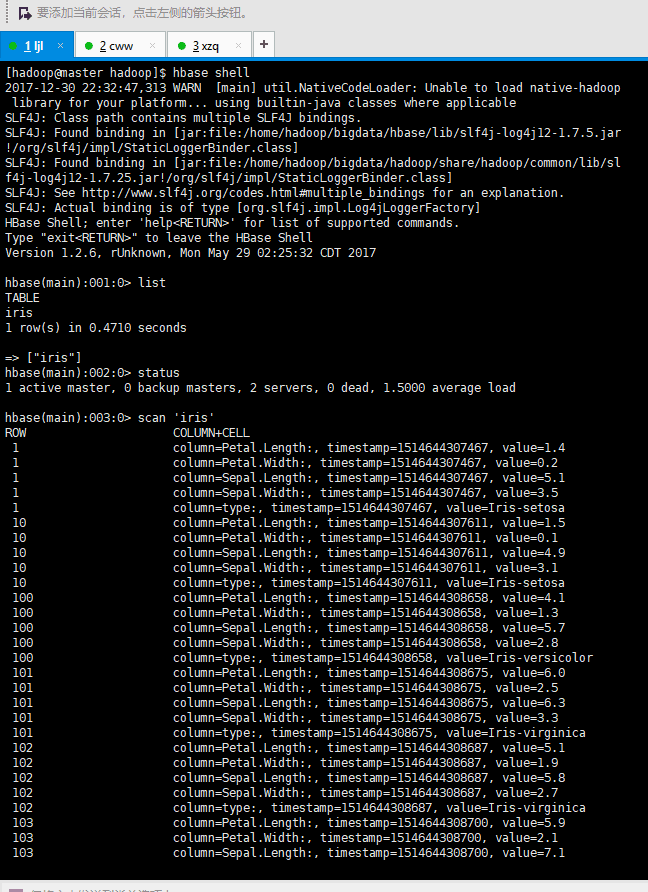
当然iris数据时提前注入的
然后就是对远程java代码的修改
由于是windows端的java控制,首先要改变windows的host文件
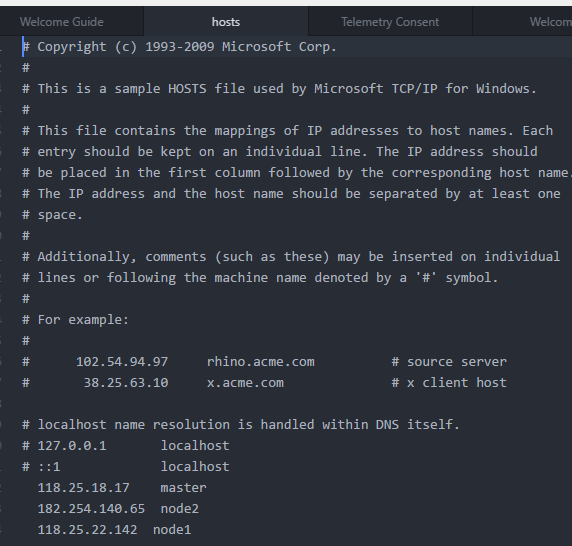
成功的结果以在chorm内输入master:16010能弹出网站为成功标志
然后是要将服务器上的数据库文件导入java代码中
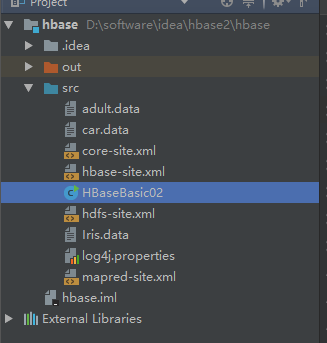
我这里配置了四个xml(三个hadoop、一个hbase),然后随便扔了几个数据集,然后在代码中
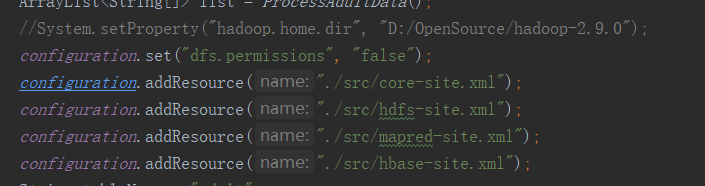
将原来的对伪分布式处理的环境变量注释,并加载所有的xml文件
通过这样的操作就能远程处理云服务器
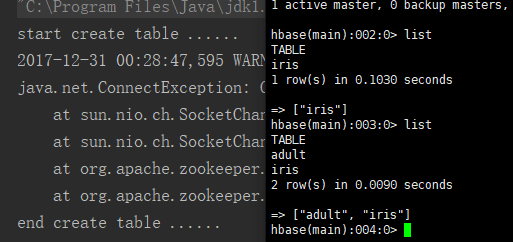
然后我尝试将大数据往远程服务器的分布式数据库中插
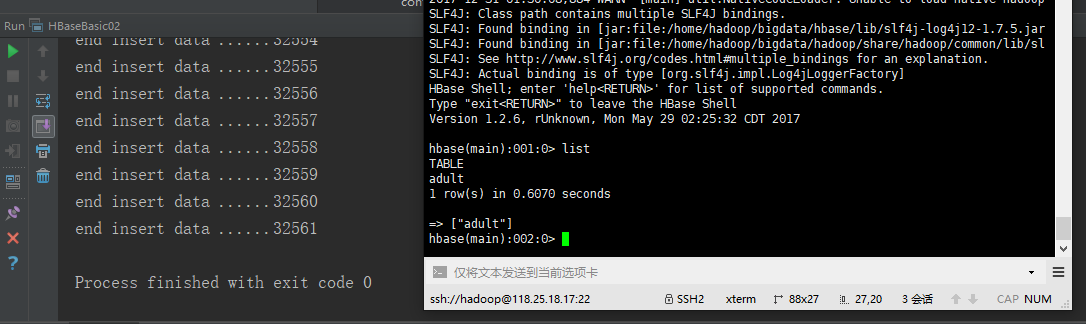
发现可能是由于网络原因以及,master和其node不是在一个内网的原因,速度很慢,几乎是在本地运行的100倍,好在还是将3W条17个属性的数据插完了
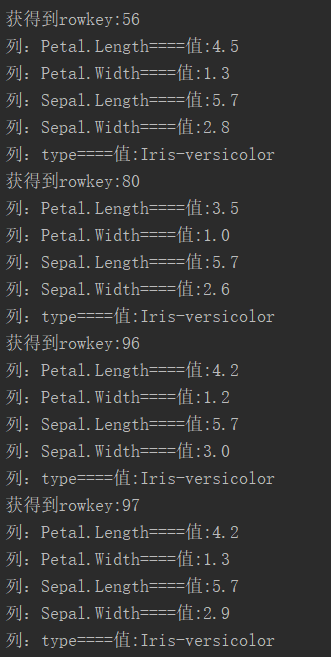
在apache hbase的16010端口查看时,可以看到数据库的一小部分
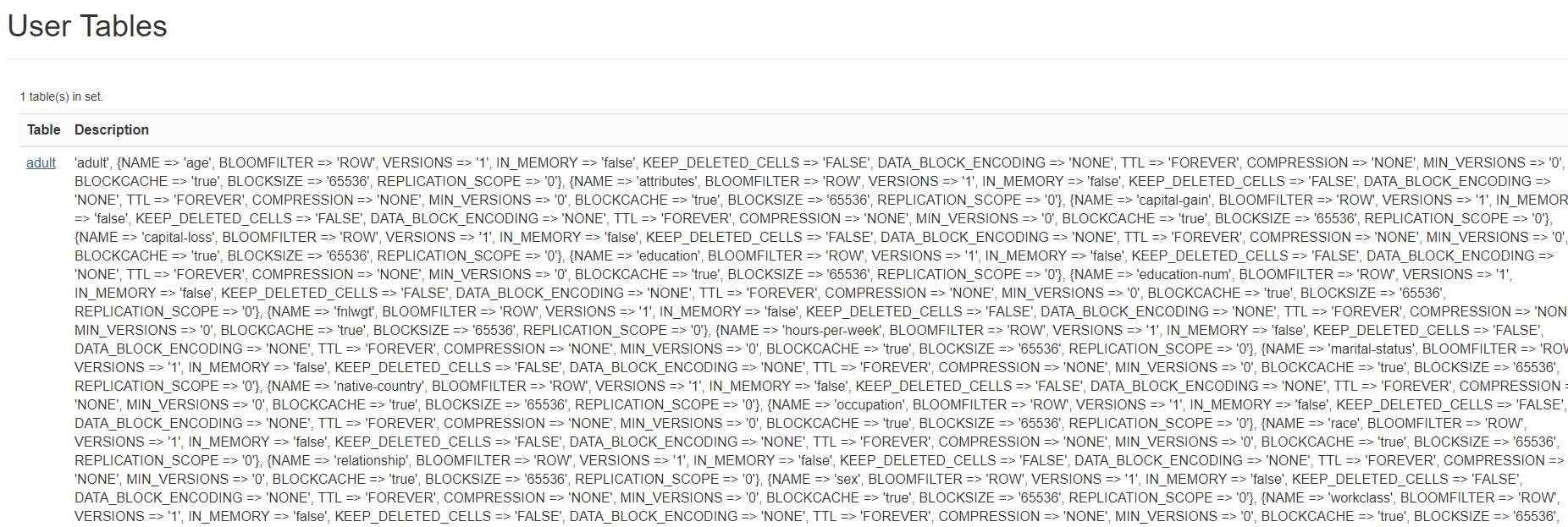
ok 基本撒花
对 clusterID 不一致的解决方法
将 master 中 name/current 下的 VERSION 中的 clusterID 复制到 data/current 下的 VERSION 中,覆盖掉原来的 clusterID 重新启动即可
没有什么问题是stop,start,stop,start几次解决不了的
如果有 就reboot, 如果还有 就拿镜像重装 
——来自重装至少30次系统的人的心声
四、总结
我爱hbase
Hbase是一个分布式的和可扩展的大数据仓库,能够利用HDFS的分布式处理模式,并从Hadoop的MapReduce程序模型中获益。在实验过程中,由于master和两个node不是一个内网的缘故,以及操作的windows服务端的带宽不佳,导致了数据的插入速率比伪分布式更差。但是我们没有
如果心情好的话,我就 我就 我就继续睡觉
我再也不写hbase了! 再也不装系统了!
凌晨四点 离2018还有20个小时啊 晚安
 ->
-> 
跨年回来在补两句,新年快乐,GPA++

 浙公网安备 33010602011771号
浙公网安备 33010602011771号