概率论复习
熟悉的旁友直接跳过这一章节吧
贝叶斯公式
P(A∣B)=P(B)P(A)×P(B∣A)
其中P(A|B)是指在事件B发生的情况下事件A发生的概率。
在贝叶斯定理中,每个名词都有约定俗成的名称:
- P(A∣B)是已知B发生后A的条件概率,也由于得自B的取值而被称作A的后验概率。
- P(A)是A的先验概率(或边缘概率)。之所以称为"先验"是因为它不考虑任何B方面的因素。
- P(B∣A)是已知A发生后B的条件概率,也由于得自A的取值而被称作B的后验概率。
- P(B)是B的先验概率或边缘概率。
按这些术语,贝叶斯定理可表述为:
后验概率=(似然性∗先验概率)/标准化常量
也就是说,后验概率与先验概率和相似度的乘积成正比。
另外,比例P(B|A)/P(B)也有时被称作标准似然度(standardised likelihood),贝叶斯定理可表述为:
后验概率=标准似然度∗先验概率
全概率公式
P(A)=n∑P(A∣Bn)P(Bn)
简单的理解就是,消去B事件对A事件的影响
最大似然估计
总结起来,最大似然估计的目的就是:利用已知的样本结果,反推最有可能(最大概率)导致这样结果的参数值。
原理:极大似然估计是建立在极大似然原理的基础上的一个统计方法,是概率论在统计学中的应用。极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。通过若干次试验,观察其结果,利用试验结果得到某个参数值能够使样本出现的概率为最大,则称为极大似然估计。
由于样本集中的样本都是独立同分布,可以只考虑一类样本集D,来估计参数向量θ。记已知的样本集为:
D={x1,x2,⋯,xN}
似然函数(linkehood function):联合概率密度p(D∣θ)函数称为相对于{x1,x2,⋯,xN}的θ的似然函数。
l(θ)=p(D∣θ)=p(x1,x2,⋯,xN∣θ)=i=1∏Np(xi∣θ)
如果θ^是参数空间中能使似然函数l(θ)最大的θ值,则θ^应该是“最可能”的参数值,那么θ^就是θ的极大似然估计量。它是样本集的函数,记作:
θ^=d(x1,x2,⋯,xN)=d(D)
极大似然函数:ML估计:求使得出现该组样本的概率最大的θ值:
θ^=argθmaxl(θ)=argθmaxi=1∏Np(xi∣θ)
因为这是个连乘不太好求导,所以经常取个对数
H(θ)=lnl(θ)
θ^=argθmaxH(θ)=argθmaxlnl(θ)=argθmaxi=1∑Nlnp(xi∣θ)
这个时候就到了大家熟悉的概率论书后习题了,全是加法,对θ求导,解出导数为0的时候的
dθdH(θ)=dθdlnl(θ)=0
如果θ不止一个参数,那就求梯度吧,再议再议,有这么一个概念,下面的东西读起来可能不会出人命
KL散度
相对熵(relative entropy)又称为KL散度(Kullback–Leibler divergence,简称KLD),信息散度(information divergence),信息增益(information gain)。
KL散度是两个概率分布P和Q差别的非对称性的度量。 KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
对于离散随机变量,其概率分布P 和 Q的KL散度可按下式定义为
DKL(P∥Q)=−i∑P(i)lnP(i)Q(i)
等价于
DKL(P∥Q)=i∑P(i)lnQ(i)P(i)
即按概率P求得的P和Q的对数商的平均值。KL散度仅当概率P和Q各自总和均为1,且对于任何i皆满足 Q(i)>0及 P(i)>0时,才有定义。式中出现 0ln0的情况,其值按0处理。
对于连续随机变量,其概率分布P和Q可按积分方式定义为
DKL(P∥Q)=∫−∞∞p(x)lnq(x)p(x)dx
emmm,这一段,似乎把公式记住就够用了
自动编码器
自动编码器是是个什么玩意呢
众所周知,图片一般,按像素存的话,very large,处理起起来极其的烧显卡
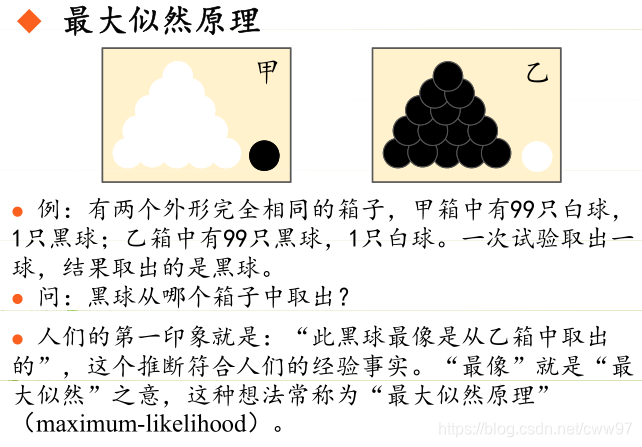
自动编码器的一个idea就是把高维度的数据(i.e.图像),编码到一个低维的隐空间中,使用的方法可能是如图的线性方法或者非线性的方法(i.e.深度全联通网络,卷积神经网络等等),可以简单地把这些方法看做一个函数,输入时图像x输出是隐空间内的编码z,这是一个编码(Encode)的的过程。
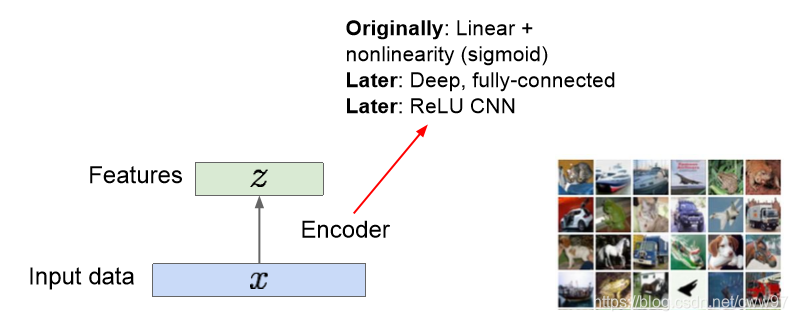
z通常是一个比原图像x尺寸小很多的一个向量,维度减少是因为隐空间里更多的存储了图像中有意义的信息(图像的特征)
那么现在问题来了,如果学习到这样一个学习图像特征的表示的方法呢?训练的特征应当可以用于还原出原始的图片,这就是所谓的“自动编码器”——编码自己
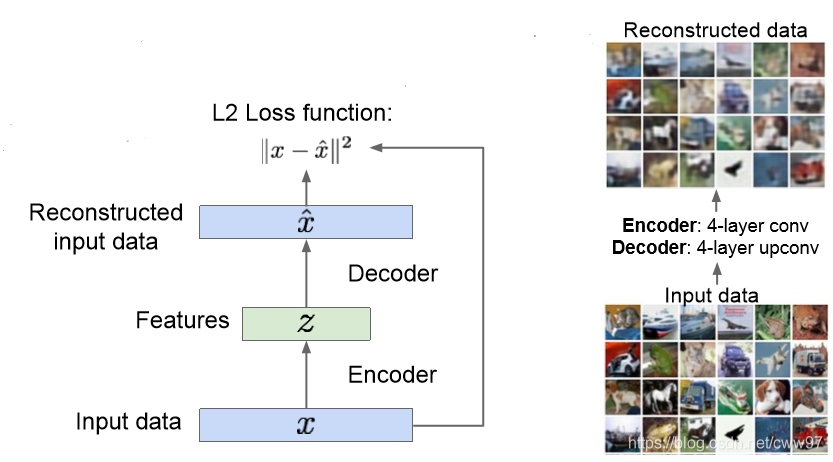
此时,训练这么一个编码器网络和一个解码器网络,x是原图像,z是隐空间中编码的向量, x^解码器还原出的图像。很容易写出的损失函数:
L=∣∣x−x^∣∣2
自动编码器的训练过程主要在这里。训练结束之后,我们可以把解码器网络直接扔掉,没错,直接扔掉,想想看一些图像处理的任务,最简单的,图像分类,直接处理隐空间的图像特征信息是不是比直接处理图像简单很多。玩一些有监督的学习,分类器之类的工作,瞬间感觉舒服了许多是不是。
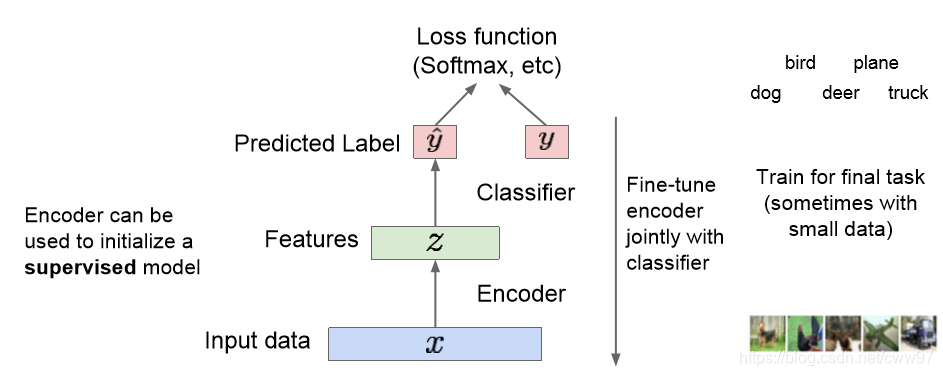
自动编码器可以还原出图像,可以学习到图像的特征信息用于初始化一个监督学习的模型。更进一步,我们能不能使用我们的编码的隐空间的图像的特征信息来生成一些新的本来不存在的图像呢
变分自动编码器
好了,现在我们的想法是想要一个生成模型。假设我们的训练数据 {x(i)}i=1N是从隐空间的分布z中生成的
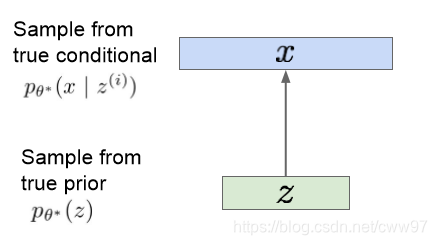
注意上图中 x(i) 是一张图片,z是 隐空间中用于生成 x的变量。对于这样一个生成模型,我们想要估计z的真实分布的参数 θ。该如何表示这个模型呢。
众所周知,万事万物很多东西都服从高斯分布,我们简单的将这个z假装它是个高斯分布(为什么可以这么假设???可能这就是高斯分布牛逼的地方了吧)。条件概率 p(x∣z)是一个比较复杂的,从隐空间生成图片的一个神经网络,θ∗是这个网络的真实参数。
隐空间中的图片 z 服从一个先验分布 pθ∗(z),完美的解码器即为 pθ∗(x∣z(i))。现在的问题是如何训练这个 θ∗。注意这是一个生成模型,我们最终的目标是生成x,那直接求x的最大似然:
pθ(x)=∫pθ(z)pθ(x∣z)dz
这里的pθ(z)是一个简单的高斯分布,pθ(x∣z)是解码器的神经网络,但是无法对所有 的z求积分。故此路不通,尝试使用贝叶斯公式:
pθ(x)=pθ(z∣x)pθ(x∣z)pθ(z)
分子易得,则需要求pθ(z∣x):
pθ(z∣x)=pθ(x∣z)pθ(z)/pθ(x)
我们发现此处再一次出现了原问题pθ(x),这已经是一个死循环了,必须有一些平如的操作才能继续算下去。引入一个额外的编码器 qϕ(z∣x)来估计pθ(z∣x),此时我们有图 \ref{vae_pq}中的两个网络:解码器网络记为qϕ(z∣x),编码器网络记为pθ(z∣x)。
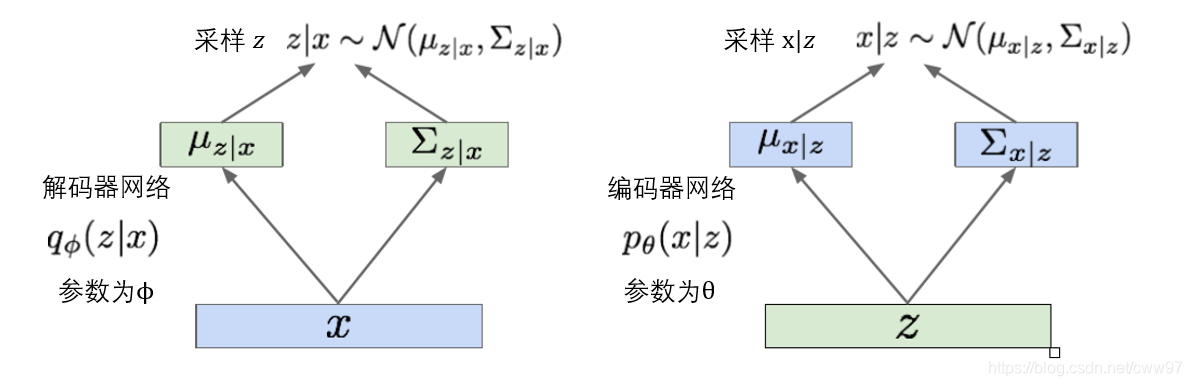
此时对于个数据集X里的一张图片 x(i),我们可以求解log数据似然:
logpθ(x(i))=Ez∼qϕ(z∣x(i))[logpθ(x(i))](pθ(x(i)) 不依赖于 z)=Ez[logpθ(z∣x(i))pθ(x(i)∣z)pθ(z)](贝叶斯公式)=Ez[logpθ(z∣x(i))pθ(x(i)∣z)pθ(z)qϕ(z∣x(i))qϕ(z∣x(i))](乘一个常数)=Ez[logpθ(x(i)∣z)]−Ez[logpθ(z)qϕ(z∣x(i))]+Ez[logpθ(z∣x(i))qϕ(z∣x(i))](log展开)=Ez[logpθ(x(i)∣z)]−DKL(qϕ(z∣x(i))∥pθ(z))+DKL(qϕ(z∣x(i))∥pθ(z∣x(i)))
这里第一项中的pθ(x(i)∣z)由解码器网络提供,DKL(qϕ(z∣x(i))∥pθ(z))则是编码器和z的先验分布(正态分布)的KL散度,最后一项包含pθ(z∣x(i))无法计算,但是我们知道任意的KL散度是非负的。所以我们领损失函数:
L(x(i),θ,ϕ)=Ez[logpθ(x(i)∣z)]−DKL(qϕ(z∣x(i))∥pθ(z))
该式即为数据似然的下界,即:
logpθ(x(i))≥L(x(i),θ,ϕ)
所以我们的优化目标:
θ∗,ϕ∗=argθ,ϕmaxi=1∑NL(x(i),θ,ϕ)
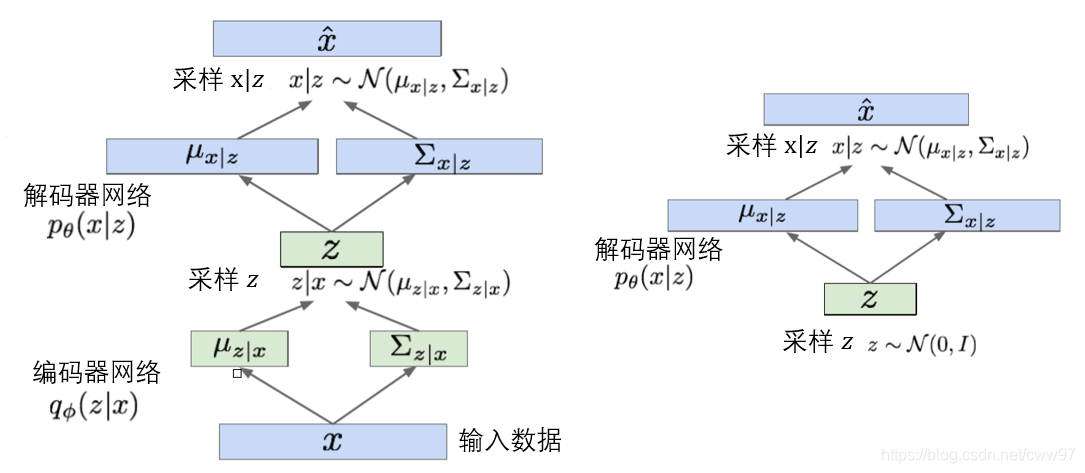
损失函数前一项为解码器,从隐空间中重新构造出了输入图像,后一项使得编码器与先验分布相似。此时我们的VAE的结构如图 \ref{vae_struct}中左图所示。右图展示了训练完成的VAE,VAE本质是一个生成模型,我们的z是服从高斯分布的,而任意高斯分布可以从0-1高斯分布转化而得。所以生成图片的过程等价于从0-1高斯分布中采样,这是VAE实现高效采样的根本原因。
Reference
Appendix
草稿纸,推导过程


 浙公网安备 33010602011771号
浙公网安备 33010602011771号